Информационные
системы.
Стандарт
дисциплины.
Информационные
модели
данных:
фактографические,
реляционные,
иерархические,
сетевые.
Последовательность
создания
информационной
модели.
Взаимосвязи
в модели.
Типы моделей
данных.
Проектирование
баз данных.
Концептуальная
модель
предметной
области. Логическая
модель
предметной
области. Определение
взаимосвязи
между
элементами
баз данных.
Первичные и
альтернативные
ключи
атрибутов
данных.
Приведение
модели к требуемому
уровню
нормальной
формы.
Физическое
описание
модели.
Словарь
данных.
Администрирование
баз данных.
Обзор
возможностей
и
особенностей
различных
СБД. Методы
хранения и
доступа к
данным.
Работа с
внешними
данными с
помощью технологии
ODBC (BDE).
Объектно-ориентированное
программирование
в среде баз данных.
Введение
в SQL.
Использование
SQL
для выборки
данных из
таблицы,
создание SQL-
запросов. SQL
сервер.
Использование
технологии
"клиент-сервер".
Разработка
пользовательских
программ в
среде баз
данных.
1.
Введение
в базы данных
Сегодня,
практически любая
задача,
решаемая с
помощью
компьютеров,
насыщена
различного
рода
информацией.
Для
управления
этой
информацией
требуются
хранилища,
средства
манипуляции
и управления
этой
информацией.
Для этой
цели созданы
множество
систем – системы
управления
базами
данных,
предназначенных
для этой
цели. Мощь
современных
баз данных
основывается
на результатах
исследований
и
технологических
разработок,
полученных
на протяжении
нескольких
десятилетий,
и заключена в
специализированных
программных
продуктах,
которые принято
называть системами
управления
базами
данных
(СУБД) (Database
Management System - DBMS),
или просто системами
баз данных (database systems).
Термины базы
данных (БД) и система
управления
базами
данных (СУБД)
чаще всего
употребляются
как относящиеся
к компьютерам.
Понятие БД
можно
применить к
любой
связанной
между собой
по
определенному
признаку
информации,
хранимой и
организованной
особым
образом – как
правило, в виде
таблиц. По
сути, БД – это
некоторое
подобие
электронной
картотеки,
которое
хранится в компьютере
в одном или
нескольких
файлах. При
этом
возникает
потребность
выполнения
следующих
операций:
·
Добавление
информации в
существующие
таблицы
·
Добавление
новых таблиц
·
Изменение
информации в
таблицах
·
Поиск
информации в
БД
·
Удаление
информации
из существующих
таблиц
·
Удаление
таблиц из БД
Информационная
система - это
программный
комплекс,
задачи
которого
состоят в
поддержке
надежного
хранения БД в
компьютере,
выполнения
преобразований
информации и
соответствующих
вычислений,
представлении
пользователям
удобного и
легко
осваиваемого
интерфейса.
Пример.
Система
заказа
билетов.
Банковские
системы.
Бухгалтерская
система.
Любая
подобная система
хранит
большое
количество
данных. Да и
вообще, любой
программный
продукт, который
обслуживает
потребности
бизнес процессов,
создает и
накапливает
огромное количество
информации
(для сведения
размеры типичной
базы данных
достигают
порядка 10-100Мб,
количество
таблиц
порядка 50-100).
В
качестве
примера
приведем
небольшую БД
(Рисунок
1
Пример таблицы
БД
«Стипендия»).
GRANT
|
|
KOD
|
NAME
|
GROUP
|
BALL
|
STIP
|
|
525001
|
Иванов
А.А.
|
525
|
4
|
 500 500
|
|
525002
|
Петров
Н.Н.
|
525
|
2
|
0
|
|
525003
|
Сидоров
М.А.
|
525
|
3
|
300
|
|
525004
|
Кузнецов
О.П.
|
525
|
3.5
|
350
|

Рисунок
1 Пример
таблицы БД
«Стипендия»
Данные о
студентах
заносятся в
таблицу, имеющую
строгую
структуру
данных.
Информация
внутри
таблицы
состоит из полей,
имеющих имя
и тип
хранимых
данных. В
примере это
поля:
·
KOD
– номер
студенческого
билета
·
NAME
– фамилия и
инициалы
студента
·
GROUP
– учебная
группа
·
BALL
– средний
балл
·
STIP
– размер
стипендии
Каждую
строку
таблицы
нужно
рассматривать
как запись,
при этом
информация
заносится в
соответствующие
поля. В тоже
время все записи
состоят из
одинакового
набора полей,
а характер
информации
для каждого
поля носит
одинаковый
характер, но
разные поля
могут иметь
разный тип
данных.
Основное
назначение
БД в первую
очередь – быстрый
доступ к
данным. При
значительном
размере
«бумажной БД»
ручной поиск,
а также
модификация
занимает
значительное
время.
Использование
компьютера
для ведения
БД устраняет
эти недостатки.
Операции над
БД
производятся
быстро, а
сама база
данных может
поместиться на
дискете.
Существуют
специальные
программы
для организации
БД, помещения
информации в
БД и
манипуляции
над данными.
Такие
программы
называются
СУБД.
Основная
особенность
СУБД –
наличие
инструментов
для ввода и
хранения не
только самих
данных, но и
описания их
структуры.
СУБД
относятся к
категории наиболее
сложных
программных
продуктов,
имеющихся на
рынке в
настоящее
время.
СУБД
предлагают
следующие
функциональные
возможности:
1.
Средства
постоянного
хранения
данных. СУБД,
подобно
файловым
системам,
поддерживают
возможность
хранения
чрезвычайно
больших объемов
информации,
которые
существуют
независимо
от каких либо
процессов их
использования.
СУБД, однако,
превосходят
файловые системы
в отношении
гибкости
предоставления
информации,
предлагая
структуры,
обеспечивающие
доступ к
большим
порциям данных.
2.
Интерфейс
программирования.
СУБД
позволяют
пользователю
или прикладной
программе
обращаться к
данным и
изменять их
посредством
команд
развитого
языка
запросов.
Преимущества
СУБД по
сравнению с
файлами
проявляются
в том, что
первые дают
возможность
манипулировать
данными
самыми
разнообразными
способами,
гораздо
более
гибкими,
нежели
обычные операции
чтения и
записи
файлов.
3.
Управление
транзакциями.
СУБД
поддерживают
параллельный
доступ к данным,
т.е.
возможность
единовременного
обращения к
одной и той
же порции
данных со
стороны
нескольких
различных
процессов,
называемых транзакциями
(transactions).
В первую
очередь
транзакции
необходимы для
поддержания
логической
целостности
данных в
многопользовательских
системах. Для
этого СУБД
реализуют
механизмы
обеспечения изолированности
(isolation)
транзакций,
их атомарности
(atomicity) и устойчивости
(durability).
·
изолированность
(isolation)
транзакций -
транзакции
выполняются
независимо
одна от
другой, так
как если бы
они выполнялись
не
параллельно,
а
последовательно.
·
атомарность
(atomicity) -
каждая
транзакция
выполняется
целиком, либо
не
выполняется
вовсе.
·
устойчивости
(durability) –
системы
содержат
средства
надежного сохранения
результатов
выполнения
транзакций и
самовосстановления
после
различного
рода сбоев и
ошибок.
СУБД
обязаны
обеспечивать
реализацию
следующих
требований.
1.
Позволять
пользователям
создавать
новые базы
данных и
определять
их
логические схемы
(schemata)
(логические
структуры
данных) с
помощью некоторого
специализированного
языка, называемого
языком определения
данных (Data Definition Language - DDL).
2.
Предлагать
пользователям
возможности
задания запросов
(queries) и
модификации
данных
средствами
соответствующего
языка
запросов (query language),
или языка
управления
данными (Data Manipulation Language - DML).
3.
Поддерживать
возможность
сохранения
больших
объемов
информации –
до многих
гигабайтов и
более на
протяжении
длительного времени,
предотвращая
возможность
несанкционированного
доступа к
данным и
гарантируя
эффективность
операций их
просмотра и
изменения.
4.
Управлять
единовременным
доступом к
данным со
стороны
многих
пользователей,
исключая
возможность
влияния
действия
одних пользователей
на
результаты,
получаемые другим,
и запрещая
совместное
обращение к данным,
чреватое
порчей.
1.1.
Первые
СУБД
Появление
первых
коммерческих
систем
управления
базами
данных
датируется
концом 1960-х
годов. Непосредственными
предшественниками
таких систем
были
файловые
системы,
удовлетворявшие
только
некоторым из
требований,
перечисленных
выше (см. п.3).
Файловые
системы действительно
пригодны для
хранения
обширных фрагментов
данных в
течение
длительного
времени, но
они не
способны
гарантировать,
что данные,
не
подвергшиеся
резервному
копированию,
не будут
испорчены
или утеряны,
и не
поддерживают
эффективные
инструменты
доступа к элементам
данных,
положение
которых
заранее
неизвестно.
Файловые
системы не
удовлетворяют
и условиям п.2,
т.е. не
предлагают
языка
запросов, подходящего
для
обращения к
данным
внутри файла.
Обеспечиваемая
ими
реализация
требований
п.1,
предполагающих
наличие
возможности
создания
схем данных,
ограничена
способностью
определения
структур
каталогов.
Наконец,
файловые
системы не
удовлетворяют
условиям п.4.
Даже, если
система и не
препятствует
параллельному
доступу со
стороны
нескольких
пользователей
она не в состоянии
предотвратить
ситуации,
когда,
например,
два
пользователя
в один и тот
же момент
времени
пытаются
произвести
изменения в
один файл:
результаты
действий
одного из них
наверняка
будут
утрачены.
К числу
первых
серьезных
приложений
СУБД относились
те, в которых
предполагалось,
что данные
состоят из
большого
числа
элементов
малого объема;
для
обработки
таких
элементов
требовалось
выполнять
множество
элементарных
запросов и
операций
модификаций.
1.1.1. Типичные
примеры БД
того времени
Система
бронирования
авиабилетов.
Система
подобного
типа должна
хранить следующую
информацию:
1.
Сведения
о
резервировании
конкретными
пассажирами
места на
определенный
авиарейс,
включая
информацию о
номере места
и обеденном
меню.
2.
информация
о полетах –
аэропортах
отправления
и назначения
для каждого
рейса, сроках
прибытия
сроках
отправки и
прибытия,
принадлежность
судов к
авиакомпаниям,
их экипажах.
3.
Данными
о ценах на
билеты,
поступивших
заявках и
свободных
местах.
В
типичных
запросах
требуется
выяснить, какие
рейсы из
одного заданного
аэропорта в
другой
близки по
времени
отправления
к указанному
календарному
периоду,
имеются ли
свободные
места на рейс,
определения
рейса и выбор
обеденного
меню. В любой
момент
к данным
могут обращаться
сразу
нескольких
операторов,
система
должно предотвращать
конфликтные
ситуации
связанные,
скажем, с
бронированием
на одно и то же
место. Также
система
должна
предотвращать
потерю
данных, если
система
выйдет из строя.
Банковские
системы.
Жизненно
важное
значение
здесь
является
требование о
том, чтобы ни
при каких
обстоятельствах
единовременное
обращение к
банковскому
счету не приводило
к потере
отдельных
транзакций.
Одновременное
выполнение
двух таких
операций
разными
пользователями
приведет к порче
данных:
SELECT
[№счета],
[сумма] FROM [Счета] WHERE [имя]=’Иванов’
нов_сумма=[сумма]+500
UPDATE
[Счета] SET [сумма] =
нов_сумма
Выход
из ситуации:
сразу после
выборки система
должна
заблокировать
данные от
доступа со
стороны
других
процессов.
Только тогда,
когда данные
разблокируются,
другие пользователи
могут
продолжить
работу.
На
самом деле
все еще
сложнее.
Например, если
деньги сняты
с банкомата,
система
должна сразу
сохранить
информацию о
выполненной
операции,
даже тогда,
когда в этот
момент выключили
свет или
произошел
разрыв соединения
с сервером.
Корпоративные
системы
Хранение
информации –
о продажах и
закупках, об
остатках
счетов
бухгалтерского
учета или
персональных
сведений о
служащих компании.
Получение
информации
об истории закупок,
выплатах
сотрудникам.
Каждое изменение
в реальном
мире должно было
быть
отражено в
базе данных.
Самые
первые СУБД,
во многом
унаследовали
свойства
файловых
систем,
оказывались
способными
представлять
информацию в
том виде, в
каком она
хранилась. В
подобных
системах баз
данных
находили
применение
несколько
моделей описания
структуры
данных – в
основном «иерархическая»
древовидная
и «сетевая»
графовая. В
конце 1960-х
годов последняя
получила
признание и
нашла
отражение в
стандарте CODASYL (Committee on Data Systems and Languages).
Одной
из причин, по
которой
этот стандарт
не нашел
широкого
распространения,
было
отсутствие
поддержки
высокоуровневых
языков. Язык
запросов CODASYL для
перехода от
одного
элемента
данных к другому
предусматривал
просмотр
всех вершин
графа
предоставляющего
элементы и связи
между ними.
Совершенно
очевидно, что
при размере
графа в
несколько
тысяч
элементов,
система
становится абсолютно
непригодной из за
малого
быстродействия.
1.1.1.
Системы
реляционных
баз данных
После
опубликования
в 1970 г.
знаменитой
статьи
Э.Ф.Кодда (E.F.Codd) (A Relational model for large shared
data banks) системы
баз данных
претерпели
существенные
изменения.
Д-р Кодд
предложил
схему представления
данных в виде
таблиц,
называемых отношениями
(relations).
Структуры
таблиц могут
быть очень
сложными, но
это не
снижает
скорости
выполнения
запросов. В
отличие от
ранних баз
данных,
пользователю
не требуется
знать особенности
хранения
информации
на носителе.
Запросы к
такой базе
данных
выражаются
средствами
языка
высокого
уровня,
позволяющего
повысить
эффективность
программиста.
Каждый
столбец
отношения
озаглавлен атрибутом
(attribute),
описывающим
природу
элементов
столбца. Строки
данных
образуют кортежи
(tuples).
SELECT NAME FROM GRANT
SELECT NAME, GROUP WHERE STIP=0
До 1990-х
годов
системы
реляционных
СУБД занимали
главенствующее
положение.
Однако
технологии
постоянно
развивались,
появлялись и
появляются
новые продукты,
технологические
решения,
научные исследования.
Далее мы
увидим
тенденции развития
систем.
1.1.2.
Уменьшение
и
удешевление
систем
Изначально
СУБД
представляли
собой крупные
и дорогие
программные
комплексы,
ориентированные
на
использование
больших
компьютеров.
Большой
размер
компьютеров
– самое главное
требование
для систем,
работающих с
гигабайтами
информации.
Сегодня
персональные
компьютеры
могут
хранить
огромные
массивы
данных,
обладают
высоким
быстродействием,
поэтому
технологии
СУБД
доступны
любому пользователю.
Как правило,
это
реляционные
СУБД. В
настоящее
время
некоторые
компоненты СУБД
интегрированы
в ОС. В
ближайшее
время интеграция
ОС и СУБД
будет еще
более сильной.
