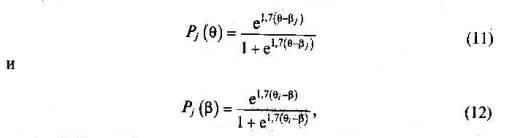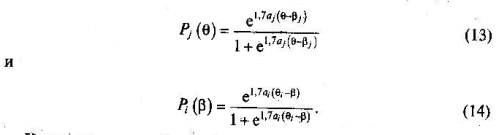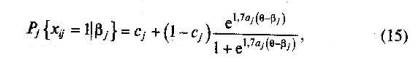|
Лекция 13. Современная теория конструирования тестов.
1. Основные положения современной теории 2. Математические модели современной теории тестов. 3. Оценивание параметров подготовленности учащихся и трудности заданий теста в IRT. 4. Информационные функции тестовых заданий и теста 5. Современные программные средства для разработки педагогических тестов.
1. Основные положения современной теории
Item Response Theory (IRT) и область ее применения. В 80-х гг. XX в в педагогических измерениях получили широкое развитие методы современной теории тестов Item Response Theory, сокращенно IRT [60; 65; 75; 83]. Прямой перевод на русский язык исторически сложившегося названия этой теории ничего не говорит о ее сути, поэтому в русскоязычной литературе широко используется название «теория IRT». В целом IRT предназначена для оценивания латентных параметров испытуемых и заданий тестов на основе математико -статистических моделей измерения и является частью более общей теории латентно-структурного анализа (LSA), хотя каждое из этих направлений имеет свои характерные особенности и свою сферу применения. В частности область использования LSA - социально-психологические исследования, в то время как IRT применяется в основном для конструирования и интерпретации результатов выполнения педагогических тестов. IRT намного эффективнее традиционной теории тестов, поскольку обеспечивает более высокие точность, уровень измерений и качество тестов. Это осуществляется благодаря математико-статистическому аппарату теории, требующему привлечения дорогостоящих программных продуктов, тщательной стратификации выборок испытуемых при разработке тестов и значительным трудозатратам на согласование данных измерения с требованиями математических моделей измерения. Эти трудности разработчикам необходимо учитывать при выборе основополагающей теории конструирования тестов. Латентные параметры и их связь с наблюдаемыми результатами тестирования. Построение теории IRT основано на предположении о существовании функциональной связи между латентными параметрами испытуемых и наблюдаемыми результатами выполнения теста. Первопричиной являются латентные параметры испытуемых, взаимодействие которых с заданиями в процессе тестирования порождает наблюдаемые результаты выполнения теста. На практике всегда ставится обратная задача: по ответам испытуемых на задания теста оценки значения латентного параметра θi, (i = 1, 2, ..., N), определяющие уровень подготовки N испытуемых, и латентного параметра βj (j = 1, 2, ,.., n), равные оценкам трудности n заданий теста. Для решения этой задачи датский математик Г. Раш предложил математическую модель связи между латентными параметрами и наблюдаемыми результатами тестирования, содержащую соотношение между латентными параметрами θ и β в виде разности θ - β при условии, что параметры θ и β оцениваются в одной и той же шкале. В качестве такой единой шкалы Г. Раш ввел интервальную шкалу логитов. Если рассматривать значение параметра θi- как положение i-го испытуемого на шкале логитов, а значение βj — как положение j-го задания на той же шкале, то разность параметров получает интересную геометрическую интерпретацию. Абсолютная величина разности |θi - βj| — это расстояние, на котором находится испытуемый с уровнем подготовки θi от задания с трудностью βj. Если эта разность велика по модулю и отрицательна, то задание бесполезно для измерения уровня подготовленности i-го ученика, поскольку он наверняка не сможет выполнить такое трудное задание верно. Большие положительные значения этой, разности тоже не представляют интереса ни для процесса контроля, ни для обучения i-го испытуемого, поскольку они говорят о том, что задания такой: трудности давно освоены учащимся и он справится с ними успешно при выполнении теста. С точки зрения подхода, предлагаемого в IRT, такие задания неэффективны для оценивания данного значения θ. Наименьшую ошибку измерения обеспечивают задания, трудность которых приблизительно равна уровню подготовленности испытуемого, т.е. задания, подобранные по критерию θ = β.
