|
10. Протоколы межсетевой маршрутизации |
||
|
Библиографическая справка Протокол Информации Маршрутизации
(RIP) является протоколом маршрутизации, который был первоначально разработан
для Универсального протокола PARC Xerox (где он
назывался GWINFO) и использовался в комплекте протоколов ХNS. RIP начали
связывать как с UNIX, так и с TCP/IP в 1982 г., когда версию UNIX, называемую Berkeley Standard Distribution (BSD), начали отгружать с одной из реализацией
RIP, которую называли "трассируемой" (routed)
(слово произносится "route dee").
Протокол RIP, который все еще является очень популярным протоколом
маршрутизации в сообществе Internet, формально
определен в публикации "Протоколы транспортировки Internet"
XNS (XNS Internet Transport
Protocols ) (1981 г.) и в Запросах для комментария ( Request for Comments - RFC) 1058 (1988 г.). RIP был повсеместно принят
производителями персональных компьютеров (РС) для использования в их изделиях
передачи данных по сети. Например, протокол маршрутизации AppleTalk
(Протокол поддержания таблицы маршрутизации - RTMP) является модернизированной
версией RIP. RIP также явился базисом для протоколов Novell,
3Com, Ungermann-Bass и Banyan.
RIP компаний Novell и 3Com в основном представляет
собой стандартный RIP компании Xerox. Ungermann-Bass и Banyan внесли
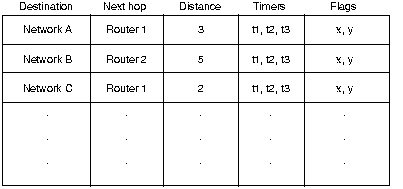
незначительные изменения в RIP для удовлетворения своих нужд. Каждая запись данных в таблице
маршрутизации RIP обеспечивает разнообразную информацию, включая конечный пункт
назначения, следующую пересылку на пути к этому пункту назначения и показатель ( metric ). Показатель
обозначает расстояние до пункта назначения, выраженное числом пересылок до
него. В таблице маршрутизации может находиться также и другая информация, в том
числе различные таймеры, связанные с данным маршрутом. Типичная таблица
маршрутизации RIP показана на
Рис. 5.1.
RIP поддерживает только самые лучшие
маршруты к пункту назначения. Если новая информация обеспечивает лучший
маршрут, то эта информация заменяет старую маршрутную информацию. Изменения в
топологии сети могут вызывать изменения в маршрутах, приводя к тому, например,
что какой-нибудь новый маршрут становится лучшим маршрутом до конкретного
пункта назначения. Когда имеют место изменения в топологии сети, то эти
изменения отражаются в сообщениях о корректировке маршрутизации. Например,
когда какой-нибудь роутер обнаруживает отказ одного из каналов или другого
роутера, он повторно вычисляет свои маршруты и отправляет сообщения о
корректировке маршрутизации. Каждый роутер, принимающий сообщение об обновлении
маршрутизации, в котором содержится изменение, корректирует свои таблицы и
распространяет это изменение. На
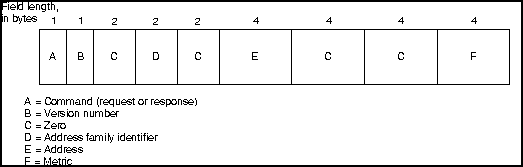
Рис. 5.2 изображен формат пакета RIP для
реализаций IP так, как он определен в RFC 1058. ПРИМЕЧАНИЕ: На
Рис. 5.2 представлен формат RIP,
используемый для сетей IP в Internet. В некоторые
другие варианты RIP внесены незначительные изменения формата и (или) имен
файлов, которые здесь перечислены, но функциональные возможности базового
алгоритма маршрутизации те же самые.
Первое поле в пакете RIP-это поле
команд (command). Это поле содержит целое
число, обозначающее либо запрос, либо ответ. Команда "запрос" запрашивает
отвечающую систему об отправке всей таблицы маршрутизации или ее части. Пункты
назначения, для которых запрашивается ответ, перечисляются далее в данном
пакете. Ответная команда представляет собой ответ на запрос или чаще всего
какую-нибудь незатребованную регулярную корректировку маршрутизации. Отвечающая
система включает всю таблицу маршрутизации или ее часть в ответный пакет.