Например, в
ближайшее
время (к 2006г, Longhorn) Microsoft
планирует
встроить SQL Server в свою ОС.
1.1.3.
Тенденции
роста систем
Гигабайт
– это далеко
не самый
большой объем
данных.
Размеры
корпоративных
баз данных
зачастую
может
исчисляться
сотнями гигабайт.
Системы
розничных
продаж
фиксирующих
каждую операцию,
нередко
могут
достигать
многих гигабайт,
и даже
терабайт (1
терабайт = 1000
гигабайт = 10^12
байт) данных.
Базы
данных могут
хранить не
только простые
типы данных –
числа,
символьные
типы, но и
любые
бинарные
данные. Это
позволяет
накапливать
в БД графические
изображения,
аудио-,
видеозаписи,
чрезвычайно
большие
фрагменты
данных других
типов. Базы
данных
содержащих
такую информацию
могут
охватывать
петабайты данных
(1 петабайт = 1000
терабайт = 10^15
байт).
Задача
обслуживания
таких
огромных
массивов
требует
неординарных
технологических
решений. Базы
данных даже
относительно
скромных
размеров
хранят на
дисковых массивах,
называемых вторичными
устройствами
хранения (secondary storage devices)
– в отличие
от оперативной
памяти (main memory),
которая
служит
первичным
хранилищем
информации.
СУБД имеют
способность
к длительному
хранению
информации
на дисковых
устройствах
и загрузке
данных в
оперативную память
по мере
надобности.
Третичные
устройства
хранения
Для функционирования
самых
крупных баз
данных, возможностей,
предлагаемых
обычными
дисковыми
массивами
уже не
достаточно.
Поэтому
разрабатываются
различные
типы третичных
устройств
хранения (tertiary storage devices)
данных. Время
доступа в
таких
системах, как
правило,
составляет
десятки
секунд.
Третичные
устройства
состоят из:
·
Устройство
чтения
данных
·
Манипулятор
·
Массив
носителей
(стеллаж), как
правило, CD или DVD
дисков
Носитель
с помощью
манипулятора
перемещается
и
погружается
в устройство
чтения данных.
Далее информация
с носителя
кэшируется
во вторичных
или
первичных
устройствах
хранения.
Параллельные
вычисления
СУБД
обрабатывающие
чрезвычайные
объемы
данных
нуждаются в
решениях,
позволяющих
повысить
скорость
вычислений.
Один из подходов
– повышение
эффективности
алгоритмов
обработки.
Например,
использование
структур
индексов (indexes).
Другой
способ –
обработать
больше
данных за
единицу
времени
предполагает
обращение к
средствам
распараллеливания
вычислений.
Параллелизм
вычислений
можно реализовать
несколькими
способами.
Чтение с
дисков
сравнительно
медленная операция
(порядка
нескольких
мегабайт в секунду).
Ее можно
увеличить,
используя
множество
дисковых
устройств с
параллельным
доступом.
Такие диски
могут быть
частью специально
спроектированной
параллельной
машиной, либо
компонентами
распределенной
системы
состоящих из
нескольких
машин, объединенных
высокоскоростными
каналами
связи (как
правило,
оптическими).
Способность
системы
перемещать и
хранить
большие
объемы
данных еще не
позволяет гарантировать
быстрый
доступ к
данным.
Независимо
от
аппаратных средств,
необходимы
реализации
алгоритмов,
позволяющих
дробить
запросы на
части, чтобы
позволить
параллельным
компьютерам
использовать
все
имеющиеся
ресурсы.
1.1.4.
Системы
«клиент/сервер»
и
многоуровневые
архитектуры
Огромный
пласт
современного
программного
обеспечения
поддерживает
архитектуру клиент/сервер
(client/server). В
соответствии
с этой
архитектурой
запросы,
формируемые
одним
процессом
(клиентом) отсылаются
другому
процессу
(серверу). Процессы
могут
выполняться как
на одном
компьютере,
так и на различных.
СУБД в этом
смысле – не
исключение.
Обычной
практикой
является
разделение
функций СУБД
между
процессом
сервера и
одним или несколькими
клиентскими
процессами,
ответственных
за интерфейс
пользователя.
Простейший
вариант
архитектуры
«клиент/сервер»
предполагает,
что СУБД
целиком
представляет
собой сервер,
за
исключением
интерфейсов запросов,
которые
взаимодействуют
с пользователем
и отсылают
запросы и
другие команды
на сервер.
Например, в
реляционных
БД для этого
используется
язык SQL.
Трехуровневая
архитектура
предполагает
наличие еще
одного звена
– сервера
приложений (application server).
1.1.5.
Данные
мультимедиа
Специальные
механизмы
для поиска в
мультимедийной
базе данных.
Объектно-ориентированные
БД.
Доставка
результатов
запросов.
Результаты
запросов могут
возвращать
десятки
гигабайт
информации.
Чтобы не
делать
лишнюю
работу,
система должна
уметь
показать
описания
найденных фрагментов
и дать
возможность
выбрать режим
загрузки
данных
(загрузка
гигабайтов данных
может
приостановить
выполнение
других
запросов).
1.1.6.
Интеграция
информации
В
различных
подразделениях
крупных компаний
могут
использоваться
различные
базы данных.
Каждое
независимое
подразделение
вправе
использовать
те БД,
которые посчитают
нужными. В
результате, в
пределах
одной
компании, для
описания одних
и тех же
предметов
реального
мира могут использоваться
разные
структуры
данных, разные
наименования
для одной и
той же вещи,
либо один
термин для
обозначения
нескольких
вещей.
Строгую
централизацию
БД проводить
не всегда
приемлемо.
Специализированные
разработки
слишком
дорого
переделывать;
при
укрупнении
компаний в
распоряжение
компании
поступают
сторонние
базы данных. Исходя из
этих и других
причин унаследованные
базы данных
не могут (и
не должны)
непосредственно
заменяться
единой
центральной
базой данных
компании.
Более
разумно
поверх существующих
решений
построить
новую информационную
структуру,
способную
представить
информацию
всех
подразделений
в удобном
виде.
Одно из
популярных
решений
такой задачи
связано с
использованием
технологии хранилищ
данных (data warehouses),
которые
предполагают
копирование
информации
из
унаследованных
БД с
соответствующей
трансляцией
и
последующим
сохранением
в
центральной
БД. После
внесения
изменений в
унаследованной
базе данных необходимые
исправления
вносятся и в
содержимое
хранилища,
хотя не
обязательно
автоматически
и немедленно.
Репликация
данных
обычно
производится
ночью, когда
нагрузка на
базы данных
наиболее
низка.
Унаследованные
базы данных
продолжают выполнять
свои обычные
функции, а
новые, такие
как
публикация данных на Web, или
построение
сводных
отчетов
возлагаются
на хранилище
данных.
Хранилища
данных открывают
перспективы
применения
технологии
«разработки»
данных (data mining) – поиска
аномалий,
необычных
образцов информации
и
использования
их для
оптимизации
бизнес
процессов.
1.2.
Обзор
структуры
СУБД
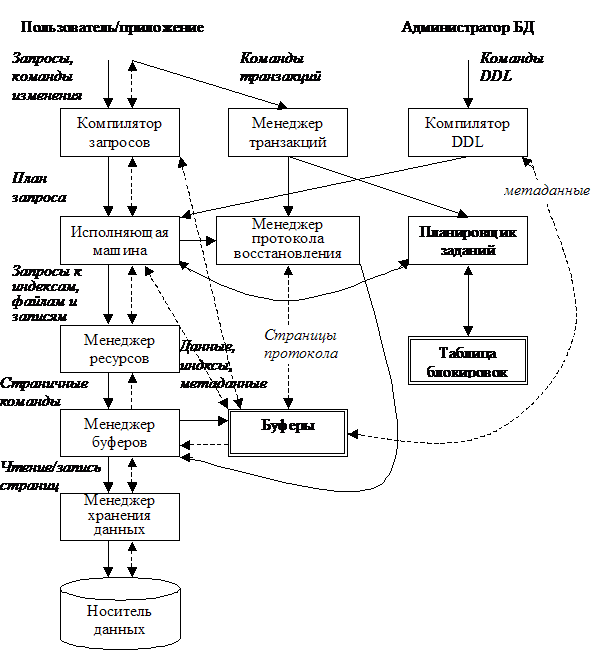
Рисунок
2
компоненты
системы
управления
базами данных
Непрерывные
линии –
команды,
пунктирные – потоки
данных.
Прямоугольники
– компоненты
системы.
Прямоугольники
с двойной
рамкой – структуры
данных
образованные
в памяти.
Два
источника
команд:
·
Рядовые
пользователи
и прикладные
программы,
запрашивающие
или
изменяющие
данные
·
Администратор
базы данных
(database administrator,
DBA) –
лицо или
группа лиц,
ответственных
за поддержку
и развитие
структуры,
или схемы базы
данных.
1.2.1.
Команды
определения
данных
Язык DDL (Data Definition Language – язык
определения
метаданных) ->
Компилятор DDL ->
Исполняющая
машина изменяет
метаданные.
1.2.2.
Обработка
запросов
Язык
управления
данными (Data Manipulation
language - DML),
язык
запросов (query language). SQL –
самый
распространенный.
Получение
ответа на
запрос
Компиляция
-> план
запроса (query plan) ->
запросы на
выборку
данных менеджеру
ресурсов,
который
осведомлен о
размещении
файлов данных,
таблиц,
индексов.
Запросы на
получение
данных
преобразуются
в адреса
страниц ->
менеджер
буферов.
Единица
обмена с
диском –
«дисковый
блок» или
страница. –>
Менеджер
хранения.
Инструкции ОС
или
непосредственно
контролера.
Обработка
транзакций
Запросы
группируются
в транзакции
– процессы,
которые
должны
выполняться атомарно
(atomically) и изолированно
(in isolation)
друг от
друга. Часто
– один запрос
– отдельная
транзакция.
Устойчивость
(durability).
Процессор
транзакций =
планировщик
заданий (scheduler) +
менеджер
протоколирования
и восстановления
(logging and recovery manager).
1.2.3.
Менеджер
буферов и
хранения
данных
Кластеры
4К или 16К –>
страничные
блоки в оперативной
памяти.
Данные:
1.
Данные
2.
Метаданные
3.
Статистика
4.
индексы
1.2.4.
обработка
транзакций
команды
транзакций
определяются
логикой
работы
приложения
протоколирование
управление
параллельными
заданиями.
Признаки
блокировок
ресурсов,
которые
запрещают
обращаться к
заблокированным
ресурсам.
разрешение
взаимоблокировок
(deadlock resolution)
ACID:
свойства
транзакций
A – atomicity (Атомарность)
I
– isolation
(изолированность)
D – durability (устойчивость)
С – consistency
(согласованность)
1.2.5.
процессор
запросов (query processor)
Компилятор
запросов
·
Синтаксический
анализ (query parser)
·
Препроцессор
(query preprocessor)
– проверка на
существование
объектов
·
Оптимизатор (query optimizer). Статистика
и метаданные.
Исполняющая
машина
2.
Модель
данных
«сущность–связь»
Процесс
проектирования
баз данных -
анализ того,
какого рода
информация должна в
ней
представлена
и каковы
взаимосвязи
между
элементами
информации.
Структура
или схема (schema)
определяется
средствами
языков или
систем
обозначений
пригодных
для описания
проектов. По
завершению
уточнений и
согласований
проект
преобразовывается
в форму, которая
может быть
воспринята
СУБД – инструкции
языка DDL.
В
настоящее
время
существует
несколько подходов.
Самый
распространенный
и традиционный
подход –
модель «сущность-связь»
(entity-relationship).
Графическая
модель.
Модель
"сущность-связь"
была предложена
в 1976 г. Питером
Пин-Шэн Ченом
Разработка
БД
начинается с ER-моделирования
либо некой
объектной
модели, с
последующей
трансляцией
в реляционную
модель,
подлежащей
физической
реализации.
Физическая
реализация –
реляционная
модель. Большинство
коммерческих
БД –
реляционные.
Данные в виде
таблиц.
ODL
(Object Definition Language
– язык
определения
объектов) -
стандарт
средств
описания
объектно-ориентированных
БД. Сочетаясь
с
реляционной моделью
образуют
объектно-реляционную
модель (object-relational model).
Существует
концепция «полуструктурированных»
данных (semistructured data).
Эта модель
предоставляет
неограниченную
свободу
выбора
структуры, в
которую может
быть
облечена
информация.
Язык XML
позволяет
иерархически
структурировать
данные –
практическое
воплощение
«полуструктурированных»
данных.
·
Процесс
проектирования
баз данных
·
Изучение
понятий и
описаний
информации подлежащей
моделированию.
На этом этапе
строится
концептуальная
модель
предметной
области.
·
Отображение
концептуальной
модели в
рамках ER-модели.
Логическая
модель
описывает
связи между
элементами.
·
Преобразование
ER-модели
в
реляционную
схему.
·
Модель
на языке
определения
данных конкретной
СУБД.
2.1.
Элементы
ER-модели
ER-модель
отображается
графически, в
виде диаграммы
сущностей и
связей (entity-relationship diagram)
состоящих из:
·
Множеств
сущностей
·
Атрибутов
·
Связей
Любой
фрагмент
предметной
области
может быть
представлен
как множество
сущностей,
между
которыми
существует
некоторое множество
связей
2.1.1.
Множества
сущностей
Сущность
(entity) –
абстрактный
объект
определенного
вида. Набор
однородных
объектов
представляет
собой
множество
сущностей (entity set).
Понятие
сущности
обладает
сходством с
понятием
объект (object), а
множества с
классом
объекта.
Отличие в том,
что
отсутствуют
описания
методов.
Сущность
это объект,
который
может быть идентифицирован
неким
способом,
отличающим
его от других
объектов
множества,
т.е. можно
выделить
признак или
ряд
признаков
уникальных в
пределах
множества.
Отсюда определяется
ключ
сущности -
группа
атрибутов.
Другими
словами: ключ
сущности -
это один, или
несколько
атрибутов,
уникально
определяющих
данную
сущность.
Иногда
сущность –
конкретный
экземпляр объекта,
иногда –
абстрактный
экземпляр в зависимости
от контекста.
Графически
сущность
изображается
в виде
прямоугольника.
Пример.
БД
кинофильмов
(актеров,
студий т.п.).
Кинофильм
– сущность.
Коллекция
фильмов – множество
сущностей.
По
аналогии –
актеры
сущности, но
другого вида.
Киностудия
– сущность
третьего
вида, перечень
киностудий
образует
множество
сущностей.
2.1.2.
Атрибуты
Множеству
сущностей
отвечает
набор атрибутов
(attributes),
являющихся
свойствами
множества
сущностей.
Например,
множеству
«кинофильмы»
могут быть
поставлены в
соответствие
такие атрибуты
как
«название»,
«продолжительность».
Атрибут
является
атомарным
типом. В
других
версиях
атрибут
может представлять
собой
структуру (struct) или
массив
данных.
2.1.3.
связи
Связь - это
графически
изображаемая
ассоциация,
устанавливаемая
между двумя
или большим
числом
сущностей.