2. Математические модели современной теории тестов
Условная вероятность правильного выполнения обучаемыми заданий теста как функция одной переменной. В качестве математической модели взаимосвязи между значениями латентных переменных θ, β и наблюдаемыми результатами выполнения теста в IRT выбрана условная вероятность правильного выполнения обучаемыми заданий теста. В частности можно рассматривать условную вероятность Pj правильного выполнения /-м испытуемым с уровнем подготовки θi, различных по трудности заданий теста, считая θi, параметром i-го ученика β — независимой переменной.
Аналогично вводится Рj для обозначения вероятности правильного выполнения i-го задания трудностью βj; различными испытуемыми группы. Здесь θ — независимая переменная, а βj; — параметр, определяющий трудность j-го задания теста:
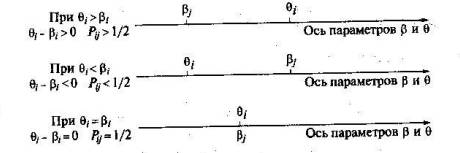
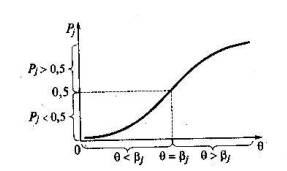
f и φ — символы функциональной зависимости; N — число испытуемых; n — количество заданий в тесте. Если подставить в функцию Pj(θ) значение переменной θ=θi, или в функцию Pi(β) значение β = βj ;, то получится выражение для вероятности Рij значения которой можно охарактеризовать следующим образом: Рij ->1, когда θi- βj, намного больше 0; Рij -> 0, когда θi - βj - намного меньше нуля; Рij =1/2 при θi – βj. Геометрическая интерпретация связи между разностью латентных параметров и вероятностью правильного ответа на задания теста. Связь между значениями разности θi - βj и вероятностью правильного ответа i-го испытуемого на j-е задание теста показана на рис.26. В теории IRT график функции Рj получил название характеристической кривой j-го задания (ICC), а график функции Pi — индивидуальной кривой i-го испытуемого (РСС). При выборе вида функций Pj и Рi, учитываются обстоятельства как эмпирического, так и математического характера. В предположении нормального распределения значений латентных переменных θ и β предлагаются две такие функции. Одна из них, обычно обозначаемая символом ψ(х), относится к семейству логистических кривых, другая — Ф(х) — является интегральной функцией нормированного нормального распределения. Поскольку для одних и тех же значений х ординаты точек графиков функций Ф(х) и ψ (1,7х) отличаются друг от друга незначительно, то в том, что их две, нет ни ошибки, ни противоречия. Наиболее убедительный аргумент в пользу логистической функции связан не с качеством измерений, а с относительной простотой ее аналитического задания, облегчающей оценивание параметров θ и β Поэтому в практических приложениях предпочтение обычно отдают функции ψ (1,7х)
Рис. 26. Соотношение между значениями разности θi – βj и вероятностью правильного ответа
Классы логистических функций. Число параметров, входящих в аналитическое задание функций, является основанием для подразделения семейств логических функций на классы. Среди логистических функций различают: 1) однопараметрическую модель Г. Раша —
гдеθ и β — независимые переменные для первой и второй функций соответственно; 2) двухпараметрическую модель А. Бирнбаума —
Кроме прежних обозначений в формулах (13) и (14) появля ются параметры аi и aj,. Параметр aj - был введен А. Бирнбаумом для характеристики дифференцирующей способности задания при измерении различных значений θ. Параметр ai- указывает на меру структурированности знаний i-го ученика; 3) трехпараметрическую модель А. Бирнбаума