Регулярные сообщения о корректировке маршрутизации включают в себя всю таблицу
маршрутизации. Поле версии ( version ) определяет реализуемую версию RIP.
Т.к. в объединенной сети возможны многие реализации RIP, это поле может быть
использовано для сигнализирования о различных
потенциально несовместимых реализациях. За 16-битовым полем, состоящим из
одних нулей, идет поле идентификатора семейства адресов ( аddress family identifier ). Это поле
определяет конкретное используемое семейство адресов. В сети Internet (крупной международной сети, объединяющей
научно-исследовательские институты, правительственные учреждения, университеты
и частные предприятия) этим адресным семейством обычно является IP ( значение=2 ), но могут быть также представлены другие типы
сетей. Следом за еще одним 16-битовым
полем, состоящим из одних нулей, идет 32-битовое поле адреса (
address ). В реализациях RIP Internet это поле обычно содержит какой-нибудь адрес IP. За еще двумя 32-битовыми полями из
нулей идет поле показателя RIP ( metric
). Этот показатель представляет собой число пересылок ( hop count ).
Он указывает, сколько должно быть пересечено транзитных участков (роутеров)
объединенной сети, прежде чем можно добраться до пункта назначения. В каждом отдельном пакете RIP IP
допускается появление дo 25 вхождений идентификатора
семейства адреса, обеспечиваемых полями показателя. Другими словами, в каждом
отдельном пакете RIP может быть перечислено до 25 пунктов назначения. Для
передачи информации из более крупных маршрутных таблиц используется множество
пакетов RIP. Как и другие протоколы
маршрутизации, RIP использует определенные таймеры для регулирования своей
работы. Таймер корректировки маршрутизации RIP ( routing update timer ) обычно устанавливается на 30 сек., что
гарантирует отправку каждым роутером полной копии своей маршрутной таблицы всем
своим соседям каждые 30 секунд. Таймер недействующих маршрутов ( route invalid timer ) определяет,
сколько должно пройти времени без получения сообщений о каком-нибудь конкретном
маршруте, прежде чем он будет признан недействительным. Если какой- нибудь маршрут признан недействительным, то соседи уведомяются об этом факте. Такое уведомление должно иметь
место до истечения времени таймера отключения маршрута ( route flush timer ). Когда заданное время таймера отключения маршрута
истекает, этот маршрут удаляется из таблицы маршрутизации. Типичные исходные
значения для этих таймеров - 90 секунд для таймера недействующего маршрута и
270 секунд для таймера отключения маршрута.
10.2
IGRP
Протокол
маршрутизации внутренних роутеров (Interior Gateway Routing Protocol-IGRP) является
протоколом маршрутизации, разработанным в середине 1980 гг. компанией Cisco Systems, Inc. Главной целью, которую преследовала Cisco при разработке IGRP, было
обеспечение живучего протокола для маршрутизации в пределах автономной системы
(AS), имеющей произвольно сложную топологию и включающую в себя носитель с
разнообразными характеристиками ширины полосы и задержки. AS является набором
сетей, которые находятся под единым управлением и совместно используют общую стратегию
маршрутизации. Обычно AS присваивается уникальный 16-битовый номер, который
назначается Центром Сетевой Информации ( Network
Information Center - NIC
) Сети Министерства Обороны ( Defence Data Network - DDN ). В середине 1980 гг. самым
популярным протоколом маршрутизации внутри AS был Протокол Информации
Маршрутизации (RIP). Хотя RIP был вполне пригоден для маршрутизации в пределах
относительно однородных объединенных сетей небольшого или среднего размера, его
ограничения сдерживали рост сетей. В частности, небольшая допустимая величина
числа пересылок (15) RIP ограничивала размер объединенной сети, а его
единственный показатель (число пересылок) не обеспечивал достаточную гибкость в
сложных средах (смотри пункт "RIP"). Популярность роутеров Cisco и живучесть IGRP побудили
многие организации, которые имели крупные объединенные сети, заменить RIP на IGRP. Первоначальная реализация IGRP компании Cisco работала в
сетях IP. Однако IGRP был предназначен для работы в
любой сетевой среде, и вскоре Cisco распространила
его для работы в сетях использующих Протокол Сети без Установления Соединения ( Connectionless Network Protocol - CLNP )