Наиболее
распространены
бинарные
связи, соединяющие
два
множества
сущностей. ER
модель
допускает
связи
охватывающие
произвольное
количество
сущностей.
2.1.4.
Диаграммы
сущностей и
связей
Диаграмма
сущностей (entity-relationship diagram) и
связей это
графическое
представление
множеств сущностей,
их атрибутов
и связей.
Элементы
этих видов
описываются
вершинами
графа, и для
задания
принадлежности
элемента к
определенному
виду
используется
специальная
геометрическая
фигура.
·
Прямоугольник
– множества
сущностей
·
Овал –
для атрибутов
·
Ромб –
для связей
Ребра
графа
соединяют
множества
сущностей с
атрибутами и
служат для
представления
связей между
множествами
сущностей.
Пример:
рассмотрим
три
множества
сущностей: Movies
(«кинофильмы»),
Stars
(«актеры») и Studios
(«киностудии»).
Множество
«Фильмы»
обладает
четырьмя атрибутами:
«название»,
«год
производства»,
«продолжительность»,
«жанр»
Два
других
множества
сущностей
содержат по
паре
однотипных
атрибутов –
«имя» или «название»
и «адрес».
Две связи:
1.
«актеры
участники» -
это связь, соединяющая
каждую
сущность –
«кинофильм»
с сущностями
«актерами»,
принимавшими
участие в
съемках
фильма.
2.
связь
«владелец»
соединяет
каждую сущность
«кинофильм»
с сущностью
«студией», выпустившей
фильм и
владеющей
правами на него.
Стрелка указывает
что фильм
является
собственностью
одной и
только одной
студии.
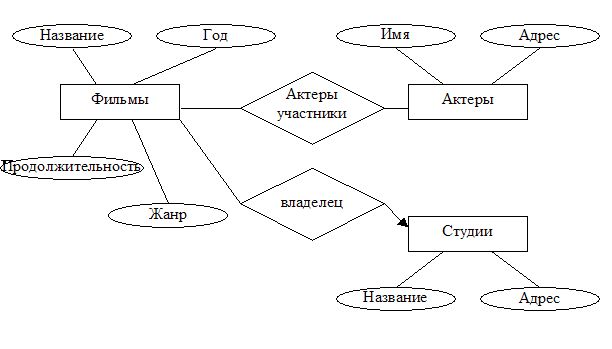
Рисунок
3
Диаграмма
сущностей и
связей для
базы данных о
кинофильмах
2.1.5.
Экземпляры
ER-диаграммы
ER-диаграммы
представляют
собой
инструмент
описания схем
(schemata)
или структур
баз данных.
Базу данных,
соответствующую
определенной
ER-диаграмме
и содержащую
конкретный
набор данных,
называют экземпляром
базы данных.
Каждому
множеству
сущностей в
экземпляре
базы данных
отвечает
некоторый
частный
набор сущностей,
а каждая из
таких
сущностей –
определенными
значениями
атрибутов.
Схема это метаданные,
а любые
метаданные
всегда носят
абстрактный
характер.
Однако
представление
о том, что
данные будто
бы реально
существуют,
помогает на
начальной
стадии проектирования
– пока
структуры
данных не
приобретут
физическую
форму.
Экземпляр
базы данных
включает
определенные
экземпляры
связей,
описываемых
диаграммой.
Связи R, которая
соединяет n
множеств E1, E2, E3,…,En,
соответствует
экземпляр
состоящий из
конечного
множества
списков (e1,e2,e3,…,en), где
каждый
элемент ei,
выбран из
числа
сущностей,
присутствующих
в текущем
экземпляре
множества
сущностей Ei.
Экземпляр
связи
«актеры
участники»
можно легко
описать с
помощью
таблицы из
пар данных:
|
Операция
Ы
|
Никулин
|
|
Бриллиантовая
рука
|
Миронов
|
|
Бриллиантовая
рука
|
Папанов
|
Члены
множества
данных связи
– это строки таблицы.
Например
(«Операция
Ы»,
«Никулин»)
это кортеж
множества
данных для
конкретного
экземпляра
связи
«актеры
участники».
2.1.6.
Множественность
бинарных
связей
Бинарная
связь (binary relationship) в общем
случае
способна
соединить
любой член
одной
сущности с
любым членом
другого множества
сущностей.
Однако
весьма распространены
ситуации,
когда
свойство
множественности
связи каким
либо образом
ограничивается.
Рассмотрим
связь R, которая
соединяет
два
множества
сущностей E и F. Тогда
возможны
следующие
ситуации:
·
Если
каждый член
множества E
посредством
связи R может
быть
соединен не
более чес
одним членом F,
принято
говорить, что
R
представляет
собой связь «многие
к одному» (many-one relationship),
направленную
от E
к F. В
этом случае
каждая
сущность F
допускает
соединение
со многими
членами E. Возможна
и обратная
ситуация –
связь «многие
к одному» (many-one relationship),
направленную
от F
к E,
или, что то
же самое,
связь «один
ко многим» (one-many relationship)
направленная
от E
к F
·
Если
связь R в обоих
направлениях
от E
к F и
от F
к E,
относится к
типу «многие
к одному»,
говорят, что R –
это связь
типа «один к
одному» (one-one relationship). В этом
случае каждый
элемент
одного
множества
сущностей
допускает
соединение
не более чем
с одним
элементом
другого
множества
сущностей.
·
Если
связь R ни в одном
из
направлений
– ни от E к F
ни от F
к E –
не относится
к типу
«многие к
одному», то имеет
место связь
типа «многие
ко многим» (many-many relationship).

Рисунок
4
связь типа
«один к
одному»
Стрелка
означает, что
в связи
участвует «не
более чем
один»
элемент
множества
сущностей, на
которое она
указывает.
Связь «один
к одному»
является
частным
случаем связи
«один ко
многим»,
которая в
свою очередь
является
частным
случаем
связи «многие
ко многим».
Структура
данных
способная описать
связь
«многие к
одному»
подходит для
описания
связи «один к
одному», но
непригодна
для описания
«многие ко
многим».
2.1.7.
Многосторонние
связи
ER-модель
способна
отражать
связи,
охватывающие
более двух
множеств
сущностей. В
реальных
ситуациях
тернарные
связи (ternary relationship)
соединяющие
три
множества,
или связи,
представляющие
взаимоотношение
еще большего
количества
сущностей,
довольно
редки, но
иногда они
все-таки находят
применение,
помогая
воссоздать
настоящее
положение
вещей.
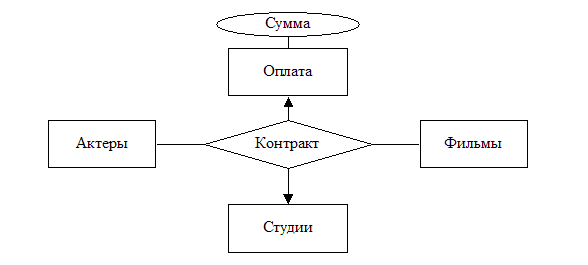
Пример (Рисунок
5
Тернарная
связь)
Связь
отражает
факт
заключения
контракта
между киностудией
и актером,
обязующимся
принять участие
в съемках
конкретного
фильма.
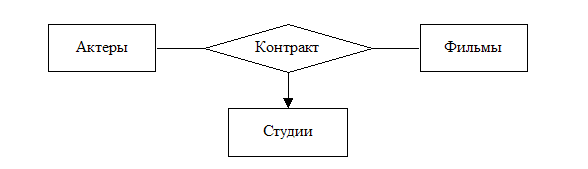
Рисунок 5
Тернарная
связь
Такую
связь можно
представить
в виде множества
кортежей,
компонентами
которых являются
сущности из
множеств,
соединяемых
этой связью.
Таким образом,
связь
«контракт»
может быть
описана
набором
кортежей
вида:
(«Студия»,
«Актер»,
«Фильм»)
2.1.8.
Связи и
роли
Вполне
вероятна
ситуация,
когда одно и
то же
множество
сущностей
упоминается
в контексте
единственной
связи
многократно.
Если это так,
то в ER
диаграмме
рисуется
столько
линий, сколько
требуется.
Каждая линия,
направленная
к множеству
сущностей,
представляет
отдельную
роль, в
которой
сущность
выступает в
конкретном
случае. Линии
сопровождают
текстовыми
метками,
описывающими
роли.
Пример (Рисунок
6 Связь
и ее роли)
Связь
подразумевает,
что исходный
фильм может
иметь
несколько
продолжений,
но продолжение
может иметь
только один
исходный фильм.

Рисунок 6 Связь и
ее роли
2.1.9.
Связи и
атрибуты
Подчас
бывает
удобно
ассоциировать
атрибут со
связью, а не с
некоторым
множеством сущностей,
охватываемых
этой связью.
Пусть на
диаграмме (Рисунок
5
Тернарная
связь) нам
требуется отразить
сумму
контракта
актера. Мы
не вправе
связывать
атрибут ни с
множеством
сущностей
«актеров»
(т.к. актер
может иметь
несколько
контрактов),
ни с
множеством
сущностей
«киностудии»
(т.к. студии
могут оплачивать
по разному
работу
различных актеров).
Из подобных
соображений
нельзя
атрибут «сумма
контракта»
связывать с
множеством
сущностей
«кинофильмы».
Однако
вполне уместно
ассоциировать
атрибут
«сумма
контракта» с
кортежем
(«актер»,
«кинофильм»,
«студия») из
множества
данных
соответствующих
связи «контракт»
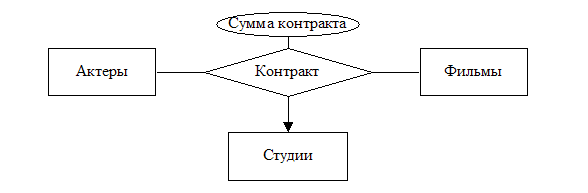
Рисунок
7
связь с
атрибутом
Однако,
злоупотреблять
возможностью
размещения
атрибутов на
связях не
следует. В
качестве
альтернативы
можно
предложить
ввести в диаграмму
еще одно
множество
сущностей с тем
же атрибутом,
соединить
это
множество со
связью и
удалить
атрибут
связи.
Рисунок
8
Передача
атрибута
связи
множеству
сущностей
2.1.10.
Преобразование
многосторонних
связей в бинарные
Существуют
такие модели
представления
данных в
которых
число
сущностей
охватываемых
связью
ограничивают
до двух, т.е.
предполагают
наличие
только
бинарных
связей. ER модели
такие
ограничения
не присущи,
но тем не
менее бывает
необходимо
перейти от связи
охватывающей
более двух сущностей
к набору
бинарных
связей. С
этой целью
вводится
новое
множество
сущностей, элементы
которого
являются
кортежами множества
данных для
рассматриваемой
связи. Такое
множество
сущностей
(вводимое)
называется соединяющим
множеством
сущностей.
Затем в диаграмму
вводятся
связи типа
многие к одному,
сплачивающие
соединяющее
множество сущностей
с каждым из
множеств
сущностей участвующих
в связи.
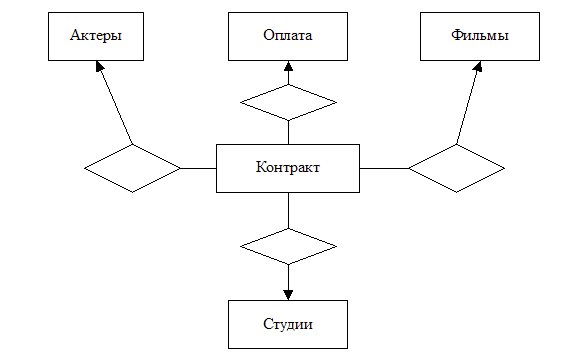
Рисунок
9
замена
многосторонней
связи
соединяющим
множеством
сущностей и
набором
бинарных
связей
2.1.11.
Подклассы
в ER
модели
Нередки
случаи, когда
во множестве
сущностей
можно
выделить
группу
сущностей
обладающих
специальными
свойствами,
не присущими
остальным
членам
множества. В
таких случаях
нужно
создавать
подклассы (subclasses)
которые
обладают
собственными
наборами атрибутов
или связей.
Для
соединения
производного
класса с
базовым
используются
связи
называемые isa (от «is a» -
«есть»).
Связь isa обладает
особым
смыслом,
поэтому ее
изображают с
помощью
специального
знака –
треугольника.
Одна из
сторон соединяется
с подклассом,
а
противоположная
вершина с
базовым
классом.
Такая связь
относится к
типу «один к
одному», но
стрелки на линиях
не ставятся.
2.2.
Принципы
проектирования
2.2.1.
Достоверность
Модель
данных
должна
достоверно
представлять
информацию.
Множества
сущностей и
их атрибуты
должны
соответствовать
реальным
требованиям
и иметь свои
вещественные
аналоги.
2.2.2.
Отсутствие
избыточности
Атрибуты сущностей
отражающие
одну и туже
информацию
не должны
дублироваться.
2.2.3.
Простота
В проект
необходимо
включать те
данные, которые
необходимы
для решения
поставленной
задачи.
2.2.4.
Выбор
подходящих
связей
Множества
сущностей
могут быть
соединены
разнообразными
способами.
Включение в проект
первых
попавшихся
связей может
привести к
избыточности
схемы, когда
одни и те же
отношения
выражаются разными
цепочками
соединений.
2.2.5.
Использование
элементов
адекватных
типов
При
выборе типа
элемента
модели
всегда есть
альтернатива
выбора –
атрибут,
сущность или
связь.
Атрибут
всегда
реализовать
гораздо
проще, чем скажем
связь. Однако
любые
крайности
всегда
вредны и
могут
привести,
например, к
дублированию
информации.
2.3.
Моделирование
ограничений
До сих пор
мы
рассматривали
моделирование
с помощью
множеств
сущностей,
связей и атрибутов.
Однако
существуют
аспекты, моделировать
которые с
помощью этих
средств невозможно.
Дополнительная
информация
об объектах
реального
мира может
быть облечена
в форму
определенных
ограничений (constraints),
которые
никак не
связаны со
структурными
и «типовыми»
ограничениями.
2.3.1.
Классификация
ограничений
Следующий
перечень
наиболее
распространенных
ограничений.
1.
Ключ (key) –
атрибут или
подмножество
атрибутов
уникальным
образом
определяющие
конкретную
сущность в
составе
множества.
Никакие две
сущности в
пределах
данного
множества не
могут иметь одинаковый
ключ.
2.
Ограничение
уникальности
(single-value constraint)
определенное
значение в
некотором
контексте
должно быть
уникальным.
Ключи это основной
поставщик
уникальности.
Есть и другие
источники
уникальности
– например
связи
«многие к
одному»
3.
Ограничение
ссылочной
целостности (referential integrity constraint)
– некоторое
значение, на
которое
ссылается
другой
объект
должно
существовать
в базе
данных.
4.
Ограничение
домена (domain constraint) –
значение
атрибута
должно
выбираться
из некоторого
конечного
множества
значений или
принадлежать
определенному
диапазону
значений.
5.
Ограничение
общего вида (general constraint)
произвольное
требование
которое
должно быть
зафиксировано
в базе
данных.
