|
8.
Сетевой уровень: IP протокол |
||||||||||||
|
8.1
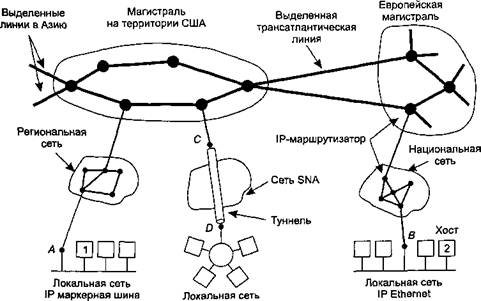
Сетевой уровень в Интернете На сетевом уровне Интернет можно
рассматривать как набор подсетей или автономных систем, соединенных друг с другом. Структуры
как таковой Интернет не имеет, но все же есть несколько магистралей. Они
собраны из высокопроизводительных линий и быстрых маршрутизаторов. К
магистралям присоединены региональные сети (сети среднего уровня), с которыми, в
свою очередь, соединяются
локальные сети многочисленных университетов, компаний и провайдеров. Схема этой квазииерархической структуры показана на рис. 5.46. Вся эта конструкция «склеивается»
благодаря протоколу сетевого уровня, IP (Internet Protocol – протокол сети Интернет). В отличие от большинства ранних
протоколов сетевого уровня, IP с самого начала разрабатывался как протокол межсетевого
обмена. Вот как можно описать данный протокол сетевого уровня: его работа
заключается в приложении максимума усилий (тем не менее, без всяких гарантий)
по транспортировке дейтаграмм от отправителя к получателю независимо от того,
находятся эти машины в одной и той же сети или нет. Соединение в сети Интернет представляет
собой следующее. Транспортный уровень берет поток данных и разбивает его на
дейтаграммы. Теоретически размер каждой дейтаграммы может достигать 64 Кбайт,
однако на практике они обычно не более 1500 байт (укладываются в один кадр Ethernet). Каждая дейтаграмма
пересылается по Интернету, возможно, разбиваясь при этом на более мелкие
фрагменты, собираемые сетевым уровнем получателя в исходную дейтаграмму. Затем
эта дейтаграмма передается транспортному уровню, вставляющему ее во входной
поток получающего процесса. На рис. 5.46 видно, что пакет, посланный хостом 1,
пересечет на своем пути шесть сетей, прежде чем доберется до хоста 2. На
практике промежуточных сетей оказывается гораздо больше.
Рис. 5.46. Интернет
представляет собой набор соединенных друг с другом сетей
8.2
Протокол
IP Начнем изучение сетевого уровня Интернета
с формата IP-дейтаграмм. IP-дейтаграмма
состоит из заголовка и текстовой части. Заголовок содержит обязательную
20-байтную часть, а также необязательную часть переменной длины. Формат
заголовка показан на рис. 5.47. Он передается слева направо, то есть старший
бит поля Версия передается первым. (В процессоре SPARC байты
располагаются слева направо, в процессоре Pentium – наоборот, справа налево.) На
машинах, у которых старший байт располагается после младшего, как, например, у
семейства процессоров корпорации Intel, требуется программное преобразование как при передаче, так
и при приеме.
Рис. 5.47. Заголовок IР-дейтаграммы IPv4 Поле Версия
содержит версию протокола, к которому принадлежит дейтаграмма. Включение
версии в каждую дейтаграмму позволяет использовать разные версии протокола на
разных машинах. Дело в том, что с годами протокол изменялся, и на одних машинах
сейчас работают новые версии, тогда как на других продолжают использоваться
старые. Сейчас происходит переход от версии IPv4 к версии IPv6. Он
длится уже много лет, и не похоже, что скоро завершится (Durand, 2001; Wiljakka, 2002; Waddington и
Chang, 2002). Некоторые
даже считают, что это не произойдет никогда (Weiser, 2001). Что касается нумерации,
то ничего странного в ней нет, просто в свое время существовал мало кому известный
экспериментальный протокол реального масштаба времени IPv5. Длина заголовка является переменной величиной,
для хранения которой выделено поле IHL (информация в нем представлена в виде 32-разрядных слов).
Минимальное значение длины (при отсутствии необязательного поля) равно 5.
Максимальное значение этого 4-битового поля равно 15, что соответствует заголовку
длиной 60 байт; таким образом, максимальный размер необязательного поля равен
40 байтам. Для некоторых приложений, например, для записи маршрута, по которому
должен быть переслан пакет, 40 байт слишком мало. В данном случае
дополнительное поле оказывается бесполезным. Поле Тип службы –
единственное поле, смысл которого с годами несколько изменился. Оно было
(впрочем, и до сих пор) предназначено для различения классов обслуживания.
Возможны разные комбинации надежности и скорости. Для оцифрованного голоса
скорость доставки важнее точности. При передаче файла, наоборот, передача без
ошибок важнее быстрой доставки. Изначально 6-разрядное поле Тип
службы состояло из трехразрядного поля Precedence и трех флагов – Д Т
и R. Поле Precedence указывало
приоритет, от 0 (нормальный) до 7 (управляющий сетевой пакет). Три флаговых бита позволяли хосту указать, что беспокоит его
сильнее всего, выбрав из набора {Delay, Throughput,
Reliability} (Задержка,
Пропускная способность, Надежность). Теоретически, эти поля позволяют
маршрутизаторам выбрать, например, между спутниковой линией с высокой
пропускной способностью и большой задержкой и выделенной линией с низкой
пропускной способностью и небольшой задержкой. На практике сегодняшние
маршрутизаторы часто вообще игнорируют поле Тип службы. Поле Полная длина
содержит длину всей дейтаграммы, включая как заголовок, так и данные.