OSI. Технология
IGRP
является протоколом внутренних роутеров (IGP) с
вектором расстояния. Протоколы маршрутизации с вектором расстояния требуют от
каждого роутера отправления через определенные интервалы времени всем соседним
роутерам всей или части своей маршрутной таблицы в сообщениях о корректировке
маршрута. По мере того, как маршрутная информация распространяется по сети,
роутеры могут вычислять расстояния до всех узлов объединенной сети. Протоколы маршрутизации с
вектором расстояния часто противопоставляют протоколам маршрутизации с
указанием состояния канала, которые отправляют информацию о локальном
соединении во все узлы объединенной сети. Рассмотрение двух популярных
протоколов, использующих алгоритм маршрутизации с указанием состояния канала,
"Открытый протокол с алгоритмом поиска наикратчайшего пути" ( Open Shortest Path First
) и "Промежуточная система-Промежуточная система" ( Intermediate System to Intermediate System (IS-IS) ), дается соответственно в пункты
"OSPF" и "Маршрутизация OSI". IGRP
использует комбинацию (вектор) показателей. Задержка объединенной сети ( internetwork delay ), ширина полосы ( bandwidth
), надежность ( reliability ) и нагрузка ( load ) - все эти показатели учитываются в виде
коэффициентов при принятии маршрутного решения. Администраторы сети могут
устанавливать факторы весомости для каждого из этих показателей. IGRP использует либо установленные администратором, либо
устанавливаемые по умолчанию весомости для автоматического расчета оптимальных
маршрутов. IGRP
предусматривает широкий диапазон значений для своих показателей. Например,
надежность и нагрузка могут принимать любое значение в интервале от 1 до 255,
ширина полосы может принимать значения, отражающие скорости пропускания от 1200
бит/с до 10 гигабит в секунду, в то время как задержка может принимать любое
значение от 1-2 до 24-го порядка. Широкие диапазоны значений показателей
позволяют производить удовлетворительную регулировку показателя в объединенной
сети с большим диапазоном изменения характеристик производительности. Самым
важным является то, что компоненты показателей объединяются по алгоритму,
который определяет пользователь. В результате администраторы сети могут
оказывать влияние на выбор маршрута, полагаясь на свою интуицию. Для обеспечения дополнительной
гибкости IGRP разрешает многотрактовую
маршрутизацию. Дублированные линии с одинаковой шириной полосы могут пропускать
отдельный поток трафика циклическим способом с автоматическим переключением на
вторую линию, если первая линия выходит из строя. Несколько трактов могут также
использоваться даже в том случае, если показатели этих трактов различны. Например,
если один тракт в три раза лучше другого благодаря тому, что его показатели в
три раза ниже, то лучший тракт будет использоваться в три раза чаще. Только
маршруты с показателями, которые находятся в пределах определенного диапазона
показателей наилучшего маршрута, используются для многотрактовой
маршрутизации. Открытый
протокол, базирующийся на алгоритме поиска наикратчайшего пути (Open Shortest Path
First - OSPF) является протоколом маршрутизации,
разработанным для сетей IP рабочей группой Internet Engineering Task Force (IETF), занимающейся разработкой протоколов для
внутрисистемных роутеров ( interior
gateway protocol - IGP
). Рабочая группа была образована в 1988 г. для разработки протокола IGP, базирующегося на алгоритме "поиска наикратчайшего
пути" ( shortest
path first - SPF ), с
целью его использования в Internet, крупной
международной сети, объединяющей научно-исследовательские институты,
правительственные учреждения, университеты и частные предприятия. Как и
протокол IGRP (смотри пункт "IGRP"), OSPF был разработан по той причине, что к
середине 1980 гг. непригодность RIP для обслуживания крупных гетерогенных
объединенных систем стала все более очевидна (смотри пункт "RIP"). ОSPF явился результатом научных
исследований по нескольким направлениям, включающим:
·
Алгоритм
SPF компании Bolt, Beranek и Newman (BBN), разработанный для Arpanet (программы с коммутацией пакетов,
разработанной BBN в начале 1970 гг., которая явилась
поворотным пунктом в истории разработки сетей) в 1978 г.