Ограничения
играют
важную роль в
моделировании
данных. Например
ключи
позволяют
однозначно
идентифицировать
объекты
реального
мира.
2.3.2.
Ключи и ER
моделирование
Говоря
строго ключ
для
множества
сущностей E –
это
множество K
состоящее из
одного или
нескольких
атрибутов
множества E,
такое, что
для любых
двух
различных
сущностей e1 и e2
значения
атрибутов,
составляющие
множество K
различны.
Важные
положения:
·
Каждое
множество
сущностей
должно обладать
ключом.
Только в этом
случае мы
можем гарантировать
достоверность
информации.
·
Ключ
может
состоять
более чем из
одного атрибута
·
Для каждого
множества
сущностей
допускается
наличие
нескольких
ключей
·
Если
множество
сущностей
вовлечено в
иерархию
связей isa, то
корневое
множество
сущностей
должно обладать
всеми
атрибутами
необходимыми
для
формирования
ключа.
В
диаграммах
ключевые
атрибуты
выделяют
подчеркиванием.
2.3.3.
Ограничение
ссылочной
целостности
Ограничение
ссылочной
целостности
в контексте
связи между
двумя
множествами
сущностей
предусматривает,
что для
каждой сущности
из первого
множества,
обязательно должна
существовать
сущность из
другого
множества, на
которую она
ссылается..
Создание
новых
сущностей.
Удаление
сущностей.
Принудительное
удаление
сущностей.
На
диаграммах
связи,
которые
должны обеспечивать
ссылочную
целостность,
обозначаются
круглыми
стрелками.

Рисунок
10
TR-диаграмма
с
обозначениями
ограничений
ссылочной
целостности
2.3.4.
Ограничения
других видов
Для
моделирования
произвольных
ограничений ER-диаграммы
не
предусматривают
никаких специальных
средств. Для
того чтобы
показать
ограничение,
нужно
атрибут или
связь сопроводить
примечанием,
описывающим
ограничение.
2.4.
Слабые
множества
сущностей
Существуют
сущности, для
которых
нельзя определить
уникальный
ключ. Выход
из ситуации –
ключ
формируют на
основе
атрибутов, которые
принадлежат
другому
множеству
сущностей.
Одна
причина
существования
таких сущностей.
Если
сущности
множества E
представляют
собой
единицы
более крупных
сущностей F,
вполне
вероятна
ситуация,
когда
атрибуты множества
E не
будут обладать
свойством
уникальности
пока не
приняты во
внимание
атрибуты
сущностей F
Примером
может
служить
иерархия
компания -
подразделения.

Рисунок
11
слабые
множества
сущностей
Иерархия
биологических
видов.
Род-вид.
Другая
причина
появления слабых
сущностей –
это
соединяющие
сущности,
которые, как
правило, не
имеют
собственных
атрибутов.
3.
Дореляционные
модели
данных
3.1.
Иерархическая
модель
данных
3.1.1.
Структура
данных
Организация
данных в СУБД
иерархического
типа
определяется
в терминах: элемент,
агрегат,
запись
(группа),
групповое
отношение, база
данных.
·
Атрибут
(элемент
данных) -
наименьшая
единица
структуры
данных. Обычно
каждому
элементу при
описании
базы данных
присваивается
уникальное
имя. По этому
имени к нему
обращаются
при
обработке. Элемент
данных также
часто
называют
полем.
·
Запись
- именованная
совокупность
атрибутов.
Использование
записей
позволяет за
одно обращение
к базе
получить
некоторую
логически
связанную
совокупность
данных.
Именно записи
изменяются,
добавляются
и удаляются.
Тип записи
определяется
составом ее
атрибутов. Экземпляр
записи -
конкретная
запись с конкретным
значением
элементов
·
Групповое
отношение
-
иерархическое
отношение
между
записями двух
типов.
Родительская
запись
(владелец группового
отношения)
называется
исходной записью,
а дочерние
записи (члены
группового
отношения) -
подчиненными.
Иерархическая
база данных
может
хранить
только такие
древовидные
структуры.
Корневая
запись
каждого
дерева
обязательно
должна
содержать
ключ с
уникальным
значением.
Ключи
некорневых записей
должны иметь
уникальное
значение только
в рамках
группового
отношения.
Каждая
запись
идентифицируется
полным сцепленным
ключом, под
которым
понимается
совокупность
ключей всех
записей от корневой
по
иерархическому
пути.
При
графическом
изображении групповые
отношения
изображают
дугами ориентированного
графа, а типы
записей - вершинами
(диаграмма
Бахмана).
Для
групповых
отношений в
иерархической
модели
обеспечивается
автоматический
режим
включения и фиксированное
членство.
Это означает,
что для запоминания
любой
некорневой
записи в БД
должна
существовать
ее
родительская
запись. При
удалении
родительской
записи
автоматически
удаляются
все
подчиненные.
3.1.2.
Операции
над данными,
определенные
в иерархической
модели:
- ДОБАВИТЬ
в базу
данных
новую
запись. Для корневой
записи
обязательно
формирование
значения
ключа.
- ИЗМЕНИТЬ
значение
данных
предварительно
извлеченной
записи.
Ключевые
данные не
должны подвергаться
изменениям.
- УДАЛИТЬ
некоторую
запись и все
подчиненные
ей записи.
- ИЗВЛЕЧЬ:
- извлечь
корневую
запись по
ключевому
значению,
допускается
также
последовательный
просмотр
корневых записей
- извлечь
следующую
запись
(следующая
запись
извлекается
в порядке
левостороннего
обхода
дерева)
В
операции
ИЗВЛЕЧЬ
допускается
задание условий
выборки
(например,
извлечь
сотрудников
с окладом
более 1
тысячи руб.)
Как видим,
все операции
изменения
применяются
только к
одной
"текущей"
записи (которая
предварительно
извлечена из
базы данных).
Такой подход
к
манипулированию
данных
получил
название
"навигационного".
3.1.3.
Ограничения
целостности.
Поддерживается
только
целостность
связей между
владельцами
и членами
группового
отношения
(никакой
потомок не
может существовать
без предка).
Как уже
отмечалось,
не
обеспечивается
автоматическое
поддержание
соответствия
парных
записей, входящих
в разные
иерархии.
3.2.
Сетевая
модель
данных
3.2.1.
Структура
данных.
На
разработку
этого
стандарта
большое влияние
оказал
американский
ученый
Ч.Бахман.
Основные
принципы
сетевой
модели данных
были
разработаны
в середине 60-х
годов, эталонный
вариант
сетевой модели
данных
описан в
отчетах
рабочей группы
по языкам баз
данных (COnference on DAta SYstem
Languages) CODASYL (1971 г.).
Сетевая
модель
данных
определяется
в тех же
терминах, что
и
иерархическая.
Она состоит
из множества
записей,
которые
могут быть
владельцами
или членами
групповых
отношений. Связь
между
записью-владельцем
и записью-членом
также имеет
вид 1:N.
Основное
различие
этих моделей
состоит в том,
что в сетевой
модели
запись может
быть членом более
чем одного
группового
отношения.
Согласно
этой модели
каждое
групповое
отношение
именуется и
проводится
различие
между его
типом и экземпляром.
Тип
группового
отношения задается
его именем и
определяет
свойства общие
для всех
экземпляров
данного типа.
Экземпляр
группового
отношения
представляется
записью-владельцем
и множеством
(возможно
пустым) подчиненных
записей. При
этом имеется
следующее
ограничение:
экземпляр
записи не может
быть членом
двух
экземпляров
групповых
отношений
одного типа.
3.2.2.
Операции
над данными.
- ДОБАВИТЬ
- внести
запись в БД и,
в зависимости
от режима
включения,
либо
включить ее в
групповое
отношение,
где она
объявлена подчиненной,
либо не
включать ни
в какое групповое
отношение.
- ВКЛЮЧИТЬ
В ГРУППОВОЕ
ОТНОШЕНИЕ -
связать
существующую
подчиненную
запись с
записью-владельцем.
- ПЕРЕКЛЮЧИТЬ
- связать
существующую
подчиненную
запись с
другой
записью-владельцем
в том же групповом
отношении.
- ОБНОВИТЬ
- изменить
значение
элементов
предварительно
извлеченной
записи.
- ИЗВЛЕЧЬ
- извлечь
записи
последовательно
по значению
ключа, а
также
используя
групповые
отношения -
от
владельца
можно перейти
к записям -
членам, а от
подчиненной
записи к
владельцу
набора.
- УДАЛИТЬ
- убрать из БД
запись. Если
эта запись
является
владельцем
группового
отношения,
то анализируется
класс
членства
подчиненных
записей. Обязательные
члены
должны быть
предварительно
исключены
из
группового
отношения,
фиксированные
удалены
вместе с
владельцем, необязательные
останутся в
БД.
ИСКЛЮЧИТЬ
ИЗ
ГРУППОВОГО
ОТНОШЕНИЯ -
разорвать
связь между
записью-владельцем
и
записью-членом.
4.
Реляционная
модель
Практически
все
современные
базы данных основаны
на
реляционной
модели. Эта
модель
проста, так
как
основывается,
чуть ли на единственном
основном
понятии –
отношении.
Отношение –
это
двухмерная
таблица, предназначенная
для
упорядоченного
хранения
данных. В
рамках этой
модели
поддерживается
язык
манипулирования
данными – SQL (Structured Query Language –
язык
структурированных
запросов).
Благодаря
языку SQL можно
составлять
простые и
эффективные
программы
манипулирования
данными. ER-модель
в этом отношении
уступает
реляционной
модели, так
как не
поддерживает
каких либо
средств доступа
к данным.
С другой
стороны
проектировать
базы данных
намного
легче именно
в терминах ER-модели.
Существуют
специальные
правила, используя
которые
можно
преобразовать
ER-модель
к
реляционной
модели.
Реляционная модель
также имеет
свои
собственные
правила
проектирования,
именуемые
правилами нормализации
отношений.
4.1.
Базовые
понятия
реляционных
баз данных
Реляционная
модель
предусматривает
единственный
способ
представления
данных – в
виде набора
двумерных
таблиц, которые
называют
отношениями.
Основными
понятиями
реляционных
баз данных
являются тип
данных,
домен,
атрибут, кортеж,
первичный
ключ и
отношение.
Таблица
хранит
информацию о
элементах
отношения
«кинофильмы».
Каждая
строка
отвечает
одной
сущности
«кинофильм»,
а каждый
столбец
одному из
атрибутов множеству
сущностей
«кинофильмы».
Отношения
могут
хранить не
только
множества сущностей,
но и
экземпляры
связей.
|
Наименование
|
Год
|
продолжительность
|
Жанр
|
|
Операция
Ы
|
1979
|
86
|
Комедия
|
|
Бриллиантовая
рука
|
1982
|
93
|
Комедия
|
|
Морозко
|
1963
|
76
|
Сказка
|
4.1.1.
Атрибуты
В верхней
части
таблицы
отношения
задается
перечень
наименований
атрибутов.
Атрибуты
выполняют
функцию
наименования
столбцов и
содержательно
описывают
смысл и
назначение
элементов данных
в
соответствующих
ячейках.
4.1.2.
Схема
отношения,
схема базы
данных
Наименования
отношения и
атрибутов
этого
отношения
называют
схемой (schema)
отношения.
Схема
отношения
представляется в виде
имени
отношения, за
которым идут
список
атрибутов
заключенных
в круглые
скобки.
Пример:
Кинофильмы
(Наименование,
Год, Продолжительность,
Жанр)
Атрибуты
схемы
отношения
образуют
множество, а
не
упорядоченный
список. То
есть схема
отношения
Кинофильмы
(Продолжительность,
Жанр, Наименование,
Год) и схема,
приведенная
выше
представляют
собой одно
и тоже
отношение.
Проект
базы данных
выполненный
в рамках реляционной
модели
включает
одно или несколько
схем
отношений.
Набор схем
отношений
называют
реляционной
схемой базы
данных (relational database schema) или
просто
схемой базы
данных (database schema).
4.1.3.
Домен
Одно из
требований,
выдвигаемых
реляционной
моделью
гласит, что
каждый
элемент данных
должен быть
атомарным,
т.е.
относиться к
какому либо
атомарному
типу. В
качестве значений
нельзя
использовать
такие
структуры
данных как
массивы,
списки,
множества и
другие составные
типы которые
допускают
разбиение на
более мелкие
элементы.
Также
полагается,
что с каждым
атрибутом ассоциирован
определенный
домен (domain), т.е.
некоторый
базовый тип.
Значения
атрибутов
должны
принадлежать
соответствующим
доменам,
определяемым
каждым из
атрибутов
отношения.
Наиболее
правильной
интуитивной
трактовкой
понятия
домена
является
понимание домена
как
допустимого
потенциального
множества
значений
данного типа.
4.1.4.
Кортеж,
отношение
Строки
отношения,
отличные от
той, которая представляет
наименования
атрибутов, называют
кортежами (tuples).
Кортеж
содержит по
одному
компоненту
для каждого
атрибута
отношения.
Если необходимо
описать
кортеж
отдельно, вне
контекста
отношения,
принято
заключать
его в круглые
скобки и
разделять
компоненты
символом
запятой:
(«Бриллиантовая
рука», 1982, 93,
«Комедия»)
В этом
случае,
видимая
связь
кортежа с
отношением
теряется, и
необходимо
явно указывать
к какому
отношению
относится, и
перечислять
порядок
атрибутов.
4.1.5.
Формы
представления
отношений
Отношение
- это
множество
кортежей (не
упорядоченный
список),
соответствующих
одной схеме
отношения.
Кортежи
отношения,
будучи
переставлены
местами, не
влияют на
содержимое
этого
отношения.
Более
того,
допускается
без каких
либо последствий
изменить и
порядок
следования
атрибутов
отношения.
Все
возможные
версии таблицы
являются
различными
формами
представления
отношения.
4.1.6.
Экземпляры
отношения
Отношения,
содержащие
информацию
об окружающем
мире, по
своей
природе
является
статичным;
отношениям
свойственно
изменяться.
Изменения обычно
затрагивают
содержимое
отношения: в
базу данных
помещаются
новые
кортежи, а также
модифицируются
или
удаляются
существующие.
Гораздо
менее
вероятны
изменения,
которые затрагивают
схему
отношения.
Однако
ситуации,
связанные с
добавлением,
изменением
или
удалением
атрибутов
отношения, на
практике все
же возникают.
Процессы,
вызывающие изменение
схемы
отношений
принято
называть эволюцией
схемы базы
данных.
Операции по
модификации
схем баз данных
в которых уже
есть
информация
обычно весьма
дорогостоящи,
так как могут
затрагивать
изменение
миллионов
кортежей.
Например, добавление
атрибутов
ведет не
только к модификации
физического
хранилища, но
и к тому, что
может
потребоваться
определение
осмысленного
значения
атрибута для
каждого
кортежа
отношения.
Конкретное
множество
кортежей
называют экземпляром
(instance)
отношения. В
течении
длительного
времени
конкретный
кортеж может
претерпевать
многочисленные
изменения.