Максимальная длина дейтаграммы 65 535 байт. В настоящий момент этот верхний
предел достаточен, однако с появлением гигабитных сетей могут понадобиться
дейтаграммы большего размера. Поле Идентификатор
позволяет хосту-получателю определить, какой дейтаграмме принадлежат полученные
им фрагменты. Все фрагменты одной дейтаграммы содержат одно и то же значение
идентификатора. Следом идет один неиспользуемый бит и два
однобитных поля. Бит DF означает Don’t Fragment (Не
фрагментировать). Это команда маршрутизатору, запрещающая ему фрагментировать
дейтаграмму, так как получатель не сможет восстановить ее из фрагментов.
Например, при загрузке компьютера его ПЗУ может запросить образ памяти в виде
единой дейтаграммы. Пометив дейтаграмму битом DF,
отправитель гарантирует, что дейтаграмма дойдет единым блоком, даже если для
ее доставки придется избегать сетей с маленьким размером пакетов. От всех машин
требуется способность принимать фрагменты размером 576 байт и менее. Бит MF означает More Fragments (Продолжение следует). Он устанавливается во всех
фрагментах, кроме последнего. По этому биту получатель узнает о прибытии
последнего фрагмента дейтаграммы. Поле Смещение фрагмента
указывает положение фрагмента в исходной дейтаграмме. Длина всех фрагментов в
байтах, кроме длины последнего фрагмента, должна быть кратна 8. Так как на это
поле выделено 13 бит, максимальное количество фрагментов в дейтаграмме равно
8192, что дает максимальную длину дейтаграммы 65 536 байт, на 1 байт больше,
чем может содержаться в поле Полная длина. Поле Время жизни
представляет собой счетчик, ограничивающий время жизни пакета. Предполагалось,
что он будет отсчитывать время в секундах, таким образом, допуская максимальное
время жизни пакета в 255 с. На каждом маршрутизаторе это значение должно было
уменьшаться как минимум на единицу плюс время стояния в очереди. Однако на
практике этот счетчик просто считает количество переходов через маршрутизаторы.
Когда значение этого поля становится равным нулю, пакет отвергается, а
отправителю отсылается пакет с предупреждением. Таким образом, удается избежать
вечного странствования пакетов, что может произойти, если таблицы
маршрутизаторов по какой-либо причине испортятся. Собрав дейтаграмму из фрагментов, сетевой
уровень должен решить, что с ней делать. Поле Протокол
сообщит ему, какому процессу транспортного уровня ее передать. Это может быть TCP, UDP или
что-нибудь еще. Нумерация процессов глобально стандартизирована по всему
Интернету. Номера протоколов вместе с некоторыми другими были сведены в RFC 1700,
однако теперь доступна интернет-версия в виде базы данных, расположенной по
адресу
www.iana.org. Поле Контрольная сумма
заголовка защищает от ошибок только заголовок. Подобная
контрольная сумма полезна для обнаружения ошибок, вызванных неисправными
микросхемами памяти маршрутизаторов. Алгоритм вычисления суммы просто
складывает все 16-разрядные полуслова в дополнительном коде, преобразуя
результат также в дополнительный код. Таким образом, проверяемая получателем
контрольная сумма заголовка (вместе с этим полем) должна быть равна нулю. Этот
алгоритм надежнее, чем обычное суммирование. Обратите внимание на то, что
значение Контрольной суммы заголовка должно подсчитываться заново
на каждом транзитном участке, так как по крайней мере одно поле постоянно
меняется (поле Время жизни). Для ускорения расчетов применяются некоторые
хитрости. Поля Адрес отправителя
и Адрес
получателя указывают номер сети и номер хоста. Интернет-адреса
будут обсуждаться в следующем разделе. Поле Необязательная часть
было создано для того, чтобы с появлением новых вариантов протокола не пришлось
вносить в заголовок поля, отсутствующие в нынешнем формате. Оно же может
служить пространством для различного рода экспериментов, испытания новых идей.
Кроме того, оно позволяет не включать в стандартный заголовок редко
используемую информацию. Размер поля Необязательная часть может
варьироваться. В начале поля всегда располагается однобайтный идентификатор.