·
Исследования
Koмпании Radia Perlman по отказоустойчивости широкой рассылки маршрутной
информации (1988).
·
Исследования
BBN по маршрутизации в отдельной области (1986).
·
Одна
из первых версий протокола маршрутизации IS-IS OSI (Информация о IS-IS дается в
пункте "Maршрутизация OSI"). Как видно из его названия, OSPF
имеет две основных характеристики. Первая из них-это то, что протокол является
открытым, т.е. его спецификация является общественным достоянием. Спецификация
OSPF опубликована в форме Запроса для Комментария (RFC) 1247. Второй его
главной характеристикой является то, что он базируется на алгоритме SPF. Алгоритм SPF иногда
называют алгоритмом Dijkstra по имени автора,
который его разработал. Основы
технологии
OSPF является протоколом
маршрутизации с объявлением состояния о канале ( link-state
). Это значит, что он требует отправки объявлений о состоянии канала ( link-state
advertisement - LSA ) во все роутеры, которые
находятся в пределах одной и тойже иерархической
области. В oбъявления LSA
протокола OSPF включается информация о подключенных интерфейсах, об
использованных показателях и о других переменных. По мере накопления роутерами
OSPF информации о состоянии канала, они используют алгоритм SPF для расчета наикратчайшего пути к каждому узлу. Являясь алгоритмом с
объявлением состояния канала, OSPF отличается от RIP и IGRP,
которые являются протоколами маршрутизации с вектором расстояния. Роутеры,
использующие алгоритм вектора расстояния, отправляют всю или часть своей
таблицы маршрутизации в сообщения о корректировке маршрутизации, но только
своим соседям. Иерархия
маршрутизации
В отличие от RIP, OSPF может
работать в пределах некоторой иерархической системы. Самым крупным объектом в
этой иерархии является автономная система ( Autonomous System
- AS ) AS является набором сетей, которые находятся под единым управлением
и совместно используют общую стратегию маршрутизации. OSPF является протоколом
маршрутизации внутри AS, хотя он и способен принимать маршруты из других AS и
отправлять маршруты в другие AS. Любая AS может быть разделена
на ряд областей ( area
). Область - это группа смежных сетей и подключенных к ним хостов. Роутеры,
имеющие несколько интерфейсов, могут участвовать в нескольких областях. Такие
роутеры, которые называются роутерами границы областей ( area border routers ), поддерживают отдельные топологические базы
данных для каждой области. Топологическая база ( topological database ) данных фактически представляет собой общую
картину сети по отношению к роутерам. Топологическая база данных содержит набор
LSA, полученных от всех роутеров, находящихся в
одной области. Т.к. роутеры одной области коллективно пользуются одной и той же
информацией, они имеют идентичные топологические базы данных. Термин "домен" ( domain ) используется для
описания части сети, в которой все роутеры имеют идентичную топологическую базу
данных. Термин "домен" часто используется вместо AS. Топология области является
невидимой для объектов, находящихся вне этой области. Путем хранения топологий
областей отдельно, OSPF добивается меньшего трафика маршрутизации, чем трафик
для случая, когда AS не разделена на области. Разделение на области приводит
к образованию двух различных типов маршрутизации OSPF, которые зависят от того,
находятся ли источник и пункт назначения в одной и той же или разных областях.
Маршрутизация внутри области имеет место в том случае, когда источник и пункт
назначения находятся в одной области; маршрутизация между областями - когда они
находятся в разных областях. Стержневая часть OSPF ( backbone ) отвечает за
распределение маршрутной информации между областями. Она включает в себя все
роутеры границы области, сети, которые не принадлежат полностью какой-либо из
областей, и подключенные к ним роутеры. На
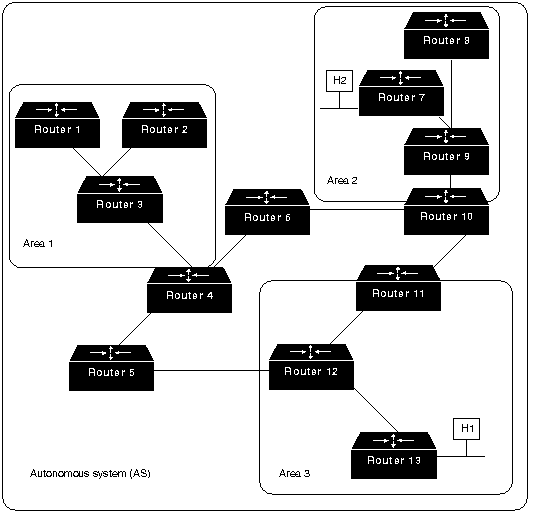
Рис.