Большинство
современных
базы данных
поддерживают
только одну
версию
отношения –
набор
кортежей, которые
содержатся в
отношении «в
данный момент».
Такой
экземпляр
отношения
принято
называть текущим
экземпляром (current instance).
4.2.
От ER-диаграмм
к
реляционным
схемам
Рассмотрим
процесс
проектирования
новой базы данных,
подобной
рассматриваемой
базы данных о
кинофильмах.
На первой
стадии процесса,
связанной с
проектированием,
формулируются
ответы на
вопросы:
какая
информация
будет
храниться в
БД; каким
образом
элементы
данных
соотносятся
друг с
другом; какие
ограничения
(ключи,
условия
ссылочной
целостности)
должны быть
введены. Эта
стадия может
протекать
циклически:
могут
всплывать
новые требования,
что приводит
к пересмотру
решения.
За
стадией
проектирования
идет стадия
реализации,
предусматривающая
использование
инструментов
конкретной
СУБД. Подавляющее
число
коммерческих
СУБД
основано на
реляционной
модели,
поэтому
логично предположить,
что в ходе
проектирования
уместно
предположить,
что в ходе
проектирования
было бы целесообразно
использовать
реляционную
модель, а не
модель
«сущность-связь»
или какие либо
другие
средства
проектирования.
На
практике,
однако,
зачастую
проще приступить
к
проектированию,
пользуясь ER-моделью,
осуществить
задуманное, а
затем преобразовать
результат в
реляционную
модель.
Основной
довод
заключается
в том, что
реляционная
модель,
будучи
основана на
единственном
понятии
«отношение»
обладает
определенными
ограничениями
в плане
гибкости.
В
первом
приближении
процесс
преобразования
ER
диаграмм
довольно
прямолинеен:
·
Преобразовать
каждое
множество
сущностей в
отношение с
тем же
набором
атрибутов;
·
Заменить
каждую связь
отношением,
атрибуты
которого
являются
ключами
множеств сущностей,
соединяемых
этой связью.
Названные
правила
охватывают
изрядную часть
предмета,
существует
несколько
особых ситуаций,
с которыми
приходится
считаться:
·
Слабые
множества
сущностей не
могут быть непосредственно
преобразованы
в отношения
непосредственно.
·
Связи isa и
подклассы
требуют
особого
подхода
·
Иногда
целесообразно
объединить в
составе
одного
отношения
два других – например,
отношение
для
множества
сущностей E с
отношением
для связи
типа «многие
к одному»,
которая
соединяет E с
другими
множествами.
4.2.1.
От
множеств
сущностей к
отношением
Для
каждого
множества
сущностей не
являющимся
слабым можно
создать
отношение с
таким же
именем и
набором
атрибутов.
Такое отношение
не будет
содержать каких бы
то ни было
сведений о
связях, в
которых участвует
исходное
множество
сущностей. Информация
отображается
в отдельных
отношениях.
Пример. Для
ER-схемы
(Рисунок
3
Диаграмма
сущностей и
связей для
базы данных о
кинофильмах) схема
отношения
«кинофильмы»
будет включать
атрибуты
«наименование»,
«год», «продолжительность»,
«жанр». Схема
для отношения
«актеры»
(«имя»,
«адрес»).
4.2.2.
От ER-связей
к отношениям
Связи ER-модели
также
представляются
отношениями.
Отношение
для заданной
связи R должно
охватывать
атрибуты,
перечисленные
ниже.
·
В схему
отношения
для связи R
заносятся
ключевые
атрибуты
каждого из множеств
сущностей,
соединяемых
связью R.
·
Если
связь
обладает
собственными
атрибутами,
они также
вводятся в
набор
атрибутов отношения
для этой
связи.
·
Если
одно и тоже
множество
сущностей
участвует в
контексте
связи
несколько
раз, в разных
ролях, то
ключевые
атрибуты
вводятся в
отношение
столько раз,
в скольких
ролях он
участвует.
Для атрибутов
которые
повторяются
в отношении
следует задавать
разные имена.
Пример: Связь
между
сущностями
«кинофильмы»
и «киностудии»
будет
преобразовано
в отношение,
состоящее из
ключевых
атрибутов
обоих множеств.
Схема
отношения
примет
следующий
вид:
«Студия
владелец»
(«название
фильма», «год»,
«наименование
студии»)
Связь
между
множествами
сущностей
«актеры» и
«кинофильмы»
может быть
преобразована
в схему
«актеры-участники»
(«название фильма»,
«год», «имя
актера»).
4.2.3.
Объединение
отношений
Иногда
отношения,
получаемые в
результате
прямых
преобразований
из множеств
сущностей и
связей,
нельзя
считать
наилучшей формой
представления
определенных
элементов
данных. Одна
из
распространенных
ситуаций
такова.
Имеется множество
сущностей E,
соединенное
посредством
связи R, типа
«многие к
одному» с
множеством F в
направлении
от E
к F.
Реляционные
схемы
каждого из
отношений для
множества E и
связи R будут
содержать
ключ
множества E.
Кроме того, в
схему
отношения
для множества
E
введены атрибуты
не
относящиеся
к ключевым, а
в схему
отношения
для связи R
ключевые
атрибуты F и
собственные
атрибуты.
Поскольку
связь относится
к типу
«Многие к
одному», все
кортежи,
могут быть
однозначно
определены с
помощью
ключевых
атрибутов E. Их
можно
объединить в
одной схеме,
состоящей из:
·
Всех
атрибутов
множества E
·
Ключевых
атрибутов
множества F
·
Собственных
атрибутов
связи R
Те
сущности из
множества E,
которые не
связаны ни с
одной
сущностью F, в
атрибутах
соответствующих
атрибутам R и F будут
записаны
некоторые
нулевые
значения. Значения
null
обычно имеют
место, когда
содержание
атрибута
кортежа
неизвестно
или утрачено.
Такое
объединение
отношений
уменьшает объем
хранимых
данных, а
также
облегчает выборку
информации
из БД.
Для связи
«один к одному»
возможно
объединение
двух множеств
и связи между
ними в одно
отношение.
Объединение
связи,
относящиеся
к типу многие
ко многим и
множества
сущностей,
приводит к
возникновению
дублированию
данных. Подобные
излишества
явно
нежелательны,
и одна из целей,
которая
ставилась
при
разработке
теории
реляционных
баз данных,
как раз
состоит в
устранении
информационной
избыточности.
4.2.4.
Преобразование
слабых
множеств
сущностей
Для
преобразования
слабого
множества сущностей
в отношение
необходимо
принимать во
внимание
следующее.
·
Отношение
для слабого
множества
сущностей W
должно
включать не
только
собственные
атрибуты W, но и
ключевые
атрибуты
всех других
множеств,
содействующих
в
формирования
ключа множества
W.
·
В
отношении
любой связи,
с которой
соединено
слабое множество
сущностей W,
должны быть
отражены все
ключевые
атрибуты
множества W, в
том числе и
те, которые
«получены»
от других
множеств.
·
Поддерживающая
связь R,
соединяющая
слабое
множество
сущностей W с
другим
множеством,
помогающим в
образовании
ключа для W,
однако, вовсе
не нуждается
в
преобразовании.
Дело в том,
что атрибуты
связи R либо уже
присутствуют
в отношении
множества W,
либо могут
быть
объединены
со схемой
отношения W.
4.2.5.
Преобразование
структур
подклассов в
отношения
Имея дело
с иерархией
отношений, мы
в праве
выбрать одну
из
нескольких
стратегий
преобразования.
Применить
подход
сущность
связь. Для
каждого
множества
сущностей E
иерархии
создать
отношение,
содержащее ключевые
атрибуты
корневого
множества сущностей
и все
атрибуты,
принадлежащие
E.
Трактовать
сущности как
объекты
одного
класса. Для
каждого
возможного
поддерева,
включающего
корневое
множество
сущностей,
создать одно
отношение,
схема
которого
содержит все
атрибуты
всех
множеств
сущностей принадлежащих
поддереву.
Использовать
значения null. Создать
одно
отношение,
включающее
все атрибуты
всех
множеств
сущностей
входящих в
иерархию.
Каждая
сущность
представляется
одним
кортежем, и
компоненты
кортежа, соответствующие
тем
атрибутам,
которые сущность
не имеет,
принимают null.
4.3.
Функциональные
зависимости
Независимо
от того,
каким
образом была
получена
реляционная
модель,
существует
возможность
повысить
качество
проекта, реализуя
разные типы
ограничений.
К наиболее важным
типам
ограничений
относятся
следующие
типы.
·
Функциональные
зависимости (functional dependency - FD).
Применяются
для
устранения
информационной
избыточности.
·
Многозначные
зависимости
(multivalued
dependecies)
·
Ограничения
ссылочной
целостности (referential integrity constraints)
4.3.1.
Определение
функциональной
зависимости
Функциональная
зависимость (functional dependency - FD) для
отношения R это
утверждение
следующего
вида: «Если
два кортежа
отношения R
совпадают в
атрибутах A1, A2,…, An, то они
должны
совпадать и в
другом
атрибуте, B».
Формально
это
утверждение
записывается
как A1,
A2,…, An ® B, и
свидетельствует,
что атрибуты Ai
обуславливают
B.
Если
несколько
атрибутов A1, A2,…, An
функционально
обуславливают
более одного
атрибута, т.е.
A1, A2,…, An ® B1
A1, A2,…, An ® B2
…
A1, A2,…, An ® Bn
Позволяется
сокращенно
представление
набора таких
FD:
A1, A2,…, An ® B1, B2,…, Bn
Пример:
«кинофильмы»
(«Название»,
«год», «продолжительность»,
«жанр»,
«студия»,
«актер»)
Мы имеем
право утверждать,
что:
«название»,
«год» ®
«продолжительность»
«название»,
«год» ®
«жанр»
«название»,
«год» ®
«студия»
или
кратко
«название»,
«год» ®
«продолжительность»,
«жанр»,
«студия»
Если
говорить
неформально,
то эта
функциональная
зависимость
свидетельствует,
что если два
отношения
обладают
попарно одинаковыми
значениями
компонентов
«название» и
«год», то они
должны содержать
одинаковые
значения для
атрибутов
«продолжительность»,
«жанр»,
«студия». Это
утверждение
справедливо,
если вспомнит
изначальный
смысл
реальных
объектов. Атрибуты
«название» и
«год»
образуют
ключ множества
сущностей
«кинофильмы»,
а ключ как мы
знаем
однозначно
определяет
экземпляр
сущности, и
следовательно
все не
ключевые
атрибуты. Связь
«кинофильмы»
- «студии»
относится к типу
«многие к
одному».
Следовательно,
любой
сущности
«кинофильм»
соответствует
не более
одной
сущности
«студия».
Отсюда возможна
функциональная
связь между
множествами.
4.3.2.
Ключи
отношений
Говорят,
что
множество
вида {A1,
A2,…,An},
состоящее из
одного или
нескольких
атрибутов,
является
ключом
отношения R,
если
выполняются
следующие
условия.
Атрибуты
A1, A2,…,An
функционально
обуславливают
все
остальные
атрибуты
отношения;
ситуация,
когда два
различных
кортежа
совпадающие
во всех
атрибутах A1, A2,…,An
невозможна.
Ни
одно из
допустимых
подмножеств
множества {A1, A2,…,An}
атрибутов не
являются
функциональным
обоснованием
всех
остальных
атрибутов
отношения R, т.е.
ключ минимален
(minimal).
Для
отношения
может быть
создано
несколько
ключей. В
этой
ситуации
одному из них
отводится
роль первичного
ключа (primary key). В
СУБД выбор
ключа может
обуславливать
особенности
физического
хранения
данных. В
тексте схемы
принято
ключевые
атрибуты
подчеркивать.
4.3.3.
Суперключи
Суперключем
называют
такое
множество атрибутов,
которое
содержит в
себе ключ в
качестве
подмножества.
Таким
образом,
каждый ключ
является и
суперключем,
но не каждый
суперключ
обладает условием
минимальности.
4.3.4.
Выбор
ключей
отношения
Когда
реляционная
схема
строится на
основе ER-диаграммы,
зачастую
структуру
ключа можно
предсказать
заранее.
Правила
выбора ключей
звучат так:
1. «Если
отношение
получено на
основе множества
сущностей,
ключ множества
формируется
из ключевых
атрибутов
множества
сущностей».
2. «Если
связь
относится к
типу «многие
ко многим»,
ключами
отношения R
становятся
ключевые
атрибуты
обоих множеств
сущностей,
соединяемых
связью»
3. «Если
связь
относится к
типу «многие
к одному» и
соединяет
множества
сущностей E1 и E2 в
направлении
от E1
к E2,
ключами
отношения R
должны быть
ключевые
атрибуты
множества E1»
4. «Если
связь
относится к
типу «один к
одному»,
ключевыми
атрибутами
отношения R
могут быть
ключи любого
из
соединяемых
множеств»
5. «Если
многосторонняя
связь R содержит
стрелку,
направленную
к множеству
сущностей E, существует
по меньшей
мере один
ключ для
соответствующего
отношения,
который
противоречит
ключу E»
4.4.
проектирование
реляционных
схем
небрежный
выбор
реляционной
схемы базы данных
может
повлечь за
собой
немалые
проблемы. Например,
объединение
атрибутов
связи «многие
ко многим» и
одним из
множеств,
соединяемых
этой связью,
приводит к
избыточности
данных.
4.4.1.
аномалии
Проблемы,
подобные
избыточности,
которые возникают
при введении
в отношение
слишком
большого
количества
атрибутов
принято
называть
аномалиями.
Разновидности
аномалий:
Избыточность
(redudancy).
Одинаковые
элементы
информации
повторяются
многократно
в нескольких
кортежах.
Аномалии
изменения (update anomalies).
Один и тот же фрагмент
данных
изменяется в
одном кортеже,
и остается
неизменным в
другом.
Аномалии
удаления (delete anomalies).
Если
множество
значений
становится
пустым, это
может
косвенным
образом
привести к потере
другой
информации.
4.4.2.
Тривиальные
зависимости
Говорят, что
зависимость A1 A2…An®B
называется
тривиальной (trivial),
если атрибут B
совпадает с
любым из
атрибутов Ai, где i=1,2…n.
Например
«название
фильма»
«год» ®
«год»
4.4.3.
Декомпозиция
отношений
Один из
наиболее
приемлемых
способов устранения
аномалий,
состоит в декомпозиции
(decomposing)
отношений.
Этот способ
предполагает
разделение
атрибутов
отношения R с
целью
построения
схем двух
новых отношений
с
последующим
занесением в
эти отношения
определенных
кортежей из R.
Существует
набор правил
именуемых
нормальными формами.
Эти правила
позволяют
повысить качество
схемы
реляционной
БД.
·
Первая
нормальная
форма (1НФ)
·
Вторая
нормальная
форма (2НФ)
·
Третья
нормальная
форма (3НФ)
·
Нормальная
форма
Бойса-Кодда(НФБК, BCNF)
·
Четвертая
нормальная
форма (4НФ)
·
Пятая
нормальная
форма или
нормальная
форма
проекции-соединения
(5НФ или НФПС)
Каждая
нормальная
форма более
высокого порядка
является
более
выгодной с
точки зрения
концепции
реляционных
БД, чем
предыдущая.