Иногда за ним может располагаться также однобайтное поле длины, а затем один
или несколько информационных байтов. В любом случае, размер поля Необязательная
часть должен быть кратен 4 байтам. Изначально было определено
пять разновидностей этого поля, перечисленных в табл. 5.6, однако с тех пор
появилось несколько новых. Текущий полный список имеется в Интернете, его
можно найти по адресу
www.iana.org/assignments/ip-parameters. Таблица 5.6. Некоторые
типы необязательного поля IP-дейтаграммы
Параметр Безопасность
указывает уровень секретности дейтаграммы. Теоретически, военный маршрутизатор
может использовать это поле, чтобы запретить маршрутизацию дейтаграммы через
территорию определенных государств. На практике все маршрутизаторы игнорируют
этот параметр, так что его единственное практическое применение состоит в помощи
шпионам в поиске ценной информации. Параметр Строгая маршрутизация от
источника задает полный путь следования дейтаграммы от
отправителя до получателя в виде последовательности IP-адресов. Дейтаграмма обязана
следовать именно по этому маршруту. Наибольшая польза этого параметра
заключается в том, что с его помощью системный менеджер может послать
экстренные пакеты, когда таблицы маршрутизатора повреждены, или замерить
временные параметры сети. Параметр Свободная маршрутизация
от источника требует, чтобы пакет прошел через указанный список
маршрутизаторов в указанном порядке, но при этом по пути он может проходить
через любые другие маршрутизаторы. Обычно этот параметр указывает лишь
небольшое количество маршрутизаторов. Например, чтобы заставить пакет,
посылаемый из Лондона в Сидней, двигаться не на восток, а на запад, можно
указать в этом параметре IP-адреса
маршрутизаторов в Нью-Йорке, Лос-Анджелесе и Гонолулу. Этот параметр наиболее
полезен, когда по политическим или экономическим соображениям следует избегать
прохождения пакетов через определенные государства. Параметр Запомнить маршрут
требует от всех маршрутизаторов, встречающихся по пути следования пакета,
добавлять свой IP-адрес
к полю Необязательная часть. Этот параметр позволяет системным
администраторам вылавливать ошибки в алгоритмах маршрутизации («Ну почему все
пакеты, посылаемые из Хьюстона в Даллас, сначала попадают в Токио?»). Когда
была создана сеть ARPANET,
ни один пакет не проходил больше чем через девять маршрутизаторов, поэтому 40
байт для этого параметра было как раз достаточно. Как уже говорилось, сегодня
размер поля Необязательная часть оказывается слишком мал. Наконец, параметр Временной штамп
действует полностью аналогично параметру Запомнить маршрут, но кроме
32-разрядного IP-адреса,
каждый маршрутизатор записывает также 32-разрядную запись о текущем времени.
Этот параметр также применяется в основном для отладки алгоритмов
маршрутизации. У каждого хоста и маршрутизатора в
Интернете есть IP-адрес,
состоящий из номера сети и номера хоста. Эта комбинация уникальна: нет двух
машин с одинаковыми IP-адресами.
Все IP-адреса имеют
длину 32 бита и используются в полях Адрес отправителя и Адрес получателя
IP-пакетов. Важно отметить, что IP-адрес, на самом деле, не имеет отношения к
хосту. Он имеет отношение к сетевому интерфейсу, поэтому хост, соединенный с
двумя сетями, должен иметь два IP-адреса. Однако на практике большинство хостов
подключены к одной сети, следовательно, имеют один адрес. В течение вот уже нескольких десятилетий
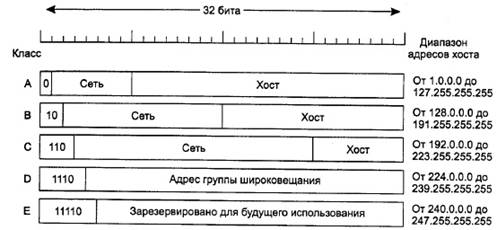
IP-адреса делятся на пять классов, показанных на рис. 5.48. Такое распределение
обычно называется полноклассовой адресацией. Сейчас
такая адресация уже не используется, но ссылки на нее в литературе встречаются
все еще довольно часто. Чуть позже мы обсудим то, что пришло ей на смену. Форматы классов А, В, С и D позволяют
задавать адреса до 128 сетей с 16 млн хостов в каждой, 16 384 сетей с 64
тысячами хостов или 2 миллионов сетей (например, ЛВС) с 256 хостами (хотя
некоторые из них могут быть специализированными). Предусмотрен класс для
многоадресной рассылки, при которой дейтаграммы рассылаются одновременно на
несколько хостов. Адреса, начинающиеся с 1111, зарезервированы для будущего
применения. В настоящее время к Интернету подсоединено более 500 ООО сетей, и
это число растет с каждым годом. Во избежание конфликтов, номера сетям
назначаются некоммерческой корпорацией по присвоению имен и номеров, ICANN (Internet Corporation for Assigned Names
and Numbers). В свою
очередь, ICANN передала полномочия по присвоению некоторых частей адресного
пространства региональным органам, занимающимся выделением IP-адресов
провайдерам и другим компаниям. Сетевые адреса, являющиеся 32-разрядными
числами, обычно записываются в виде четырех десятичных чисел, которые
соответствуют отдельным байтам, разделенных точками. Например,
шестнадцатеричный адрес С0290614 записывается как 192.41.6.20. Наименьший
IP-адрес равен 0.0.0.0, а наибольший – 255.255.255.255.
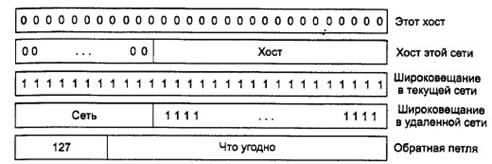
Как видно из рис. 5.49, числа 0 и -1
(единицы во всех разрядах) имеют особое назначение. Число 0 означает эту сеть
или этот хост. Значение -1 используется для широковещания и означает все хосты
указанной сети.
Рис. 5.49.