5.6 представлен пример объединенной сети с несколькими областями.
На этом рисунке роутеры 4, 5,
6, 10, 11 и 12 образуют стержень. Если хост Н1 Области 3 захочет отправить пакет
хосту Н2 Области 2, то пакет отправляется в роутер 13, который продвигает его в
роутер 12, который в свою очередь отправляет его в роутер 11. Роутер 11
продвигает пакет вдоль стержня к роутеру 10 границы области, который отправляет
пакет через два внутренних роутера этой области (роутеры 9 и 7) до тех пор,
пока он не будет продвинут к хосту Н2. Сам стержень представляет собой
одну из областей OSPF, поэтому все стержневые роутеры используют те же
процедуры и алгоритмы поддержания маршрутной информации в пределах стержневой
области, которые используются любым другим роутером. Топология стержневой части
невидима для всех внутренних роутеров точно также, как топологии отдельных
областей невидимы для стержневой части. Область может быть определена
таким образом, что стержневая часть не будет смежной с ней. В этом случае
связность стержневой части должна быть восстановлена через виртуальные
соединения. Виртуальные соединения формируются между любыми роутерами
стержневой области, которые совместно используют какую-либо связь с любой из нестержневых областей; они функционируют так, как если бы
они были непосредственными связями. Граничные роутеры AS,
использующие OSPF, узнают о внешних роутерах через протоколы внешних роутеров (EGPs), таких, как Exterior
Gateway Protocol (EGP)
или Border Gateway
Protocol (BGP), или через информацию о
конфигурации (информация об этих протоколах дается соответственно в пунктах
"EGP" и "BGP"). Алгоритм
SPF
Алгоритм
маршрутизации SPF является основой для
операций OSPF. Когда на какой-нибудь роутер SPF
подается питание, он инициилизирует свои структуры
данных о протоколе маршрутизации, а затем ожидает индикации от протоколов
низшего уровня о том, что его интерфейсы работоспособны. После получения подтверждения о
работоспособности своих интерфейсов роутер использует приветственный протокол ( hello protocol ) OSPF, чтобы приобрести соседей ( neighbor ). Соседи - это роутеры с интерфейсами с
общей сетью. Описываемый роутер отправляет своим соседям приветственные пакеты
и получает от них такие же пакеты. Помимо оказания помощи в приобретении
соседей, приветственные пакеты также действуют как подтверждение
дееспособности, позволяя другим роутерам узнавать о том, что другие роутеры все
еще функционируют. В сетях с множественным
доступом ( multi-access networks )
(сетях, поддержиающих более одного роутера), протокол
Hello выбирает назначенный роутер ( designated router )
и дублирующий назначенный роутер. Назначеный роутер,
помимо других функций, отвечает за генерацию LSA для
всей сети с множественным доступом. Назначенные роутеры позволяют уменьшить
сетевой трафик и объем топологической базы данных. Если базы данных о состоянии
канала двух роутеров являются синхронными, то говорят, что эти роутеры смежные ( adjacent ). В сетях с
множественным доступом назначенные роутеры определяют, какие роутеры должны
стать смежными. Топологические базы данных синхронизируются между парами
смежных роутеров. Смежности управляют распределением пакетов протокола
маршрутизации. Эти пакеты отправляются и принимаются только на смежности. Каждый роутер периодически
отправляет какое-нибудь LSA. LSA
также отправляются в том случае, когда изменяется состояние какого- нибудь роутера. LSA включает в
себя информацию о смежностях роутера. При сравнении установленных смежностей с
состоянием канала быстро обнаруживаются отказавшие роутеры, и топология сети
изменяется сооответствующим образом. Из
топологической базы данных, генерируемых LSA, каждый
роутер рассчитывает дерево наикратчайшего пути, корнем которого является он
сам. В свою очередь дерево наикратчайшего пути выдает маршрутную таблицу. Формат
пакета
Все пакеты OSPF начинаются с
24-байтового заголовка, как показано на
Рис.