где Cj является третьим параметром модели, характеризующим вероятность правильного ответа на j-е задание в том случае, если этот ответ угадан, а не основан на знаниях В каждой из представленных моделей параметры θ и β выражаются как шкалированные показатели единой для всех моделей шкалы логатов. Введение единой шкалы для элементов двух различных множеств позволяет подобрать оптимальные значения, % дающие возможность измерить искомое θ с минимальной ошибкой измерения. Перевод значений вире общую шкалу логитов с помощью специальных преобразований был предложен Б.Д.Райтом и М. Г.Стоуном [83]. Подробно он рассмотрен в книге М.Б.Челышковой «Теория и практика конструирования педагогических тестов» [60]. Однопараметрическая модель Г.Раша. Аналитическое задание однопараметрической модели Г.Раша представлено формулами (16) и (12). В первом случае вероятность правильного выполнения j-го задания теста является возрастающей функцией от переменной θ. Это свойство функции согласуется с практическим опытом педагога, Естественно ожидать, что чем больше уровень подготовки испытуемого, тем больше вероятность правильного выполнения им j-го задания теста.. На рис. 27 изображена характеристическая кривая j-го задания теста, показывающая взаимосвязь между значениями независимой переменной θ и величиной Pj . Точке перегиба характеристической кривой соответствует значение θ = βj, а Pj- в этой точке равно 0,5.
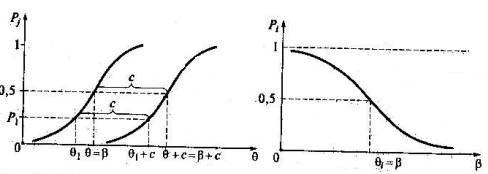
Рис.27. Характеристическая кривая j-го задания теста . Свойство инвариантности оценок параметра испытуемых от трудности заданий теста. Модель Раша обладает интересным свойством, позволяющим на репрезентативной выборке испытуемых реализовать идею инвариантности оценок параметров θ и β, которая не характерна для двух и трех параметрических моделей. Не останавливаясь на математическом доказательстве, можно привести несложную геометрическую интерпретацию свойства инвариантности (см. рис. 28). Пусть испытуемый с уровнем подготовки θ1 ответит на задание j с вероятностью P1. Увеличение трудности j-го задания теста на константу с (с > 0) вызовет смещение характеристической кри ой вправо. C прежней вероятностью на это более трудное задание будет отвечать испытуемый с уровнем подготовки θ1 + с. Так как θ – βj = (θ + с) - (βj + с), то значение вероятности правильного ответа Р1 не изменится, что дает основание для вывода об относительной инвариантности уровня подготовки испытуемых от трудности заданий теста.
Рис. 28. Иллюстрация инвариантности оценок уровня подготовки испытуемых от трудности заданий теста Рис. 29 Индивидуальная кривая i-го испытуемого
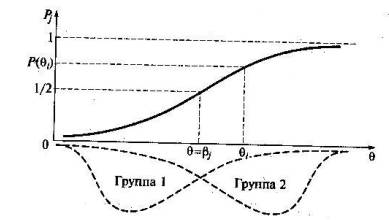
Вероятность правильного выполнения i-м испытуемым различных по трудности заданий Pi является убывающей функцией переменной β. Это означает, что с ростом трудности заданий значения вероятности Pi (β) будут уменьшаться. График функции Рi(β) представлен на рис. 29. В точке перегиба кривой, соответствующей значению независимой переменной θi = β, функция Pi (β) принимает значение Pi = 0,5. В процессе обучения по мере накопления знаний индивидуальная кривая испытуемого смещается вправо. Поскольку вдоль кривой откладываются доли правильных ответов на задания, которые не зависят от характера распределения группы тестируемых учеников, форма характеристической кривой задания и ее положение при построении кривой на выборках в цервой слабой и во второй сильной группах получатся одними и теми же (рис. 30). Конечно, практика свидетельствует о том, что эффект инвариантности наблюдается далеко не всегда, а только в тех случаях, когда реальная статистика — доли правильных ответов учащихся на задания — лежит достаточно близко к теоретической кривой. Причем чем ближе подходят точки распределения долей к кривой. — графику функции Pj тем ярче проявляется инвариантность.