При
переходе к
следующей
нормальной
форме
свойства
предыдущих
нормальных
форм
сохраняются.
Процесс
проектирования
заключается
в декомпозиции
отношений на
два или более
отношения,
удовлетворяющих
требованиям
следующей НФ.
4.4.4.
Первая
нормальная
форма
Модель
данных
соответствует
первой нормальной
форме, если в
таблицах
отсутствуют повторяющиеся
группы
значений.
Отношение
находится в
первой
нормальной форме,
если оно
содержит
только
логически-неделимые
значения,
которые
принято называть
скалярными.
Сотрудник
(Имя, Год
рождения,
Дети)
Простые
атрибуты,
составные
атрибуты.
4.4.5.
Вторая
нормальная
форма
Неключевой
атрибут
функционально
полно зависит
от
составного
ключа если он
функционально
зависит от
всего ключа в
целом, но не
находится в
функциональной
зависимости
от
какого-либо
из входящих в
него атрибутов.
Отношение
находится во
второй нормальной
форме, когда
находится в 1NF,
и значения
неключевых
атрибутов
функционально
полно
зависят от
ключа.
4.4.6.
Третья
нормальная
форма
Пусть X, Y, Z -
три атрибута
некоторого
отношения.
При этом X --> Y и Y -->
Z, но обратное
соответствие
отсутствует,
т.е. Z -/-> Y и Y -/-> X.
Тогда Z
транзитивно
зависит от X.
Отношение
находится в
3НФ, если оно
находится во 2НФ и
каждый
неключевой
атрибут
нетранзитивно
зависит от
первичного
ключа.
Отношение
R
удовлетворяет
форме 3NF, если
выполняется
следующее
требование: всякий
раз, когда
для
отношения R
существует
некоторая
нетривиальная
FD A1 A2…An®B,
соответствующее
множество {A1 A2…An}
представляет
собой
суперключ
для R либо B
является
членом ключа.
4.4.7.
Нормальная
форма
Бойса-Кодда
Существует
простое условие
которое
гарантирует
что в
отношении
нет аномалий.
Это условие
называют
нормальной
формой
Бойса-Кодда (Boyce-Codd normal form - BCNF):
Отношение
R
удовлетворяет
форме BCNF если
и только если
выполняется
требование:
всякий раз,
когда для
отношения R
существует
некоторая нетривиальная
FD A1 A2…An®B,
соответствующее
множество {A1 A2…An}представляет
собой
суперключ
для R.
4.4.8.
Четвертая
нормальная
форма
Многозначная
зависимость
это
утверждение
о том, что два
атрибута или
множества
атрибутов
независимы
друг от
друга, т.е.
могут присутствовать
в отношении
во
всевозможных
комбинациях.
Такая
ситуация
может
возникнуть
когда в рамках
одного
отношения
пытаются
представить
несколько
связей
многие ко
многим.
Отношение
находится в 4NF если оно
находится в BCNF
и в нем
отсутствуют
многозначные
зависимости,
не
являющиеся
функциональными
зависимостями.
4.4.9.
Пятая
нормальная
форма
Зависимость
соединения
Отношение
R (X, Y, ..., Z)
удовлетворяет
зависимости соединения
* (X, Y, ..., Z) в том и
только в том
случае, когда
R
восстанавливается
без потерь путем
соединения
своих
проекций на X, Y,
..., Z.
Пятая
нормальная
форма
Отношение
R находится в
пятой
нормальной форме
(нормальной
форме
проекции-соединения
- PJ/NF) в том и
только в том
случае, когда
любая зависимость
соединения в
R следует из
существования
некоторого
возможного
ключа в R.
4.5.
Фундаментальные
свойства
отношений
Остановимся
теперь на
некоторых
важных свойствах
отношений,
которые
следуют из приведенных
ранее
определений:
4.5.1.
Отсутствие
кортежей-дубликатов
То свойство,
что
отношения не
содержат кортежей-дубликатов,
следует из
определения
отношения
как
множества
кортежей. В
классической
теории
множеств по
определению каждое
множество
состоит из
различных элементов.
Из этого
свойства
вытекает
наличие у
каждого
отношения
так
называемого
первичного
ключа -
набора
атрибутов,
значения
которых однозначно
определяют
кортеж
отношения. Для
каждого
отношения, по
крайней мере,
полный набор
его
атрибутов
обладает
этим свойством.
Однако при
формальном
определении
первичного
ключа
требуется
обеспечение
его "минимальности",
т.е. в набор
атрибутов
первичного
ключа не
должны
входить
такие
атрибуты, которые
можно
отбросить
без ущерба
для основного
свойства -
однозначно
определять кортеж.
Понятие первичного
ключа
является
исключительно
важным в
связи с понятием
целостности
баз данных.
Забегая
вперед,
заметим, что
во многих
практических
реализациях
РСУБД
допускается нарушение
свойства
уникальности
кортежей для
промежуточных
отношений,
порождаемых
неявно при
выполнении
запросов.
Такие отношения
являются не
множествами,
а
мультимножествами,
что в ряде
случаев позволяет
добиться
определенных
преимуществ,
но иногда
приводит к
серьезным
проблемам.
4.5.2.
Отсутствие
упорядоченности
кортежей
Свойство
отсутствия
упорядоченности
кортежей
отношения
также
является
следствием
определения отношения-экземпляра
как
множества
кортежей.
Отсутствие
требования к
поддержанию
порядка на
множестве
кортежей
отношения
дает
дополнительную
гибкость
СУБД при хранении
баз данных во
внешней
памяти и при выполнении
запросов к
базе данных.
Это не противоречит
тому, что при
формулировании
запроса к БД,
например, на
языке SQL можно
потребовать
сортировки
результирующей
таблицы в
соответствии
со
значениями
некоторых
столбцов. Такой
результат,
вообще
говоря, не
отношение, а
некоторый
упорядоченный
список кортежей.
4.5.3.
Отсутствие
упорядоченности
атрибутов
Атрибуты
отношений не
упорядочены,
поскольку по
определению
схема
отношения
есть множество
пар {имя
атрибута, имя
домена}. Для
ссылки на
значение
атрибута в
кортеже отношения
всегда
используется
имя атрибута.
Это свойство
теоретически
позволяет,
например, модифицировать
схемы
существующих
отношений не
только путем
добавления
новых атрибутов,
но и путем
удаления
существующих
атрибутов.
Однако в
большинстве
существующих
систем такая
возможность
не допускается,
и хотя упорядоченность
набора
атрибутов
отношения
явно не
требуется,
часто в
качестве
неявного
порядка
атрибутов
используется
их порядок в
линейной
форме
определения
схемы
отношения.
4.5.4.
Атомарность
значений
атрибутов
Значения
всех
атрибутов
являются
атомарными.
Это следует
из
определения
домена как
потенциального
множества
значений
простого типа
данных, т.е.
среди
значений
домена не
могут
содержаться
множества
значений
(отношения).
Принято
говорить, что
в
реляционных
базах данных
допускаются
только
нормализованные
отношения
или
отношения,
представленные
в первой
нормальной
форме.
5.
Реляционная
алгебра
Реляционная
алгебра
представляет
собой алгебру
множеств.
Операции
производятся
над
кортежами и
отношениями.
Все операции реляционной
алгебры в том
или ином виде
реализованы
в языке SQL.
5.1.
Алгебра
реляционных
отношений
Развитие
реляционной
алгебры
имеет свою историю.
Изначально
реляционная
алгебра разработана
Коддом в виде
совокупности
операторов,
выполняемых
над
множеством
кортежей и
обеспечивающих
возможность
выражения
типичных
запросов
касающихся
содержимого
отношений.
Алгебра
охватывала
пять
операций над
множествами: объединение
отношений (union), разность
(difference),
декартово
произведение
(Cartesian product),
выбор (selection) и
проекция (projection).
С
появлением
первых СУБД,
основанных
на
реляционной
модели, операторы
реляционной
алгебры были
разработаны
в языках
запросов.
В ходе
развития
коммерческих
СУБД алгебру
отношений
понадобилось
пополнить
целым рядом
новых
операций,
наиболее
важные из них
связаны с
функциями агрегирования
(aggregation),
т.е.
нахождение
суммарных,
средних,
максимальных,
минимальных
и иных
значений в
определенном
атрибуте
отношения.
5.1.1.
Основы
реляционной
алгебры
Некоторая
алгебра,
вообще
говоря,
состоит из
набора
операторов,
применяемых
к атомарным операндам.
Например, в
арифметике
атомарные
операнды
представляют
собой
переменные
вида x
и численные
константы.
Операторами
служат
обычные
арифметические
операторы
сложения,
вычитания,
умножения и
деления.
Любая алгебра
позволяет
создавать выражения
(expressions)
путем
применения
операторов к
операндам или
другим
выражениям,
допустимым в
контексте
этой алгебры.
Реляционная
алгебра это
одна из видов
алгебр. В ней
поддерживаются
следующие
виды атомарных
операндов:
·
Переменные,
обозначающие
отношения
·
Константы,
являющиеся
конечными
отношениями
В
классической
реляционной
алгебре все операнды
и результаты
вычисления
выражений
являются
множествами.
Операции
реляционной
алгебры
относятся к
одному из
четырех
классов:
1.
Обычные
операции над
множествами
– объединение
(union),
пересечение (intersection) и
разность (difference), -
применяемые
к отношениям
2.
Операции
удаления
частей
отношения:
операция
выбора (selection)
производит к
отбрасыванию
некоторых
кортежей
(строк), а
операция
проекции – к
устранению
некоторых
атрибутов.
3.
Операции
сочетания
кортежей
двух отношений.
Например,
операция
Декартова
произведения,
операция
соединения.
4.
Операция
переименования
(renaming)
атрибутов
или
отношения
целиком.
Выражения
реляционной
алгебры
принято называть
запросами (queries).
5.1.2.
Теоретико-множественные
операции над
отношениями
К числу
наиболее
известных и
употребительных
операций
теории
множеств
относятся объединение
(union),
пересечение (intersection) и
разность (difference).
R U S,
объединение
множеств R и S, -
множество
элементов, присутствующих
в R, S или
обоих
множествах
одновременно.
Каждый
элемент в
множество
включается
только один
раз.
R ∩ S,
пересечение
множеств R и S, -
множество
элементов,
присутствующих
в множествах R и S
одновременно.
R
– S,
разность
множеств R и S,
множество
элементов,
являющихся
членами R, но
отсутствующих
в S.
Заметим, что R – S – не то
же самое, что S – R.
Если R и S
представляют
собой
множества
кортежей (отношения),
они должны
удовлетворять
соответствующим
требованиям:
1. Обладать
схемами с
идентичными
атрибутами,
типы (домены)
которых
обязаны попарно
совпадать;
2. Атрибуты
(столбцы)
должны
следовать в
одном же
порядке.
Иногда
приходится
вычислять
объединение,
пересечение
или разность
отношений,
атрибуты
которых
относятся к
совпадающим
типам, но
обладают
разными
наименованиями
столбцов. В
подобных случаях
приходится
применять
применить оператор
переименования,
чтобы
изменить схему
одного или
обоих
отношений,
обеспечив им
идентичность.
5.1.3.
Проекция
Оператор
проекции (projection)
применяется
к отношению R с
целью получения
нового
отношения,
которое
содержит
некоторые
атрибуты из R.
Значением
выражения Π A1, A2,…,An (R) является
отношение,
содержащее
атрибуты A1, A2,…, An.
Схема
отношения
охватывает
множество атрибутов
{A1, A2,…,An},
отображаемых
в указанном
порядке.
5.1.4.
выбор
Оператор
выбора (selection), будучи
примененным
к отношению R,
дает в
результате
новое
отношение,
содержащее
подмножество
кортежей R,
удовлетворяющих
определенному
критерию C,
которое
накладывается
на атрибуты
отношения R.
Оператор
выбора
принято обозначать
как σC(R).
Схемы
итогового и
исходного
отношения совпадают
и порядок
следования
атрибутов в
них сохраняется.
C
– это
условное
выражение,
подобное тем
которые применяются
в
традиционном
программировании.
Отличием
является то,
что его
операндами
являются
константы
или названия
атрибутов отношения.
Выражение C
вычисляется
для каждого
кортежа,
вместо названий
атрибутов
подставляются
значения
атрибутов
кортежа. Если
выражение
истинно, то
кортеж
попадает в
итоговое
отношение, в
противном
случае не
попадает.
5.1.5.
Декартово
произведение
Декартово
произведение
(Cartesian product)
двух
множеств R и S
представляет
собой
множество
пар, таких, что
первым
элементом
пары
является
любой элемент
множества R, а
вторым –
любой
элемент
множества S.
Операция
обозначается
так R ´
S.
Когда в роли
операндов
выступают
отношения,
существо
операции не
меняется.
Поскольку
отношения
обычно
содержат
более одного
компонента,
результатом
операции
является
отношение,
содержащее
атрибуты
отношения R и S.
Порядок
следования
атрибутов в
итоговом
отношении
таков: сперва
идут
атрибуты
отношения R,
затем
атрибуты
отношения S.
5.1.6.
Естественное
соединение
Гораздо
чаще, чем
операция
декартова
произведения,
возникает
потребность
в соединении
(join)
двух
отношений,
т.е.
формирования
пар таких
кортежей, которые
удовлетворяют
определенному
критерию.
Простейшим
вариантом
такого соединения
является естественное
соединение.
Обозначают
как
R |><|
S
Результат
выполнения
оператора
предусматривает
включение в
итоговое
отношение тех
кортежей из R и S,
совпадают в атрибутах
общих
для схем R и S.
Если
кортежи
успешно
соединены, то
результат
называют соединенным
кортежем (joined tuple) и
содержащий
по одному
компонету
для каждого
из атрибутов
схемы
полученной в
результате
объединения
схем R и S.

Кортежи
одного
отношения,
которые не в
состоянии
образовать
пару с
кортежами
другого
отношения
называют висящими
(dangling tuples)
5.1.7.
Тета
соединение
Естественное
соединение
основано на
частном
условии
равенства
содержимого
компонентов,
которые
соответствуют
атрибутам,
общим для
обоих
отношений.
Хотя такая
ситуация
является
более распространенной,
желательно
иметь
возможность
соединения
отношений по
другим критериям.
Такая
операция
называется
тета-соединением
(theta-join).
Операция
тета-соединения
отношений R и S в
соответствии
с условием С
обозначается
как:
R |><|
S
C
И
выполняется
следующим
образом:
- Вычисляется
декартово
произведение
R и S
- Из
результата
произведения
выбираются
те кортежи,
которые
удовлетворяют
заданному
условию C.
Как и при
выполнения декартова
произведения,
схема
итогового отношения
представляет
собой
объединение
схем
отношений R и S.
5.1.8.
Наборы
операций
Реляционная
алгебра
позволяет
применять
операторы не
только к
исходным
отношениям,
но и к
результатам
выполнения
других операторов.
Это позволяет
создавать
сложные
выражения.