5.7.
Первое поле в заголовке OSPF -
это номер версии OSPF ( version
number ). Номер версии обозначает конкретную
используемую реализацию OSPF. За номером версии идет поле
типа ( type ).
Существует 5 типов пакета OSPF:
·
Hello Отправляется через регулярные
интервалы времени для установления и поддержания соседских взаимоотношений.
·
Database Description Описание базы данных. Описывает
содержимое базы данных; обмен этими пакетами производится при инициализации
смежности.
·
Link-State Request Запрос о состоянии канала.
Запрашивает части топологической базы данных соседа. Обмен этими пакетами
производится после того, как какой-нибудь роутер обнаруживает, (путем проверки
пакетов описания базы данных), что часть его топологической базы данных
устарела.
·
Link-State Update Корректировка состояния канала.
Отвечает на пакеты запроса о состоянии канала. Эти пакеты также используются
для регулярного распределения LSA. В одном пакете
могут быть включены несколько LSA.
·
Link-State Acknowledgement Подтверждение состояния канала.
Подтверждает пакеты корректировки состояния канала. Пакеты корректировки
состояния канала должны быть четко подтверждены, что является гарантией
надежности процесса лавинной адресации пакетов корректировки состояния канала
через какую-нибудь область. Каждое LSA
в пакете корректировки состояния канала содержит тип поля. Существуют 4 типа LSA:
·
Router links advertisements (RLA) объявления
о каналах роутера. Описывают собранные данные о состоянии каналов роутера,
связывающих его с конкретной областью. Любой роутер отправляет RLA для каждой
области, к которой он принадлежит. RLA направляются лавинной адресацией через
всю область, но они не отправляются за ее пределы.
·
Network links advertisements (NLA) объявления
о сетевых каналах. Отправляются назначенными роутерами. Они описывают все
роутеры, которые подключены к сети с множественным доступом, и отправляются
лавинной адресацией через область, содержащую данную сеть с множественным
доступом.
·
Summary links advertisements (SLA) Суммарные объявления о каналах.
Суммирует маршруты к пунктам назначения, находящимся вне какой-либо области, но
в пределах данной AS. Они генерируются роутерами границы области, и
отправляются лавинной адресацией через данную область. В стержневую область
посылаются объявления только о внутриобластных роутерах. В других областях
рекламируются как внутриобластные, так и межобластные маршруты.
·
AS
external links advertisements объявления
о внешних каналах AS. Описывают какой-либо маршрут к одному из пунктов
назначения, который является внешним для данного AS. объявления о внешних
каналах AS вырабатываются граничными роутерами AS. Этот тип объявлений является
единственным типом объявлений, которые продвигаются во всех направлениях данной
AS; все другие объявления продвигаются только в пределах конкретных областей. За полем типа заголовка пакета
OSPF идет поле длины пакета ( packet
length ). Это поле обеспечивает длину пакета
вместе с заголовком OSPF в байтах. Поле идентификатора роутера ( router ID )
идентифицирует источник пакета. Поле идентификатора области ( area ID )
идентифицирует область, к которой принадлежит данный пакет. Все пакеты OSPF
связаны с одной отдельной областью. Стандартное поле контрольной
суммы IP ( checksum )
проверяет содержимое всего пакета для выявления потенциальных повреждений,
имевших место при транзите. За полем контрольной суммы идет
поле типа удостоверения ( authentication
type ). Примером типа удостоверения является
"простой пароль". Все обмены протокола OSPF проводятся с
установлением достоверности. Тип удостоверения устанавливается по принципу
"отдельный для каждой области". За полем типа удостоверения
идет поле удостоверения ( authentication
). Это поле длиной 64 бита и содержит информацию удостоверения.