Рис. 30. Иллюстрация инвариантности формы характеристической кривой задания от уровня подготовленности тестируемой выборки
3. Оценивание параметров подготовленности учащихся и трудности заданий теста в ИНГ Начальные оценки параметра испытуемых и параметра трудности заданий теста. Начальные оценки параметра подготовки учащихся в логитах находят по формуле
где θi0 — уровень подготовленности i-го ученика; pi и qi — доли правильных и неправильных ответов соответственно, подсчитанные по матрице наблюдаемых результатов выполнения теста; In — символ натурального логарифма. Начальные оценки параметра трудности заданий β получают по формуле
где p1 и q1 - доли правильных и неправильных ответов на j-е задание теста, соответственно; In — символ натурального логарифма. Как следует из формул для подсчета, оценки параметров вир могут меняться в интервале (-∞, +∞), но практически при θi,- -β < -5 значения Рij близки к нулю. Аналогичная пограничная ситуация наблюдается, когда θi — βj> 5. В этом случае значения вероятности Pij будут почти равны 1. Поэтому значения разностей параметров, выходящие за указанные пределы, не рассматриваются в практике педагогических измерений. Свести оценки логатов подготовленности испытуемых и логитов трудности заданий в единую шкалу позволяют специальные преобразования, выполняемые после завершения подсчетов начальных оценок θ и β. Вслед за преобразованиями оценки каждого из параметров выражаются в интервальной шкале с одним значением среднего и стандартного отклонения. Метод наибольшего правдоподобия. Хотя теория IRT обеспечивает инвариантность оценок параметров θ и β, на практике в силу действия различных случайных факторов свойство инвариантности не выполняется в полной мере. Если объем выборки испытуемых достаточно велик, то можно, ставить вопрос вычислении устойчивых значений параметров θ и β, которые будут наиболее эффективными оценками и могут быть приняты в качестве объективных значений этих параметров. Существуют различные методы вычисления эффективных оценок параметров распределения. Одним из них является метод наибольшего правдоподобия, предложенный Р. Фишером [63] и реализуемый итерационными процедурами с помощью специальных программных продуктов на ПК. Применение Метода наибольшего правдоподобия требует введения предположения о локальной независимости заданий теста, которое означает, что при данном значении 6 вероятность правильного ответа на конкретное задание теста не зависит от результатов выполнения остальных его заданий. Для вычисления эффективных оценок параметров составляется вероятностная модель выполнения заданий теста группой испытуемых, которая называется функцией правдоподобия. Значения параметра θ, при которых функция правдоподобия достигает максимума, принимается в качестве объективных оценок параметра подготовленности испытуемых. Таким же образом вычисляются оценки наибольшего правдоподобия для параметра трудности заданий теста. Согласно теории оценки наибольшего правдоподобия являются наиболее эффективными и могут быть принять за истинные значения латентных переменных θ и β.
