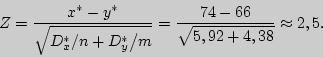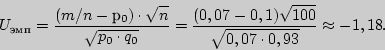|
Раздел 5. Проблема статистического вывода
Статистические гипотезы
На разных этапах статистического исследования
возникает необходимость в формулировании и экспериментальной
проверке некоторых предположительных утверждений (гипотез).Статистической называют
гипотезу о виде неизвестного распределения или о параметрах
известных распределений. Выдвигается основная (нулевая) гипотеза
В результате статистической проверки гипотезы могут
быть допущены ошибки двух родов. Ошибка
первого рода состоит
в том, что будет отвергнута правильная гипотеза; вероятность
совершить такую ошибку обозначают
Процедура обоснованного сопоставления высказанной
гипотезы с имеющейся выборкой осуществляется с помощью того или
иного статистического критерия и называется статистической проверкой
гипотез. Под критической
областью понимают
совокупность значений критерия, при которых нулевую гипотезу Статистические критерии проверки гипотез разнообразны, но у них единая логическая схема построения, которую представим на рис. 103.
1. Сравнение двух дисперсий нормальных генеральных
совокупностей. При
заданном уровне значимости
В качестве критерия проверки нулевой гипотезы
принимают случайную величину отношения большей исправленной
дисперсии к меньшей
Пример 1. Исследование длительности оборотных средств двух групп предприятий (по 13 предприятий в каждой) дало следующие результаты:
Можно ли считать, что отклонения в длительности оборота оборотных средств групп предприятий одинаковы для уровня значимости 0,1?
Решение. В этой задаче надо проверить нулевую
гипотезу
По таблице приложения 6 по уровню значимости для
двусторонней критической области
Пример 2. Школьникам давались обычные арифметические задачи, а потом одной случайно выбранной половине учащихся сообщалось, что они не выдержали испытания, а остальным - обратное. Затем у каждого из них спрашивали, сколько секунд ему потребуется для решения новой задачи. Экспериментатор, вычисляя разность между определенным временем решения задачи, которое называл школьник, и результатами ранее выполненного задания, получил следующие данные:
Проверьте на уровне значимости 0,01 гипотезу о том, что дисперсия совокупности детских оценок, имеющих отношение к оценке их возможностей, не зависит от того, что сообщалось детям о плохих результатах испытаний или об удачном решении первой задачи.
Решение. Применим критерий Фишера-Снедекора для
нулевой гипотезы
Критическую точку находим в приложении для уровня
значимости
2. Сравнение двух средних нормальных генеральных совокупностей с известными дисперсиями. Проверяется нулевая гипотеза о равенстве генеральных средних рассматриваемых совокупностей с заданными или вычисляемыми дисперсиями. В качестве критерия проверки нулевой гипотезы примем случайную величину
Пример 3. Производительность двух моторных заводов, выпускающих дизельные двигатели, характеризуется следующими данными:
Можно ли считать одинаковыми производительности
дизельных двигателей на обоих заводах при уровне значимости Решение. Найдем выборочные числовые характеристики данных независимых выборок:
По условию, конкурирующая гипотеза имеет вид Найдем критическую точку:
по таблице функции Лапласа (прил. 2) находим
Так как
3. Сравнение выборочной средней с гипотетической
генеральной средней нормальной совокупности. По
выборочной средней при заданном уровне значимости проверяется
нулевая гипотеза
которая распределена нормально.