Специальные IP-адреса IP-адрес 0.0.0.0 используется хостом
только при загрузке. IP-адреса с нулевым номером сети обозначают текущую сеть.
Эти адреса позволяют машинам обращаться к хостам собственной сети, не зная ее
номера (но они должны знать ее класс и количество используемых нулей). Адрес,
состоящий только из единиц, обеспечивает широковещание в пределах текущей
(обычно локальной) сети. Адреса, в которых указана сеть, но в поле номера хоста
одни единицы, обеспечивают широковещание в пределах любой удаленной локальной
сети, соединенной с Интернетом. Наконец, все адреса вида 127.xx.yy.zz зарезервированы
для тестирования сетевого программного обеспечения методом обратной передачи.
Отправляемые по этому адресу пакеты не попадают на линию, а обрабатываются
локально как входные пакеты. Это позволяет пакетам перемещаться по локальной
сети, когда отправитель не знает номера. Как было показано ранее, у всех хостов
сети должен быть один и тот же номер сети. Это свойство IP-адресации может вызвать проблемы при
росте сети. Например, представьте, что университет создал сеть класса В, используемую
факультетом информатики в качестве Ethernet. Год спустя факультету электротехники понадобилось
подключиться к Интернету, для чего был куплен повторитель для расширения сети
факультета информатики и проложен кабель из его здания. Однако время шло, число
компьютеров в сети росло, и четырех повторителей (максимальный предел для сети Ethernet) стало не хватать.
Понадобилось создание новой архитектуры. Получить второй сетевой адрес
университету довольно сложно, потому что сетевые адреса – ресурс дефицитный, к
тому же в одном сетевом адресе адресного пространства достаточно для
подключения более 60 000 хостов. Проблема заключается в следующем: правилом
установлено, что адрес одного класса (А, В или С) относится только к одной
сети, а не к набору ЛВС. С этим столкнулось множество организаций, в результате
чего были произведены небольшие изменения в системе адресации. Проблема решилась предоставлением сети
возможности разделения на несколько частей с точки зрения внутренней
организации. При этом с точки зрения внешнего представления сеть могла
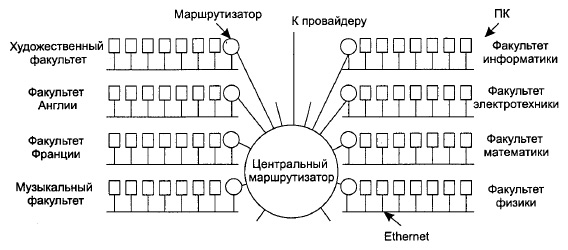
оставаться единой сущностью. Типичная сеть университетского городка в наши дни
выглядит так, как показано на рис. 5.50. Здесь главный маршрутизатор соединен с
провайдером или региональной сетью, а на каждом факультете может быть
установлена своя локальная сеть Ethernet.
Все сети Ethernet с помощью своих маршрутизаторов соединяются с главным
маршрутизатором университетской сети (возможно, с помощью магистральной ЛВС,
однако здесь важен сам принцип межмаршрутизаторной
связи).
Рис. 5.50. Университетская
сеть, состоящая из ЛВС разных факультетов В литературе, посвященной
интернет-технологиям, части сети называются подсетями. Как уже упоминалось в главе 1, подобное использование
этого термина конфликтует со старым понятием «подсети», обозначающим множество
всех маршрутизаторов и линий связи в сети. К счастью, по контексту обычно бывает
ясно, какой смысл вкладывается в это слово. По крайней мере, в данном разделе
«подсеть» будет употребляться только в новом значении. Как центральный маршрутизатор узнает, в
какую из подсетей (Ethernet)
направить пришедший пакет? Одним из способов является поддержание маршрутизатором
таблицы из 65 536 записей, говорящих о том, какой из маршрутизаторов
использовать для доступа к каждому из хостов. Эта идея будет работать, но
потребуется очень большая таблица и много операций по ее обслуживанию, выполняемых
вручную, при добавлении, перемещении и удалении хостов. Была изобретена альтернативная схема работы.
Вместо одного адреса класса В с 14 битами для номера сети и 16 битами для
номера хоста было предложено использовать несколько другой формат –
формировать адрес подсети из нескольких битов. Например, если в университете
существует 35 подразделений, то 6-бигным номером можно кодировать подсети, а
10-битным – номера хостов. С помощью такой адресации можно организовать до 64
сетей Ethernet по 1022 хоста в каждой (адреса 0 и -1 не используются, как
уже говорилось, поэтому не 1024 (210), а именно 1022 хоста). Такое
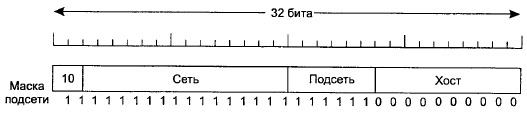
разбиение может быть изменено, если окажется, что оно не очень подходит. Все, что нужно маршрутизатору для
реализации подсети, это наложить маску подсети, показывающую разбиение адреса
на номер сети, подсети и хоста (рис. 5.51). Маски подсетей также записываются в
виде десятичных чисел, разделенных точками, с добавлением косой черты, за
которой следует число битов номера сети и подсети. Например, на рис. 5.51 маску
подсети можно записать в виде 255.255.252.0. Альтернативная запись будет
включать /22, показывая, что маска подсети занимает 22 бита.