10.4
EGP
Библиографическая
справка
Протокол внешних роутеров (Exterior Gateway
Protocol-EGP) является
протоколом междоменной досягаемости, который
применяется в Internet - международной сети,
объединяющей университеты, правительственные учреждения,
научно-исследовательские организации и частные коммерческие концерны. EGP документально оформлен в Запросах для Комментария
(RFC) 904, опубликованных в апреле 1984 г. Являясь первым протоколом
внешних роутеров, который получил широкое признание в Internet,
EGP сыграл важную роль. К сожалению, недостатки EGP стали более очевидными после того, как Internet стала более крупной и совершенной сетью. Из-за
этих недостатков EGP в настоящее время не отвечает
всем требованиям Internet и заменяется другими
протоколами внешних роутеров, такими, как Протокол граничных роутеров ( Border Gateway Protocol - BGP ) и
Протокол междоменной маршрутизации ( Inter-Domain Routing Protocol - IDRP ) (смотри пункты "BGP" и
"Маршрутизация OSI").
10.5
BGP
Библиографическая
справка
Протоколы внешних роутеров
предназначены для маршрутизации между доменами маршрутизации. В терминологии Internet (международной сети, объединяющей университеты,
правительственные учреждения, научно-исследовательские организации и частные
коммерческие концерны) доменом маршрутизации называется автономная система
(AS). Первым протоколом внешних роутеров, получившим широкое признание в Internet, был протокол EGP
(Смотри пункт "ЕGP"). Хотя технология EGP
пригодна для сетей, он имеет ряд недостатков, в том числе тот факт, что это
скорее протокол досягаемости, а не маршрутизации. Протокол Граничных роутеров ( Border Gateway Protocol - BGP )
является попыткой решить самую серьезную проблему EGP.
BGP является протоколом маршрутизации между AS, созданным для применения в Internet. В отличие от EGP, BGP
предназначен для обнаружения маршрутных петель. BGP можно назвать следующим
поколением EGP. И действительно, BGP и другие
протоколы маршрутизации между AS постепенно вытесняют EGP
из Internet. Версия 3 BGP определена в Запросах для
Комментария (RFC) 1163. Основы
технологии
Хотя BGP разработан как
протокол маршрутизации между AS, он может использоваться для маршрутизации как
в пределах, так и между AS. Два соседа BGP, сообщающихся из различных AS,
должны находиться в одной и той же физической сети. Роутеры BGP, находящиеся в
пределах одной и той же AS, сообщаются друг с другом, чтобы обеспечить
согласующееся представление о данной AS и определить, какой из роутеров BGP
данной AS будет служить в качестве точки соединения при передаче сообщений в
определенные внешние AS и при их приеме. Некоторые AS являются просто
каналами для прохождения через них сетевого трафика. Другими словами, некоторые
AS переносят трафик, источник которого не находится в их пределах и который не
предназначен для них. BGP должен взаимодействовать с любыми протоколами
маршрутизации внутри AS, которые существуют в пределах этих проходных AS. Сообщения о корректировках BGP
состоят из пар "сетевой номер/тракт AS". Тракт AS содержит
последовательность из AS, через которые может быть достигнута указанная сеть.
Эти сообщения о корректировке отправляются с помощью механизма транспортировки
TCP для обеспечения надежной доставки. Обмен исходной информацией
между двумя роутерами является содержанием всей маршрутной таблицы BGP. С
изменением маршрутной таблицы отправляются инкрементные корректировки. В
отличие от некоторых других протоколов маршрутизации BGP не требует
периодического обновления всей маршрутной таблицы. Вместо этого роутеры BGP
хранят новейшую версию маршрутной таблицы каждого равноправного члена. Хотя BGP
поддерживает маршрутную таблицу всех возможных трактов к какой-нибудь
конкретной сети, в своих сообщениях о корректировке он объявляет только об
основных (оптимальных) маршрутах. Показатель BGP представляет
собой произвольное число единиц, характеризующее степень предпочтения
какого-нибудь конкретного маршрута. Эти показатели обычно устанавливаются
администратором сети с помощью конфигурационных файлов. Степень предпочтения
может базироваться на любом числе критериев, включая число AS (тракты с меньшим
числом AS как правило лучше), тип канала (стабильность, быстродействие и
надежность канала) и другие факторы. |
||