4. Информационные функции тестовых заданий и теста
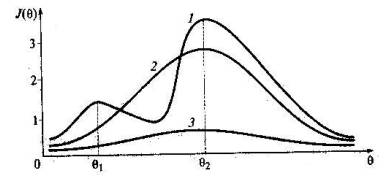
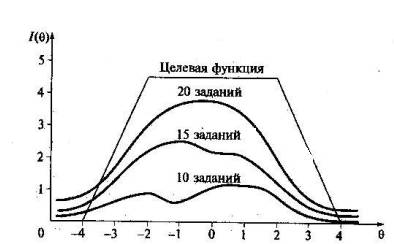
Понятие «информационная функция». В отличие от классической теории тестов, не позволяющей прогнозировать надежность измерений, в IRT можно априорно получать дифференцированные оценки точности, обеспечиваемой j-м заданием теста в различных точках оси θ. Эти оценки основаны на подсчете значений информационной функции, введенной А. Бирнбаумом. По одному из определений, предложенных этим исследователем, количество информации, обеспеченное j-м заданием теста в данной точке θ — это величина, обратно пропорциональная стандартной ошибке измерения данного значения θ с помощью задания j. Соответствие количества информации, получаемой при оценивании параметра θ с помощью задания j, и различных точек оси в отражается с помощью специальной функции, получившей название информационной. Значения этой функции являются своеобразной характеристикой эффективности j-го задания в каждой точке оси латентной переменной θ. Чем больше количество информации, тем лучше, образно говоря, работает задание на рассматриваемом интервале оси θ . Информационная кривая теста. Благодаря свойству аддитивности информация, полученная при измерении данного θ с помощью всего теста, складывается из отдельных значений ординат информационных функций, построенных для каждого задания теста. На рис. 31 приведены графики трех информационных функций, одна из которых (кривая 1) имеет две точки максимума θ1 и θ2, что недопустимо в правильно сконструированном тесте. Кривая 2 на том же рисунке принадлежит менее информативному тесту, проигрывающему в точности измерений тесту, представленному кривой /, при оценке подготовленности учащихся в окрестности точки θ2. Однако у кривой 2 есть явное преимущество по сравнению с кривой 1, поскольку она имеет один четко выраженный максимум, что позволяет отдать ей предпочтение при сравнительном анализе качества первого и второго тестов. Пологая кривая 3 отображает неудачный тест, который является малоинформативным на всем протяжении оси θ. Моделирование теста. В тех случаях, когда есть банк калиброванных заданий, тест можно моделировать с помощью информационных функций, построенных на том участке оси θ, где по предварительным данным (экспресс-диагностика или опыт предварительного контроля учащихся) будут в основном расположены оценки подготовленности испытуемых. За счет специального подбора заданий на основе графика целевой информационной функции теста появляется возможность оптимизировать подбор трудности теста и минимизировать стандартную ошибку измерения на нужном интервале оси θ. В целом процесс моделирования теста, представленный, на рис. 32, включает следующие этапы: - построение целевой информационной кривой теста, обеспечивающей заданную стандартную ошибку измерения в нужном интервале оси θ; -выбор заданий из банка с информационными кривыми, удовлетворительно заполняющими пространство под целевой информационной кривой теста; - сложение ординат информационных кривых тестовых заданий в каждой точке оси латентной переменной в и пошаговое построение информационной кривой получаемого теста; - продолжение процесса выбора заданий до тех пор, пока площадь под целевой кривой не будет заполнена с заданной степенью точности; - проверка абсолютного значения разности между максимальной суммой ординат информационных кривых заданий и планируемым максимумом на целевой кривой в разных точках оси θ.
Рис. 31. Информационные кривые трех тестов
Рис. 32. Информационные кривые моделируемого теста
Имея информационные функции, можно сравнить эффективность различных моделируемых тестов с исходным эталонным без предварительного сбора эмпирических данных. Для этого используют функцию сравнительной эффективности, представляющую собой отношение двух информационных функций: эталонной функции и функции моделируемого теста. Вычисление значений функции сравнительной эффективности позволяет оценить эффект при удалении из теста заданий определенной трудности, при замене заданий средней трудности на легкие или более трудные задания, а также решить ряд других вопросов, возникающих у создателя тестов.