Рис. 5.51. Сеть класса В, разделенная на 64 подсети За пределами сети разделение на подсети
незаметно, поэтому нет нужды с появлением каждой подсети обращаться в ICANN или
изменять какие-либо внешние базы данных. В данном примере первая подсеть может
использовать IP-адреса,
начиная с 130.50.4.1; вторая – начиная с 130.50.8.1; третья – 130.50.12.1, и т.
д. Чтобы понять, почему на каждую подсеть уходит именно четыре единицы в
адресе, вспомните двоичную запись этих адресов: Подсеть 1: 10000010 00110010 000001|00 00000001 Подсеть 2: 10000010 00110010 000010|00 00000001 Подсеть 3: 10000010 00110010 000011|00 00000001 Здесь вертикальная черта (|) показывает границу
номера подсети и хоста. Слева расположен 6-битный номер подсети,
справа – 10-битный номер хоста. Чтобы понять, как функционируют подсети,
следует рассмотреть процесс обработки IP-пакетов маршрутизатором. У каждого маршрутизатора есть
таблица, содержащая IP-адреса
сетей (вида <сетъ, 0>) и IP-адреса хостов (вида <эта_
сеть, хост>). Адреса сетей позволяют получать доступ к
удаленным сетям, а адреса хостов – обращаться к локальным хостам. С каждой
таблицей связан сетевой интерфейс, применяющийся для получения доступа к
пункту назначения, а также другая информация. Когда IP-пакет прибывает на маршрутизатор, адрес получателя, указанный
в пакете, ищется в таблице маршрутизации. Если пакет направляется в удаленную
сеть, он пересылается следующему маршрутизатору по интерфейсу, указанному в
таблице. Если пакет предназначен локальному хосту (например, в локальной сети
маршрутизатора), он посылается напрямую адресату. Если номера сети, в которую
посылается пакет, в таблице маршрутизатора нет, пакет пересылается
маршрутизатору по умолчанию, с более подробными таблицами. Такой алгоритм означает,
что каждый маршрутизатор должен учитывать только другие сети и локальные хосты,
а не пары <сеть, хост>, что значительно уменьшает размер
таблиц маршрутизатора. При разбиении сети на подсети таблицы
маршрутизации меняются – добавляются записи вида <эта_сетъ,
подсеть, 0> и <эта_сеть, эта_подсеть, хост>. Таким образом,
маршрутизатор подсети k знает, как получить доступ ко всем другим подсетям и как
добраться до всех хостов своей подсети. Ему нет нужды знать детали адресации
хостов в других подсетях. На самом деле, все, что для этого требуется от
маршрутизатора, это выполнить двоичную операцию И над маской подсети, чтобы
избавиться от номера хоста, а затем найти получившийся адрес в таблицах (после
определения класса сети). Например, пакет, адресованный хосту с IP-адресом 130.50.15.6 и
прибывающий на центральный маршрутизатор, после выполнения операции И с маской
255.255.252.0/22 получает адрес Это значение ищется в таблицах
маршрутизации, и с его помощью определяется выходная линия маршрутизатора к подсети
3. Итак, разбиение на подсети уменьшает объем таблиц маршрутизаторов путем
создания трехуровневой иерархии, состоящей из сети, подсети и хоста.
8.5
CIDR – бесклассовая междоменная
маршрутизация В течение многих лет IP оставался
чрезвычайно популярным протоколом. Он работал просто прекрасно, и основное
подтверждение тому - экспоненциальный рост сети Интернет. К сожалению, протокол
IP скоро
стал жертвой собственной популярности: стало подходить к концу адресное
пространство. Эта угроза вызвала бурю дискуссий и обсуждений в
Интернет-сообществе. В этом разделе мы опишем как саму проблему, так и
некоторые предложенные способы ее решения. В теперь уже далеком 1987 году некоторые
дальновидные люди предсказывали, что настанет день, когда в Интернете будет
100 000 сетей. Большинство экспертов посмеивались над этим и говорили, что
если такое когда-нибудь и произойдет, то не раньше, чем через много десятков
лет. Стотысячная сеть была подключена к Интернету в 1996 году. И, как уже было
сказано, нависла угроза выхода за пределы пространства IP-адресов. В принципе, существует 2
миллиарда адресов, но на практике благодаря иерархической организации адресного
пространства (см. рис. 5.48) это число сократилось на миллионы. В частности, одним
из виновников этого является класс сетей В. Для большинства организаций класс А
с 16 миллионами адресов – это слишком много, а класс С с
256 адресами – слишком мало. Класс В с 65 536 адресами – это то, что нужно. В
интернет- фольклоре такая дилемма известна под названием проблемы трех медведей
(вспомним Машу и трех медведей). На самом деле и класс В слишком велик для
большинства контор, которые устанавливают у себя сети. Исследования показали,
что более чем в половине случаев сети класса В включают в себя менее 50 хостов.