Выражения
реляционной
алгебры
могут содержать
скобки,
задающие
порядок
группирования
выражений.
Один и тот
же алгоритм
может быть
реализован
различными
способами.
П название,
год (σпродолжительность(Кинофильмы)
∩ σстудия=’мрсфильм’(кинофильмы))
=
= П название,
год (σпродолжительность
AND
студия=’мрсфильм’
(Кинофильмы))
Зачастую
допускается
сложные
выражения представлять
в виде
деревьев
частных выражений.
Эта форма
представления
облегчает
восприятие,
хотя и очень
громоздка.
5.1.9.
Переименование
атрибутов
В
процессе
конструирования
запросов возникает
необходимость
применения
операции
переименования
атрибутов.
Для этих целей
применяется
оператор ρS (A1, A2,..,An)(R).
Итоговое
отношение
имеет те же
кортежи что и
R, но
получает
новое имя S а
его атрибуты A1, A2,…,An в
порядке с
лева направо.
Если
необходимо сменить
только имя
отношения
применяется сокращенная
запись ρS(R).
5.1.10.
Зависимые
и
независимые
операторы
Некоторые
из ранее
рассмотренных
операции
реляционной
алгебры
могут быть
выражены в
терминах
других
операций.
Например, операция
пересечения
допускает
замену парой
операций
разности:
R ∩ S
= R – (R - S).
Оператор
тета-соединения
может быть
представлен
с помощью
других
операторов:
Чтобы
отыскать
результат,
нужно сперва
вычислить
декартово
произведение
R x S, а
затем
применить к
последнему
оператор выбора,
предусматривающий
выполнение
условия C вида:
R.A=S.A AND
R.B=S.B AND R.C=S.C…
Оператор
естественного
соединения
 ,
,
где L –
полный
список
атрибутов R и S.
Указанные
выше формулы
представляют
все возможные
зависимости
между
операторами
реляционной
алгебры.
Шесть
операций – объединения
(U),
разности (-),
выбора (σ),
проекции (π),
декартова
произведения
(x) и
переименования
(ρ) являются
независимыми
и каждую из
них нельзя
выразить в терминах
остальных
пяти.
5.2.
Мультимножества
Множество
кортежей это
простая и
естественная
форма
представления
кортежей.
Несмотря на
это в
современных
СУБД
отношения могут
содержать
повторяющиеся
кортежи. Напомним,
что множество,
допускающее
хранение
повторяющихся
кортежей
принято
называть мультимножеством.
Почему
именно
мультимножества?
Дело в том, что
это напрямую
связано с
эффективностью
обработки
запросов.
Всякий раз,
когда в результате
операции над
отношением
получается
другое
отношение и
предполагается,
что оно
является
множеством,
необходимо
убедиться в
том, что
отсутствуют
повторяющиеся
кортежи. Если
в отношении
содержатся тысячи
кортежей
то такая
операция
может занять
длительное
время. Если
предполагать
что результатом
является
мультимножество,
никаких
проверок
делать не
нужно и
операция над
отношением
производится
значительно
быстрее.
5.3.
дополнительные
операции
реляционной
алгебры
оператор
удаления
кортежей-дубликатов
(duplicate-elimination operator) δ
преобразует
отношение-мультимножество
в
множество
путем
отбрасывания
всех копий каждого
кортежа, за
исключением
одной.
Операторы
агрегирования
(aggregation operator),
предназначенные
для
нахождения
суммарных,
средних,
максимальных
и
минимальных
значений в
определенном
столбце.
SUM, AVG, MIN, MAX, COUNT.
Оператор
группирования
(grouping) γL(R)
множество
кортежей-строк
отношения
разбивается
на группы в
соответствии
с содержимым
одного или
нескольких
компонентов.
Затем к
атрибутам-столбцам
в пределах
группы
применяется
оператор
агрегирования.
Это
позволяет
формировать
запросы,
которые
нельзя
выразить в терминах
традиционной
реляционной
алгебры.
Оператор
сортировки
(sorting operator)
τ
преобразует
отношение в
список
кортежей
упорядоченных
в
соответствии
с некоторым
критерием.
Оператор
проекции
может быть
наделен
расширенными
полномочиями.
Помимо
обычной
проекции
отношения он
может быть
применен для
поучения
новых атрибутов.
πA, B+C -> X (R)
Оператор
внешнего
соединения
(outerjoin operator)
позволяет
избежать
потери
висящих кортежей.
Висящие
кортежи
включаются в
итоговое
отношение, и
соответствующие
компоненты
их
заполняются
значениями null.
6.
Язык SQL
Запросы (queries)
относительно
содержимого
базы данного
и команды его
изменения
наиболее
часто описываются
средствами
языка SQL (Structured Query Language –
язык
структурированных
запросов;
«сикуэл»).
Этот язык
позволяет
выполнять
все операции
реляционной
алгебры
(включая
дополнительные
операции).
Помимо этого SQL
предоставляет
возможность
изменения структуры
базы данных.
Таким образом
язык SQL
способен
выполнять
как функции
языка DML, так и DDL.
Существует
множество
различных
диалектов SQL.
Прежде всего,
это три
основных
стандарта языка:
ANSI SQL,
SQL92 (SQL2), SQL99 (SQL3).
Кроме этого
существуют
версии
поддерживаемые
производителями
СУБД. Как
правило, все
они
совместимы с ANSI SQL и
частично с SQL92.
6.1.
Простые
запросы на
языке SQL
Простейший
SQL
запрос
позволяет
выбрать из
отношения группу
кортежей,
удовлетворяющих
определенному
критерию. Для
конструирования
таких
запросов
используются
ключевые
слова SELECT (выбрать), FROM(из), WHERE(при
условии).
SELECT
* FROM
кинофильмы WHERE
студия=’мосфильм’
·
В
предложении FROM
перечислены
отношения, к
которым
обращен запрос.
·
Предложение
WHERE
задает
условие,
аналогично
условию C
оператора σ в
реляционной
алгебры.
Выбираемые
кортежи
обязаны
удовлетворять
условию WHERE.
·
Предложение
SELECT
оговаривает,
какие
атрибуты
кортежей, принадлежащих
отношениям
из FROM
и
удовлетворяющих
условию из WHERE.
Один из
способов
интерпретации
запроса состоит
в последовательном
просмотре
каждого
кортежа отношения,
упомянутого
во FROM,
проверке
условия WHERE. Если
условие
выполняется,
то значения
компонентов
кортежа
включаются в
итоговое отношение.
6.1.1.
Проекция
в SQL
При
необходимости
мы можем
выбрать
только
определенные
атрибуты
кортежей
отношения,
т.е. осуществить
проекцию
отношения.
Для решения
этой задачи в
предложении SELECT
вместо
символа
звездочки *
следует
задать список
выбираемых
атрибутов.
SELECT
наименование,
продолжительность
FROM
кинофильмы
WHERE
студия=’мосфильм’
AND
год=1980
Иногда
необходимо
получить
названия столбцов
отличные от
атрибутов
исходного отношения.
Для этого
применяется
ключевое слово
AS
SELECT
наименование,
продолжительность
AS
длительность
FROM
кинофильмы
WHERE
студия=’мосфильм’
AND
год=1980
Еще одна
возможность
связана с
использованием
выражений в
предложении SELECT:
SELECT
наименование,
продолжительность/60
AS
длительность_в_часах
FROM
кинофильмы
WHERE
студия=’мосфильм’
AND
год=1980
В
качестве
выражений
допустимо
использовать
константы.
6.1.2.
Выбор в SQL
Возможность
выбора в SQL
значительно
превышают
возможности
оператора σ
реляционной
алгебры.
Условные
выражения
могут
создаваться
на основе
шести
операторов
сравнения: «=», «<>», «>»,
«<», «>=», «<=». В
роли
операндов
могут
использоваться
константы и идентификаторы-имена
атрибутов
отношений.
Строковые
константы
должны быть
заключены в
одинарные
кавычки.
Результат
операции
сравнения –
значение булева
типа (TRUE
/ FALSE).
Булевы
выражения
могут
сцепляться с
помощью
логических
функций AND, OR, NOT
Связь SQL и
реляционной
алгебры
SELECT L
FROM R
WHERE C
эквивалентно
πL (σC(R))
6.1.3.
Сравнение
строк
Две
строки
считаются
равными, если
они состоят
из
одинаковых
символов,
следующих в одном
и том же
порядке.
<>.
Алфавитный
порядок.
Язык SQL
предоставляет
возможность
сравнения
строки с
образцом.
s LIKE p
s
– тестируемая
строка, p – образец.
Образец
может
включать
специальные
символы
подстановки %
и _.
6.1.4.
Бинарные
данные
B’1000101’
X’5ff3a’
6.1.5.
Дата и
время в SQL
Значениям
даты
соответствуют
специальные
типы данных.
Форматы представления
дат:
DATE
‘1948-05-14’
TIME
’15:00:45.1234’
TIMESTAMP
‘1948-05-14 12:00:00’
6.1.6.
Значение
NULL и
операции
сравнения с NULL
Значение
атрибута NULL
соответствует
отсутствию
информации
или
неприменимости
ее в данном
контексте
Проверка: x IS NULL;’ x IS NOT NULL
При
сравнении со
значением NULL
выражение
вернет
значение UNKNOWN.
Трехзначная
логика.
6.1.7.
Упорядочение
атрибутов
ORDER BY
<список атрибутов>
ASC
/ DESC
6.2.
Запросы
к нескольким
отношениям
Мощь
реляционной
алгебры
обусловлена
возможностью
сочетания нескольких
отношений с
помощью
операций соединения,
декартова
произведения,
объединения,
пересечения
и разности.
Все эти операции,
так или
иначе,
реализованы
в языке SQL.
6.2.1.
Декартово
произведения и
соединение в SQL
Чтобы
получить
декартово
произведение
двух отношений,
в выражении FROM
указываются
названия
этих
отношений
через
запятую:
SELECT
*
FROM
киностудии,
актеры
Чтобы
получить
соединение в
условии WHERE
указываются
атрибуты, по
которым
соединяются
отношения (в
случае
естественного
отношения
это атрибуты
одинаковые
для обоих
отношений):
SELECT
*
FROM
кинофильмы,
участники,
актеры
WHERE
кинофильмы.название
=
участники.название_студии
AND
Кинофильмы.год=
участники.год
AND
Участники.имя_актера=
актеры.имя
6.2.2.
Как
различать
одноименные
атрибуты
нескольких
отношений
Для
различения
одноименных
атрибутов в нескольких
отношениях
используется
конструкция
«полного»
имени
атрибута.
Конструкция
состоит из
наименования
отношения, точки
и
наименования
атрибута:
отношение.атрибут
6.2.3.
переменные
кортежей и
псевдонимы
отношений
использование
полных имен
вполне
удовлетворяет
требованиям,
пока в
запросе
упоминается
несколько
различных
отношений. Если
необходимо
соединение
нескольких
кортежей
одного и того
же отношения.
Отношение
может быть
упомянуто в
запросе
сколько угодно
раз, но
возникает
необходимость
различать отношения.
SQL
позволяет
каждому
отношению
назначить уникальный
псевдоним (alias).
Имя
отношения и
псевдоним
разделяются
(необязательным)
служебным
полем AS.
6.2.4.
Интерпретация
запросов
Вложенные
циклы
Преобразование
в выражения
реляционной
алгебры
6.2.5.
Объединение,
пересечение,
разность
запросов
Операторам
объединения
(U) ,
пересечения (∩) и
разности (-)
соответствуют
ключевые
слова UNION, INTERSECT
и EXCEPT.
Каждое
ключевое
слово
располагается
между
текстами
двух
запросов.
6.3.
Подзапросы
Язык SQL
позволяет
использовать
один запрос в
качестве
вспомогательного
при
вычислении другого
запроса. Запросы
которые
являются
частью более
«крупного»
подзапроса,
принято
называть подзапросом
(subquery).
Степень
взаимной
вложенности
запросов не ограничивается
и может быть
произвольной.
Существует
четыре типа
использования
подзапросов:
·
Запросы
с
использованием
UNION, INTERCECT и EXCEPT.
·
Подзапрос
возвращает
единственное
значение,
которое
сравнивается
с другим
значением в
условии WHERE
·
Запрос
возвращает
отношение,
используемое
в выражении WHERE с
той или иной
целью
·
Запрос
оперирует
отношениями,
перечисленными
в
предложении
в
предложении FROM
6.3.1.
Подзапросы
для
вычисления
скалярных
значений
Атомарное
значение,
способное
выступать в
качестве
содержимого одного
компоненты
кортежа
отношения
называют скаляром
(scalar).
Запросы вида SELECT - FROM - WHERE
могут
возвращать
отношения с
любым количеством
атрибутов и
кортежей.
Однако,
зачастую
необходимо
получать
одно единственное
значение.
Если запрос
возвращает единственное
значение, он
может быть
использован
в качестве
подзапроса,
заключенного
в круглые
скобки и
располагаемого
в любом месте
предложения WHERE, где
допустимо
использование
скалярного значения.
6.3.2.
Условия
уровня
отношения
В SQL
предусмотрен
ряд операторов,
которые
применяются
к некоторому
отношению R в
целом, и
возвращают
скалярное
значение булева
типа.
Некоторые из
операторов EXISTS ,IN, ANY, ALL.
·
Условие
EXISTS R
равно TRUE, если и
только если R не
пусто.
·
Условие
s IN R
равно, если и
только если s равно
одному из
значений в R.
Напротив s NOT IN R
обращается в TRUE,
если и только
если s
не равно ни
одному из
значений в R.
·
Условие
s>ALL R
равно TRUE тогда и
только тогда
если s
превосходит
все значения
в R.
Оператор >
может быть
заменен на =, >=,
<=, <, <>.
Выражения s<> ALL R и s NOT IN R эквивалентны
·
Условие
s>ANY R
равно TRUE, если и
только если s превосходит
по меньшей
мере одно
значение из R.
Выражения s=ANY R и s IN R
эквивалентны.
6.3.3.
Условия
уровня
кортежа
SELECT *
FROM R
WHERE (A,
B) IN (SELECT C, D FROM S)
6.3.4.
Подзапросы
в
предложениях
FROM
Подзапросы
могут
использоваться
в качестве
отношений.
6.3.5.
Выражения
соединения SQL
Декартово
произведение
= CROSS JOIN
Тета-соединение = R JOIN S ON R.FIELD1=S.FIELD2
Естественное
соединение = NATURAL JOIN
Внешнее соединение = NATURAL
FULL OUTER JOIN
NATURAL LEFT OUTER JOIN
NATURAL RIGHT OUTER JOIN
6.4.
Операции
над
отношениями
6.4.1.
Удаление
кортежей-дубликатов
SELECT
DISTINCT
6.4.2.
Дубликаты
в
объединениях,
пересечениях,
разностях
SELECT A,
B, C
FROM R
UNION ALL
SELECT A,
B, C
FROM S
Кортежи
дубликаты
при
объединении
множеств R и S
удаляться не
будут.
6.4.3.