5. Современные программные средства для разработки педагогических тестов Программные средства для конструирования тестов: общая характеристика. Интенсивное развитие программных средств, реализующих алгоритмы IRT, и классической теории для конструирования новых тестов началось в конце 80-х гг. XX в. и продолжается в настоящее время. Программные продукты для конструирования тестов нередко путают с инструментальными средствами для компьютерного тестирования, хотя они имеют разное назначение. Первые создаются для анализа эмпирических данных тестирования в целях коррекции характеристик тестов, обеспечения высокого качества педагогических измерений, калибровки заданий при наполнении банков, шкалирования и выравнивания для построения стандартных шкал по данным педагогических измерений. Вторые выполняют исключительно функцию поддержки при проведении компьютерного тестирования и обеспечивают формирование вариантов тестов, их предъявление, накопление баз данных по результатам тестирования и оценку результатов учащихся для выдачи им тестового балла. При правильном Положении вещей оба блока программных продуктов должны работать совместно, поскольку информацию о результатах тестирования, накапливаемую в инструментальной оболочке, необходимо передавать дальше для совершенствования характеристик теста. Часть разрабатываемых в мире программ для конструирования тестов носит закрытый характер и используется исключительно для собственных нужд, как, например, в ETS. Другая часть попадает на рынок благодаря каталогам и Интернету. Материалы, размещенные в Интернете крупнейшими разработчиками и распространителями программного обеспечения для конструирования тестов, включают описания технологий, перечень возможностей программ, демонстрационные версии и т.д. Виды программных продуктов для конструирования тестов. К числу наиболее интересных программ, созданных мировым лидером в компьютерном тестировании Assessment Systems Corporation (ASC), можно отнести RASCH, RASCAL, Quest, ConQuest, а также XCALIBRE, ASCAL, LOGIMO, MSP, PARELLA и многие другие [91]. Некоторые из разработок корпорации ASC, например, MieroCAT, CAT, позволяют реализовывать адаптивные варьирующие алгоритмы с переменным шагом и осуществлять процессы генерации адаптивных тестов. В настоящий момент наибольший интерес для разработчика и пользователя тестов представляют следующие программы: - AGREE, предназначенная для расчета согласованности оценок в номинальных шкалах данных в случае, когда два и более экспертов классифицируют объекты по некоторым категориям номинальной шкалы; - ASC Item and Test Analysis Package — пакет программ ASC для анализа качества тестов и шкалирования результатов их выполнения. Программы пакета позволяют осуществить простейший анализ качества заданий по классической теории тестов, в том числе и углубленный дистракторный анализ (ITEMAN), получить оценки параметров подготовленности испытуемых и трудности заданий по однопараметрической модели теории IRT (RASCAL), провести калибровку заданий (XCALIBRE), получить данные входного тестирования для эвалюации (Test PreEvaluation), оценить валидность теста (Test Validation), провести автоматизированную оценку результатов выполнения заданий и получить шкалированные баллы учащихся (Test Scoring) и т.д.; - BILOGNEW, позволяющая получить, оценки параметров тестовых заданий на Основе.теории IRT использованием одно-, двух- и трехпараметрических логистических моделей и перейти к наиболее эффективным оценкам параметров по методу максимального подобия с помощью реализации итерационных процессов (только для дихотомических оценок по отдельным заданиям теста); - ConQuest — универсальная программа, включающая различные модели IRT, в том числе для полигамических оценок по заданиям в случае одномерных и многомерных измерений; - FastTESTNEW — 32-bit Windows система для поддержки банка калиброванных тестовых заданий и моделирования различных тестов, поддерживающая режимы бланкового и компьютерного предъявления параллельных вариантов тестов и оценки их качества с помощью моделей IRT для дихотомических данных по заданиям; - FastTEST ProfessionalEW — система для адаптивного тестирования с использованием теории 1RT. Считается наиболее продвинутой системой компьютерного адаптивного тестирования в мире; - 1TEMAN — статистика заданий и тестов с использованием классической теории тестов и данных опросов (по типу Лайкёрта). Наиболее популярный в мире программный продукт для анализа тестов; - MicroCAT — полная оболочка для создания тестов и проведения тестирования (как компьютерного, так и бланкового) и последующего анализа результатов; - PARSCALENEW — предназначена для шкалирования результатов учащихся на основе теории IRT, позволяет проводить анализ качества заданий и построение рейтинговых шкал; - XCALIBRE, позволяющая получить оценки наибольшего правдоподобия на основе алгоритмов ЕМ для небольших выборок испытуемых или коротких тестов для двух- и трехпараметрических моделей IRT.
|