Безо всяких сомнений, всем этим организациям хватило бы и сетей класса С,
однако почему-то все уверены, что в один прекрасный день маленькое предприятие
вдруг разрастется настолько, что сеть выйдет за пределы 8-битного адресного
пространства хостов. Сейчас, оглядываясь назад, кажется, что лучше было бы
использовать в классе С 10-битную адресацию (до 1022 хостов в сети). Если бы
это было так, то, возможно, большинство организаций приняло бы разумное решение
устанавливать у себя сети класса С, а не В. Таких сетей могло бы быть
полмиллиона, а не 16 384, как в случае сетей класса В. Нельзя обвинять в создавшейся ситуации
проектировщиков Интернета за то, что они не увеличили (или не уменьшили) адресное
пространство сетей класса В. В то время, когда принималось решение о создании
трех классов сетей, Интернет был инструментом научно-исследовательских
организаций США (плюс несколько компаний и военных организаций, занимавшихся
исследованиями с помощью сети). Никто тогда не предполагал, что Интернет станет
коммерческой системой коммуникации общего пользования, соперничающей с
телефонной сетью. Тогда кое-кто сказал, ничуть не сомневаясь в своей правоте:
«В США около 2000 колледжей и университетов. Даже если все они подключатся к
Интернету и к ним присоединятся университеты из других стран, мы никогда не
превысим число 16 000, потому что высших учебных заведений по всему миру не так
уж много. Зато мы будем кодировать номер хоста целым числом байт, что ускорит
процесс обработки пакетов». Даже если выделить 20 бит под адрес сети
класса В, возникнет другая проблема: разрастание таблиц маршрутизации. С точки
зрения маршрутизаторов, адресное пространство IP представляет
собой двухуровневую иерархию, состоящую из номеров сетей и номеров хостов.
Маршрутизаторы не обязаны знать номера вообще всех хостов, но им необходимо
знать номера всех сетей. Если бы использовалось полмиллиона сетей класса С,
каждому маршрутизатору пришлось бы хранить в таблице полмиллиона записей, по
одной для каждой сети, в которых сообщалось бы о том, какую выходную линию
использовать, чтобы добраться до той или иной сети, а также о чем-нибудь еще. Физическое хранение полумиллиона строк
таблицы, вероятно, выполнимо, хотя и дорого для маршрутизаторов, хранящих
таблицы в статической памяти плат ввода-вывода. Более серьезная проблема
состоит в том, что сложность обработки этих таблиц растет быстрее, чем сами
таблицы, то есть зависимость между ними не линейная. Кроме того, большая часть
имеющихся программных и программно-аппаратных средств маршрутизаторов
разрабатывалась в те времена, когда Интернет объединял 1000 сетей, а 10 000
сетей казались отдаленным будущим. Методы реализации тех лет в настоящее время
далеки от оптимальных. Различные алгоритмы маршрутизации требуют
от каждого маршрутизатора периодической рассылки своих таблиц (например,
протоколов векторов расстояний). Чем больше будет размер этих таблиц, тем выше
вероятность потери части информации по дороге, что будет приводить к неполноте
данных и возможной нестабильности работы алгоритмов выбора маршрутов. Проблема таблиц маршрутизаторов может
быть решена при помощи увеличения числа уровней иерархии. Например, если бы
каждый IP-адрес
содержал поля страны, штата, города, сети и номера хоста. В таком случае
каждому маршрутизатору нужно будет знать, как добраться до каждой страны, до
каждого штата или провинции своей страны, каждого города своей провинции или
штата и до каждой сети своего города. К сожалению, такой подход потребует
существенно более 32 бит для адреса, а адресное поле будет использоваться
неэффективно (для княжества Лихтенштейн будет выделено столько же разрядов,
сколько для Соединенных Штатов). Таким образом, большая часть решений
разрешает одну проблему, но взамен создает новую. Одним из решений, реализуемым
в настоящий момент, является алгоритм маршрутизации CIDR (Classless InterDomain Routing – бесклассовая меж- доменная маршрутизация). Идея
маршрутизации CIDR, описанной
в RFC 1519,
состоит в объединении оставшихся адресов в блоки переменного размера,
независимо от класса. Если кому-нибудь требуется, скажем, 2000 адресов, ему
выделяется блок из 2048 адресов на границе, кратной 2048 байтам. Отказ от классов усложнил процесс
маршрутизации. В старой системе, построенной на классах, маршрутизация
происходила следующим образом. По прибытии пакета на маршрутизатор копия IP-адреса, извлеченного из
пакета и сдвинутого вправо на 28 бит, давала 4-битный номер класса. С помощью
16-аль- тернативного
ветвления пакеты рассортировывались на А, В, С и D (если этот
класс поддерживался): восемь случаев было зарезервировано для А, четыре для В,
два для С и по одному для D и Е. Затем при помощи маскировки по коду каждого класса
определялся 8-, 16- или 32-битный сетевой номер, который и записывался с
выравниванием по правым разрядам в 32-битное слово. Сетевой номер отыскивался в
таблице А, В или С, причем для А и В применялась индексация, а для С –
хэш-функция. По найденной записи определялась выходная линия, по которой пакет
и отправлялся в дальнейшее путешествие. В CIDR этот простой алгоритм применить не
удается. Вместо этого применяется расширение всех записей таблицы маршрутизации
за счет добавления 32-битной маски. Таким образом, образуется единая таблица