Группирование
и
агрегирования
в SQL
Операторы
агрегирования:
SUM, AVG, MIN, MAX,
COUNT
SELECT AVG(A) FROM R
Группировка:
SELECT A, SUM(B)
FROM R
GROUP BY A
HAVING A>x
Условие в
предложении HAVING
накладывается
на результат
группировки и
вычисление
агрегатных
функций.
6.5.
Модификация
базы данных
Операции
над данными:
·
Вставка
(insertion)
·
Удаление
(deletion)
·
Изменение
(updating)
6.5.1.
Вставка
кортежей
INSERT INTO
R (A, B, C) VALUES (a, b, c)
INSERT INTO
R (A, B)
SELECT C,D FROM S
WHERE D=x
6.5.2.
Удаление
кортежей
DELETE FROM
R WHERE C
6.5.3.
Обновление
данных
UPDATE R
SET A1=v1, A2=v2, A3=v3 WHERE C
6.6.
Определение
схем
отношений в SQL
6.6.1.
Типы
данных
Строки:
CHAR(n)
– строка
постоянной
длинны n символов
VARCHAR(n)
– строка
переменной
длинны
Строки
битов
BIT(n)
BIT VARYING(n)
Логические:
BOOLEAN
– логический тип TRUE / FALSE / UNKNOWN
Целые:
INT
(INTEGER) – 4 байта
SHORTINT
– 2 байта
Числа с
плавающей
запятой:
FLOAT
(REAL)
DOUBLE
PRECISION
DECIMAL(n,
d)
NUMERIC
Дата, время:
DATE
TIME
6.6.2.
Объявление отношений
CREATE
TABLE (
Name CHAR(30),
Address VARCHAR(255)
)
6.6.3.
модификация
реляционных
схем
DROP TABLE
R – удаление
отношения R из
БД
ALTER TABLE
R ADD A CHAR(5)
ALTER TABLE
R DROP A
7. Системные
аспекты SQL
СУБД
как правило
имеют собственный
интерпретатор
языкаSQL.
Отдельные
команды SQL могут
быть введены
в
интерпретатор
и тут же
выполнены.
Гораздо чаще
приходится
иметь дело с
программами
на одном из
базовых языков,
которые
содержат
фрагменты
кода SQL.
7.1.
SQL
в среде
программирования
Существует
необходимость
согласования
кода
написанного
на базовом
языке и кода SQL.
Различные
типы данных. SQL
не
поддерживает
операторы
ветвления,
циклов и т.п. SQL –
мощное
высокоуровневое
средство
манипуляции
данными, вся
ответственность
за реализацию
особенностей
хранения и
обработки
данных СУБД
берут на
себя.
Несколько
способов
использования
SQL:
·
Внедренный
SQL
·
Использование
сохраненных
процедур
·
Использование
интерфейсов
вызова (ODBC, JDBC,
ADO)
7.1.1.
Курсоры
Наиболее
удобный и
универсальный
способ связан
с механизмом
курсоров.
Курсоры
позволяют
последовательно
просматривать
кортежи отношения.
После
объявления
курсора и
выполнения
инструкции
извлечения в
курсор будет
указывать на
кортеж с
данными.
Курсор –
ссылочный
тип.
7.2.
Хранимые
процедуры и
функции
SQL/PSM (persistent stored modules – постоянно хранимые модули). Некоторые
СУБД
позволяют
написание и
сохранение в
схеме базы
данных
процедур
написанных
на простом
языке общего
назначения.
Такие
процедуры
позволяют
вызывать
другие
процедуры и
функции, в
том числе и себя,
т.е.
осуществлена
поддержка
рекурсивных
вызовов.
CALL
<имя
процедуры>
(<список
аргументов>)
RETURN
<выражение> -
возврат
значения
DECLARE
<имя> <тип> -
объявление
переменой
SET
<переменная>
= <выражение> -
присваивание
переменной
BEGIN END
– блоки кода
7.2.1.
ветвления
IF <
условие > THEN
<список
выражений>
ELSEIF
<условие> THEN
<список
выражений>
ELSE
<список
выражений>
END IF
7.2.2.
циклы
LOOP
END LOOP
FOR <имя запрса> AS <имя курсора> CURSOR FOR
<запрос>
DO
<список
выражений>
END FOR
7.2.3.
Транзакции
START TRANSACTION
COMIT
ROLLBACK
8. Принципы
хранения
информации
8.1.
Иерархия
устройств
памяти
- Кэш
память
(Первичные
устройства
хранения)
- Оперативная
память
(Первичные
устройства
хранения)
- Жесткие
диски
(Вторичные
устройства
хранения)
- Третичные
устройства
хранения
8.1.1.
Кэш
память
Объемы
кэш памяти
порядка 1
Мбайт. Время
доступа 5-10 нс.
В любой
момент
времени
информации
из кэш памяти
отвечает
содержимое
определенного
участка ОЗУ.
При внесении
изменений в
кэш, данные
отражаются
обратно в
ОЗУ. По мере
необходимости
данные из
кэша
выгружаются
и на
освободившееся
место
загружаются
новые порции
данных.
8.1.2.
ОЗУ
Объемы
ОЗУ порядка 100
Мбайт. Время
доступа 10-100 нс.
ОЗУ
обеспечивает
произвольный
доступ к данным.
Это означает,
что для
получения
любого байта
из ОЗУ
затрачивается
одно и тоже
время.
8.1.3.
Виртуальная
память
Виртуальная
память.
Компьютеры
адресуют 4 Гбайта,
однако объем
ОЗУ
значительно
меньше.
Виртуальная
память
располагается
на жестком
диске в виде
файла. По
мере
необходимости
происходит
страничный
обмен (4-56 Кбайт)
между ОЗУ и
жестким
диском.
8.1.4.
Вторичные
устройства
хранения
Всякого
рода
дисковые
устройства –
магнитные ,
оптические и
магнитооптические
диски. Диски
выполняют
поддержку
виртуальной
памяти и
поддержку
файловой
системы.
Блочный
обмен.
СУБД
как правило
выполняют
манипуляцию
с данными в
обход
операционной
системы.
Время
доступа 10-30 мс.
Возникает
ситуация,
когда
затраты на
чтение
блоков
значительно
превышают
операции по
обработке
этих самых
блоков.
Емкости
порядка 100-1000 Гб.
8.1.5.
Третичные
устройства
Объемы
данных со
спутников
исчисляются
петабайтами
(10^15).
Специализированные
массивы.
Типы
устройств:
1) магнитные
ленты
устанавливаемые
по
требованию.
Оператор устанавливает
ленту в
привод.
2) Автоматические
приводы
оптических
дисков CD/DVD
3) Ленточные
бункеры
Средняя
емкость
ленты – 50 Гб. CD-700
Мб. DVD
– 2.5, 4.9 Гб.
Время
доступа
таких
устройств – 10-100 с.
8.2.
Диски
Блок
дисков, блок
головок.
Пластины,
шпиндель.
Дорожки. Секторы
разделенные
немагнитными
зазорами.
Сектор –
минимальная
физическая
единица чтения/записи.
Блоки – логическая
единица. Один
блок =
несколько
секторов, но
и один сектор
= несколько
блоков.
5400 об./мин.
1-2 пластины
до 15
до 20000
дорожек
до 500
секторов
1
Мб/дорожку
1-4
Кб/сектор
8.2.1.
контроллер
дисков
управление
исполнительным
приводом
выбор
пластины и
сектора
передача
данных в ОЗУ
и обратно
8.3.
использование
вторичных
устройств
хранения
Быстродействие
СУБД
обуславливается
числом
операций
доступа к
диску.
Минимизация
обращений к
диску.
Кэширование
данных в ОЗУ.
8.3.1.
Сортировка
Сортировка
слиянием
Двухфазная
сортировка
8.3.2.
Использование
нескольких
дисковых
устройств
Увеличение
пропускной
способности
за счет
распараллеливания
операций
чтения/записи.
Зеркалирование
– повышение
надежности. Увеличение
скорости
чтения.
Алгоритм
лифта –
упорядочивание
дисковых
операций.
Крупномасштабная
буферизация.
8.4.
Отказы
дисковых
устройств
Перемежающиеся
отказы –
возникают
редко. При
повторе
операцию
удается
повторить.
Отказ
записи –
из-за сбоев в
питании
Разрушение
носителя –
отдельные
секторы приходят
в негодность.
Полный
отказ диска –
дальнейшая
эксплуатация
диска
невозможна
Биты
индикации.
Контрольные
суммы
RAID
(Redundant Array of
Inexpensive Disks –
резервированный
массив
независимых
дисков):
0-распараллеливание
1-зеркалирование
4-доплнительный
диск для
хранения
контрольных
битов
5-функции
резервирования
распределены
между дисками
с целью
снижения
нагрузки
6-функции
исправления
в случае
отказа более
одного диска.
Блоки
четности
Коды
Хэмминга
9.
Представление
элементов
данных
Атрибуты
отображаются
в виде
последовательности
байт – полей (fields).
Поля в свою
очередь
объединяются
в записи (record) и
соответствуют
кортежам
данных или
объектам.
Записи
объединяются
в коллекции
блоков,
называемых
файлами.
9.1.
Представление
элементов
данных
Численные
значения
Значения
атрибутов
таких типов
как INTEGER,
FLOAT и
т.п. хранятся
в виде
последовательностей
1, 2, 4, или 8 байт в
зависимости
от типа.
Данные представляются
в той форме,
которую
поддерживает
математический
блок
процессора.
Это
позволяет
без лишних
преобразований
производить
необходимые
вычисления.
Строки
Строки
постоянной
длинны,
хранятся в
виде последовательности
байт;
количество
байт
определяется
максимальным
размером строки.
Лишние
символы
заполняются
специальным
незначащим
символом,
8-битовый код
которого не
совпадает ни
с одним из
тех, что допустимо
использовать
в строках SQL
CHAR(5) = ‘123’ = 123ڤڤ
Строки
переменной
длинны
Две
стратегии:
4) Длинна +
содержимое
5) Содержимое
+ символ
конца строки
Даты
Даты
могут хранится
как в виде
строк, так и в
числовом
формате (Григорианский,
UNIX timestamp)
Битовые
последовательности
упаковываются
в байты
9.2.
записи
Каждой
записи
соответствует
схема. Схема содержит
описание
полей – типы
данных, название
атрибутов, а
также
величина
смещения от
начала
записи.
9.2.1.
Записи
постоянной
длинны
Когда все
поля
обладают постоянной
длинной,
запись можно
получить
простым смещением
полей.
Архитектура
32-разрядного
процессора
позволяет
считывать
данные
эффективней,
если элементы
данных
записаны с
определенным
смещением от
начала блока.
Так, целые
числа должны
быть
записаны по
адресам кратным
4. Числа с
плавающей
точкой – 8.
СУБД учитывают
эти
особенности.
9.2.2.
Заголовки
записей
Записи
зачастую
снабжают
дополнительной
информацией:
1)
данные о
схеме записи
(указатель)
2)
сведения
об общей
длине записи
3)
данные о
моменте
обновления
или вставки записи
9.2.3.
группирование
записей в
блоки
Записи
хранятся в
дисковых
блоках.
Структура
блока:
Блок
может быть
снабжен
заголовком,
способным
хранить
следующую
информацию:
1)
ссылки
на один или
несколько
блоков, являющихся
частью более
высоких
единиц
2)
сведения
о функции
выполняемой
блоком
3)
данные о
том, кортежи
какого
отношения
хранятся в
блоке
4)
таблицу
со
значениями
смещений
записей
5)
идентификатор
блока
6)
данные о
последнем
обращении к
блоку
9.3.
элементы
данных и
записи
переменной
длинны
Существуют
ситуации,
когда записи
могут
обладать
различными размерами:
1)
Элементы
данных
переменного
размера
2)
Повторяющиеся
поля
3)
Записи
переменного
формата
4)
Поля
типа BLOB
9.3.1.
Записи
с полями
переменной
длины
Эффективен
способ, когда
все поля
постоянной
длинны,
хранятся в
начале записи,
а переменной
в конце.
Заголовок
записи в этом
случае
должен
хранить
следующие
данные:
1)
значение
длинны
записи
2)
адреса
первых
байтов полей
переменной
длинны. Адрес
первого поля
переменной
длинны,
определяется
группой
полей, с
постоянной
длинной.
9.3.2.
Записи
с повторяющимися
полями
Если
необходимо
хранить
некоторое
переменное
количество
полей фиксированной
длинны,
нужно:
1)
объединить
поля в группу
2)
в
заголовок
записи
включить
информацию о начале
группы (S)
3)
в
заголовок
включить
информацию о
размере
группы.
Смещение
для поля k равно S+k*L.
Альтернативный
способ
хранения
состоит в том
что в записи
сохраняются
только
указатели и
размеры
полей
переменной
длинны. А
сами данные
хранятся в
дополнительном
пространстве.
9.3.3.
Записи
переменного
формата
В записи
сохраняется
не только
смещения и
размер
данных, но и
мета данные –
имя поля, тип
данных,
длинна поля и
собственно
данные.
9.3.4.
Записи
крупного
объема
Чтобы
иметь
возможность
хранить данные
которые
превышают
размеры
блоков, или
хранить
данные более
эффективно
(неиспользуемое
пространство),
необходимо
иметь
механизм,
который
позволяет
хранить в
блоках
фрагменты записей.
Такие
записи
называют
связанными.
Каждый фрагмент
связанной
записи
должен
включать в
себя
заголовок:
1)
Флаг,
который
сигнализирует
о том, что
запись
является
связанной
2)
Флаги
конца и
начала
записи
3)
Указатели
на
предыдущий и
следующий
блок.
9.4.
Модификация
записей
9.4.1.
вставка
Для
вставки
новой записи
достаточно
найти блок со
свободным
местом
подходящего
размера.
Отношения с
произвольным
следованием
записей.
В
противном
случае системе
необходимо
найти блок, в
который
должна
вставляться
запись. Если
место в блоке
отсутствует,
то система
должна
попробовать сдвинуть
записи в
блоке, чтобы
найти место. Если
и в этом
случае места
недостаточно,
то система
должна:
1)
найти
место в
ближайшем блоке
и сдвинуть
записи в этот
блок, тем
самым
освободить
место в
целевом
блоке
2)
создать
блок
переполнения
(overflow block)
и разместить
информацию
в нем
9.4.2.
удаление
При
удалении
записей
удаляется
указатель на
запись из
таблицы
смещений
блока либо запись
помечается
как
удаленная.
Единственная
проблема
заключается
в том, что
возможно
существование
внешних указателей
на удаляемую
запись.
Проблема
решается
размещением
специального
признака-обелиска.
Расположение
этого
признака – в заголовке
записи. При
удалении
записи этот
признак
устанавливается,
а оставшаяся
часть записи
может
использоваться
для хранения
новых порций
данных.
9.4.3.
Обновление
данных
Обновление
записей постоянной
длинны не
вызывает
особых
проблем.
Если
обновление
данных
приводит к
увеличению
записей,
система
сталкивается
с теми же
проблемами
что и при
вставке –
нужно искать
свободное
место под
запись. Уменьшении
размера
записи
приводит к
тем же
эффектам, что
и удаление.