Пример 4. Из
нормальной генеральной совокупности с известным средним
квадратическим отклонением Решение. Найдем наблюдаемое значение критерия:
Найдем критическую точку двусторонней критической области:
и по таблице функции Лапласа находим
Поскольку
4. Сравнение наблюдаемой относительной частоты с
гипотетической вероятностью появления события. При
заданном уровне значимости В качестве критерия проверки нулевой гипотезы принимаем случайную величину
Пример 5. По
100 независимым испытаниям найдена относительная частота 0,07. При
уровне значимости 0,05 проверить нулевую гипотезу Решение. Найдем наблюдаемое значение критерия:
Учитывая, что критическая область двусторонняя,
находим
По таблице функции Лапласа (прил. 2) находим
Поскольку Вопросы для самоконтроля
Задачи
По двум независимым выборкам, объемы которых
По двум независимым выборкам, объем которых
Проведено исследование розничного товарооборота
продовольственных магазинов в двух районах Ярославской области (по
20 магазинов в каждом). Априори известны средние значения розничного
товарооборота - 78,8 и 78,56 тыс. руб. Полученные в результате
оценки средних квадратичных отклонений в первом и втором районах
соответственно равны 7,2 и 7,8 тыс. руб. Можно ли считать, что
разброс розничного товарооборота магазинов в районах неодинаков при
уровне значимости
По выборке объема
Исследование пропусков по болезни детей в двух
группах детского сада в течение года (по 16 детей в каждой группе)
дало следующие результаты:
Можно ли считать, что среднее количество дней
пропусков по болезни в обеих группах одинаково при уровне значимости
Из нормальной генеральной совокупности с известным
средним квадратическим отклонением
Из двух партий изделий, изготовленных на двух
одинаково настроенных станках, известны малые выборки, объемы
которых
Проверьте нулевую гипотезу о равенстве средних размеров изделий при уровне значимости 0,05.
По 100 независимым испытаниям найдена относительная
частота В банке в течение двух дней проводилось исследование времени обслуживания клиентов, данные которого представлены в таблице:
Можно ли считать одинаковыми отклонения от среднего
времени обслуживания клиентов банка в 1-й и 2-й дни при
За смену отказали 20 элементов первого устройства,
состоящего из 800 элементов, и 30 элементов второго, состоящего из
1000 элементов. При уровне значимости
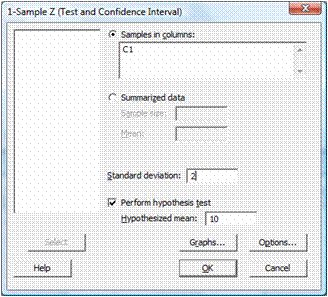
Любое недоказанное утверждение или догадку можно считать гипотезой. Статистическая гипотеза является предположением об одном или нескольких параметрах функции распределения случайной величины. К примеру, можно предположить, что генеральная совокупность данных распределена согласно нормальному закону или две выборки принадлежат двум разным популяциям, или различие между дисперсиями двух выборок статистически незначимо и т.д. Статистические гипотезы проверяются на основании выборочных опытов/наблюдений. Поэтому вероятность той или иной гипотезы никогда не может быть принята однозначно равной 0 или 1. Вместо этого используются допустимые уровни вероятности: α и 1-α (или β). В практике статистического анализа чаще всего имеют дело с двумя конкурирующими гипотезами: нулевой гипотезой, обозначаемой H0, и альтернативной гипотезой, обозначаемой Hα или H1. Нулевая гипотеза – это утверждение, подлежащее проверке. Альтернативная гипотеза – это противоположное утверждение, которое мы пытаемся опровергнуть в ходе анализа. В зависимости от величины вероятности альтернативная гипотеза может быть принята либо отвергнута. Нулевая гипотеза может быть отвергнута, но не принята! В случае высокого уровня вероятности правдивости нулевой гипотезы, говорят, что гипотеза не может быть отвергнута. Принятие решений о генеральной совокупности на основе выборочных данных приводит к возможности постановки неправильного вывода. Различают два вида ошибок, связанных с постановкой вывода на основе выборочных данных: · Ошибка первого рода – возникает, когда отвергается нулевая гипотеза, при этом являясь правильной. · Ошибка второго рода – возникает, когда принимается нулевая гипотеза, при этом являясь ложной. Чем ниже показатель α (вероятность ошибки первого рода), тем больше уверенность в правдивости нулевой гипотезы и наоборот. В качестве примера наблюдений для проверки статистических гипотез используем набор из 100 значений со средним 10 и стандартным отклонением 2, сгенерированных программой Minitab 16. Рабочий файл, содержащий набор значений и результаты анализа, прикреплен к статье и доступен для всех зарегистрированных пользователей. В меню Stat выберите Basic Statistics, а затем тест, необходимый для проверки статистической гипотезы. Используем 1-Sample Z… так как и закон распределения и стандартное отклонение нам известны (оба параметра заданы при генерации данных). В появившемся окне внесем следующие настройки:
1.