для всех сетей, состоящая из набора троек (IP-адрес, маска подсети, исходящая линия). Что происходит с
приходящим пакетом при применении метода CIDR? Во-первых, извлекается IP-адрес назначения. Затем (концептуально) таблица маршрутизации
сканируется запись за записью, адрес назначения маскируется и сравнивается со
значениями записей. Может оказаться, что по значению подойдет несколько записей
(с разными длинами масок подсети). В этом случае используется самая длинная
маска. То есть если найдено совпадение для маски /20 и /24, то будет выбрана
запись, соответствующая /24. Был разработан сложный алгоритм для
ускорения процесса поиска адреса в таблице (Ruiz-Sanchez и др., 2001). В маршрутизаторах, предполагающих коммерческое
использование, применяются специальные чипы VLSI, в которые данные алгоритмы встроены аппаратно. Чтобы лучше понять алгоритм
маршрутизации, рассмотрим пример. Допусим, имеется
набор из миллионов адресов, начиная с 194.24.0.0. Допустим также, что
Кембриджскому университету требуется 2048 адресов, и ему выделяются адреса от
194.24.0.0 до 194.24.7.255, а также маска 255.255.248.0. Затем Оксфордский
университет запрашивает 4096 адресов. Так как блок из 4096 адресов должен
располагаться на границе, кратной 4096, то ему не могут быть выделены адреса
начиная с 194.24.8.0. Вместо этого он получает адреса от 194.24.16.0 до
194.24.31.255 вместе с маской 255.255.240.0. Затем Эдинбургский
университет просит выделить ему 1024 адреса и получает адреса от 194.24.8.0 до
194.24.11.255 и маску 255.255.252.0. Все эти присвоенные адреса и маски сведены
в табл. 5.7. Таблица 5.7. Набор
присвоенных IP-адресов
После этого таблицы маршрутизаторов по
всему миру получают три новые строки, содержащие базовый адрес и маску. В
двоичном виде эти записи выглядят так: Адрес Маска К: 11000010 00011000 00000000 00000000 11111111 11111111 11111000 00000000 Э: 11000010 00011000 00001000 00000000 11111111 11111111 11111100 00000000 0:11000010 00011000
00010000 00000000 11111111 11111111 11110000 00000000 Теперь посмотрим, что произойдет, когда
пакет придет по адресу 194.24.17.4. В двоичном виде этот адрес представляет
собой следующую 32-битную строку: 11000010 00011000
00010001
00000100 Сначала на него накладывается
(выполняется логическое И) маска Кембриджа, в результате чего получается 11000010 00011000 00010000 00000000 Это значение не совпадает с базовым
адресом Кембриджа, поэтому на оригинальный адрес накладывается маска Оксфорда,
что дает в результате; 11000010 00011000 00010000 00000000 Это значение совпадает с базовым адресом
Оксфорда. Если далее по таблице совпадений нет, то пакет пересылается
Оксфордскому маршрутизатору. Теперь посмотрим на эту троицу университетов с
точки зрения маршрутизатора в Омахе, штат Небраска, у которого есть всего
четыре выходных линии: на Миннеаполис, Нью-Йорк, Даллас и Денвер. Получив три
новых записи, маршрутизатор понимает, что он может скомпоновать их вместе и
получить одну агрегированную запись, состоящую из адреса 194.24.0.0/19 и подмаски: 11000010 00000000 00000000
00000000
11111111
11111111
11100000
00000000 В соответствии с этой записью пакеты,
предназначенные для любого из трех университетов, отправляются в Нью-Йорк.
Объединив три записи, маршрутизатор в Омахе уменьшил размер своей таблицы на
две строки. В Нью-Йорке весь трафик Великобритании
направляется по лондонской линии, поэтому там также используется агрегированная
запись. Однако если имеются отдельные линии в Лондон и Эдинбург, тогда
необходимы три отдельные записи. Агрегация часто используется в Интернете для
уменьшения размеров таблиц маршрутизации. И последнее замечание по данному примеру.
Та же самая агрегированная запись маршрутизатора в Омахе используется для
отправки пакетов по не присвоенным адресам в Нью-Йорк. До тех пор, пока адреса
остаются не присвоенными, это не имеет значения, поскольку предполагается, что
они вообще не встретятся. Однако если в какой-то момент этот диапазон адресов
будет присвоен какой-нибудь калифорнийской компании, для его обработки
понадобится новая запись: 194.24.12.0/22.
8.6
NAT
– трансляция сетевого адреса IP-адреса являются дефицитным ресурсом. У провайдера может быть
/16-адрес (бывший класс В), дающий возможность подключить 65 534 хоста. Если
клиентов становится больше, начинают возникать проблемы. Хостам, подключающимся
к Интернету время от времени по обычной телефонной линии, можно выделять IP-адреса динамически, только
на время соединения. Тогда один /16-адрес будет обслуживать до 65 534 активных
пользователей, и этого, возможно, будет достаточно для провайдера, у которого
несколько сотен тысяч клиентов. Когда сессия связи завершается, IP-адрес присваивается новому
соединению. Такая стратегия может решить проблемы провайдеров, имеющих не очень
большое количество частных клиентов, соединяющихся по телефонной линии, однако
не поможет провайдерам, большую часть клиентуры которых составляют организации. Дело в том, что корпоративные клиенты
предпочитают иметь постоянное соединение с Интернетом, по крайней мере в
течение рабочего дня. И в маленьких конторах, например туристических агенствах, состоящих из трех сотрудников, и в больших
корпорациях имеются локальные сети, состоящие из некоторого числа компьютеров.