В поле Samples in columns:
укажите диапазон анализируемых данных (C1 в данном случае)
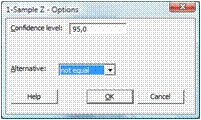
4. Нажав на Graphs… можно выбрать три вида диаграмм, которые будут построены вместе с проверкой гипотезы – установите флажок напротив каждой их них:
5. В меню Options… можно установить доверительный интервал (1 – α, по умолчанию установлено значение 95%) и альтернативную гипотезу – выберите "not equal” (не равно):
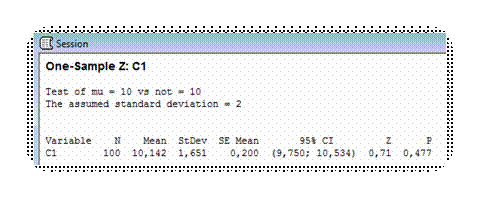
После внесения всех настроек, нажмите OK и перейдите в окно Session:
Интерпретация полученных результатов: · Variable – столбец переменных · N – число наблюдаемых значений · Mean – среднее арифметическое значение · StDev – стандартное отклонение. · SE Mean – средняя стандартизированная ошибка · 95% CI – доверительный интервал · Z – Z-значение, используется для расчета Р · P – вероятность Наибольший интерес, из полученных результатов, представляет величина Р – вероятность того, что нулевая гипотеза может быть принята. Для постановки вывода следует сравнить величину Р с α-уровнем: · Если Р ≤ α, то нулевая гипотеза отвергается и принимается альтернативная. · Если Р > α, то альтернативная гипотеза отвергается. В таком случае говорят, что нулевая гипотеза не может быть отвергнута – несмотря на то, что альтернативная отвергнута, нулевую гипотезу никогда не принимают. α-уровень задается исследователем при настройке доверительного интервала: доверительный интервал равен 1 – α. Следовательно, при значении доверительного интервала 95%, α-уровень равен 5%. Для проверки статистической гипотезы можно задать любое значение α-уровня от 0 до 1, на чаще всего используют величину 0,05 или 5%. В рассмотренном случае значение Р составляет 0,477, при этом α-уровень – 0,05, соответственно с большой долей вероятности можно утверждать, что нулевая гипотеза не может быть отвергнута: среднее арифметическое значение наблюдаемых результатов равно 10. Ниже представлены, полученные в ходе проверки гипотез, диаграммы:
Фактически показания диаграмм идентичны: расчетное значение попадает в пределы доверительного интервала и близко к 10. Разница между диаграммами состоит лишь в способе отображения распределения наблюдаемых значений: гистограмма, точечная или ящичная диаграммы.
Статистическая мощность (реже "чувствительность") (англ. statistical power) - это вероятность того, что тот или иной статистический критерий правильно отклонит неверную нулевую гипотезу. Иными словами - это способность критерия обнаружить различия там, где они действительно существуют. Обычно процесс проверки статистической гипотезы включает следующие шаги: · Формулировка собственно проверяемой нулевой гипотезы. Например, в случае двухвыборочного критерия Стьюдента она состоит в том, что обе выборки происходят из нормально распределенных генеральных совокупностей с одинаковыми средними значениями (подробнее см. здесь). · Выбор подходящего статистического критерия для проверки нулевой гипотезы. Вычисление значения этого критерия по имеющимся выборочным данным. · Определение критического значения критерия, исходя из желаемого уровня статистической значимости αи свойств теоретического распределения этого критерия. · Проверка того, превышает ли рассчитанный по выборочным данным критерий критическое значение. Если такое превышение не наблюдается, делают вывод о том, что нулевая гипотеза верна.
· Ошибка первого типа (= "первого рода"): отклонение верной нулевой гипотезы. Риск совершить такую ошибку равен выбранному уровню значимости (например, α=0.05). · Ошибка второго типа (= "второго рода"): сохранение неверной нулевой гипотезы. Вероятность ошибочно сохранить неверную нулевую гипотезу обозначают буквой β. Таким образом, прежде чем сделать вывод об остутствии различий, исследователь должен выяснить, была ли мощность использованного статистического критерия достаточной для их обнаружения. Уровень β-риска тесно связан с 1) величиной различий между выборками (т.н. "величиной эффекта"), 2) числом наблюдений и 3) разбросом данных. Наиболее важным является число наблюдений: чем больше размер выборок, тем выше мощность теста. При "достаточно" больших выборках даже небольшие различия окажутся статистически значимыми. И наоборот - при малых выборках даже большие различия выявить будет трудно. Зная эти закономерности, мы можем заранее (т.е. до проведения исследования) определить минимальный размер выборок, необходимый для выявления эффекта. На практике обычно (но не всегда) приемлемой считается мощность теста, равная или превышающая 80% (что соответствует β-риску в 20%). Этот уровень является следствием т.н. "соотношения 1 к 4" (англ. "one-to-four trade-off") между уровнями α-риска и β-риска: если принять уровень значимости α=0.05, тогда β=0.05×4=0.20и мощность критерия составит Π=1−0.20=0.80. При проведении вычислений, связанных с мощностью критерия Стьюдента, нам придестя оперировать следующими параметрами: · Величина эффекта, которую мы хотим выявить в ходе исследования ("дельта", т.е. разница между средними значениями сравниваемых выборок). · Стандартное отклонение (предполагается, что оно статистически не различается в сравниваемых выборках). · Уровень значимости, α. · Мощность критерия (обычно выражается в %). · Объем выборки
В качестве примера предположим, что мы планируем проведение эксперимента для установления эффекта температуры на индивидуальный вес водного жука. В эксперименте будут задействованы два температурных режима и, соответственно, установление эффекта температуры мы будем проверять, сравнивая средние значения веса жуков из двух экспериментальных групп при помощи двустороннего критерия Стьюдента (двусторонний вариант выбран потому, что до проведения эксперимента мы не знаем, каков именно эффект окажет повышение температуры - повышение или понижение веса жуков). Проверяемая в данном случае нулевая гипотеза состоит в том, что температура не оказывает никакого влияния на вес жуков.
Допустим, что минимальная разница в среднем весе жуков, которую мы
хотим выявить в ходе эксперимента, составляет 3 мг. При уровне
значимости α=0.05 желаемая
мощность теста должна составить 80%. Вопрос заключается в том,
сколько животных мы должны задействовать в эксперименте для того,
чтобы перечисленные условия были выполнены. Как следует из
приведенного выше списка, для определения оптимального размера
выборки нам необходимо знать стандартное отклонение веса изучаемого
вида жуков. К сожалению, до проведения эксперимента мы не можем
точно оценить этот параметр. Вариантов решения этой проблемы два: 1)
основываясь на своем экспертном мнении, исследователь может дать примерную оценку
стандартного отклонения; 2) можно попытаться найти соответствующие литературные
данные. Предположим, что мы воспользовались вторым вариантом и
выяснили, что стандартное отклонение веса для изучаемого вида жуков
составляет 1.8 мг.
power.t.test(delta = 3.0, sd = 1.8, sig.level = 0.05,
power = 0.8)
Two-sample t test power calculation
n = 6.76095
delta = 3
sd = 1.8 sig.level = 0.05
power = 0.8 alternative = two.sided
NOTE: n is number in *each* group
В приведенной выше команде delta - минимальная величина эффекта, которую мы хотим обнаружить в ходе эксперимента, sd - стандартное отклонение веса жуков (по литературным данным), sig.level - уровень значимости, а power - мощность t-критерия. В результатах вычислений программа еще раз перечисляет имеющиеся исходные параметры, а также сообщает n - рассчитанный минимальный размер каждой выборки для обнаружения желаемого эффекта при этих параметрах (округлив, получаем 7 жуков в каждой экспериментальной группе). Кроме того, программа напоминает нам, что вычисления были выполнены для двустроннего критерия Стьюдента (alternative = two.sided) и что параметр n соответствует числу наблюдений в каждой группе (n is number in *each* group).
power.t.test(n = 15, delta = 3.0,
sd = 1.8, sig.level = 0.05)
Two-sample t test power calculation
n = 15
delta = 3
sd = 1.8 sig.level = 0.05
power = 0.9927162 alternative = two.sided
NOTE: n is number in *each* group
power.t.test(delta = 3.0, sd = 1.8, sig.level = 0.05,
power = 0.8, type = "paired")
Paired t test power calculation
n = 5.04919
delta = 3
sd = 1.8 sig.level = 0.05
power = 0.8 alternative = two.sided
NOTE: n is number of *pairs*, sd is std.dev. of *differences* within pairs
power.t.test(delta = 3.0, sd = 1.8, sig.level = 0.05,
power = 0.8, type = "one.sample")
One-sample t test power calculation
n = 5.04919
delta = 3
sd = 1.8 sig.level = 0.05
power = 0.8 alternative = two.sided
|