Некоторые компьютеры являются рабочими станциями сотрудников, некоторые служат
веб-серверами. В общем случае имеется маршрутизатор ЛВС, соединенный с
провайдером по выделенной линии для обеспечения постоянного подключения. Такое
решение означает, что с каждым компьютером целый день связан один IP-адрес. Вообще-то даже все
вместе взятые компьютеры, имеющиеся у корпоративных клиентов, не могут
перекрыть имеющиеся у провайдера IP-адреса. Для адреса длины /16 этот предел равен, как мы уже отмечали,
65 534. Однако если у поставщика услуг Интернета число корпоративных клиентов
исчисляется десятками тысяч, то этот предел будет достигнут очень быстро. Проблема усугубляется еще и тем, что все
большее число частных пользователей желают иметь ADSL или
кабельное соединение с Интернетом. Особенности этих способов заключаются в
следующем: а) пользователи получают постоянный IP-адрес; б) отсутствует повременная
оплата (взимается только ежемесячная абонентская плата). Пользователи такого
рода услуг имеют постоянное подключение к Интернету. Развитие в данном
направлении приводит к возрастанию дефицита IP-адресов. Присваивать IP-адреса «на лету», как это делается при телефонном подключении,
бесполезно, потому что число активных адресов в каждый момент времени может
быть во много раз больше, чем имеется у провайдера. Часто ситуация еще больше усложняется за
счет того, что многие пользователи ADSL и кабельного Интернета имеют дома
два и более компьютера (например, по одному на каждого члена семьи) и хотят,
чтобы все машины имели выход в Интернет. Что же делать – ведь есть только один IP-адрес, выданный
провайдером! Решение таково: необходимо установить маршрутизатор и объединить
все компьютеры в локальную сеть. С точки зрения провайдера, в этом случае семья
будет выступать в качестве аналога маленькой фирмы с несколькими компьютерами.
Добро пожаловать в корпорацию Васильевых! Проблема дефицита IP-адресов отнюдь не теоретическая и
отнюдь не относится к отдаленному будущему. Она уже актуальна, и бороться с ней
приходится здесь и сейчас. Долговременный проект предполагает тотальный перевод
всего Интернета на протокол IPv6 со 128-битной адресацией. Этот переход действительно
постепенно происходит, но процесс идет настолько медленно, что затягивается на
годы. Видя это, многие поняли, что нужно срочно найти какое-нибудь решение хотя
бы на ближайшее время. Такое решение было найдено в виде метода трансляции
сетевого адреса, NAT (Network Address Translation), описанного в RFC 3022.
Суть его мы рассмотрим позже, а более подробную информацию можно найти в (Dutcher,
2001). Основная идея трансляции сетевого адреса
состоит в присвоении каждой фирме одного IP-адреса (или, по крайней мере, небольшого числа адресов) для
интернет-трафика. Внутри фирмы каждый компьютер получает уникальный IP- адрес, используемый для
маршрутизации внутреннего трафика. Однако как только
пакет покидает пределы здания фирмы и направляется к провайдеру, выполняется
трансляция адреса. Для реализации этой схемы было создано три диапазона так
называемых частных IP-адресов.
Они могут использоваться внутри компании по ее усмотрению. Единственное
ограничение заключается в том, что пакеты с такими адресами ни в коем случае не
должны появляться в самом Интернете. Вот эти три зарезервированных диапазона: 10.0.0.0 - 10.255.255.255/8 (16 777 216 хостов) 172.16.0.0 - 172.31.255.255/12 (1 048 576 хостов) 192.168.0.0 - 192.168.255.255/16 (65 536 хостов) Итак, первый диапазон может обеспечить
адресами 16 777 216 хостов (кроме 0 и -1, как обычно), и именно его обычно
предпочитают компании, даже если им на самом деле столько внутренних адресов и
не требуется. Работа метода трансляции сетевых адресов
показана на рис. 5.52. В пределах территории компании у каждой машины имеется
собственный уникальный адрес вида 10.x.y.z.. Тем не менее, когда пакет выходит за пределы владений
компании, он проходит через NAT-блок,
транслирующий внутренний IP-адрес
источника (10.0.0.1 на рисунке) в реальный IP-адрес, полученный компанией от провайдера (198.60.42.12 для
нашего примера). NAT-блок
обычно представляет собой единое устройство с брандмауэром, обеспечивающим
безопасность путем строго отслеживания входящего и исходящего графика компании.
Брандмауэры мы будем изучать отдельно в главе 8. NAT-блок может быть интегрирован и с
маршрутизатором компании.
Рис. 5.52.
Расположение и работа NAT-блока Мы до сих пор обходили одну маленькую
деталь: когда приходит ответ на запрос (например, от веб-сервера), он ведь
адресуется 198.60.42.12. Как же NAT-
блок узнает, каким внутренним адресом заменить общий адрес компании? Вот в этом
и состоит главная проблема использования трансляции сетевых адресов. Если бы в
заголовке IP-пакета
было свободное поле, его можно было бы использовать для запоминания адреса
того, кто посылал запрос. Но в заголовке остается неиспользованным всего один
бит. В принципе, можно было бы создать такое поле для истинного адреса
источника, но это потребовало бы изменения IP-кода на всех машинах по всему
Интернету. Это не лучший выход, особенно если мы хотим найти быстрое решение
проблемы нехватки IP-адресов. На самом деле произошло вот что.
Разработчики NAT подметили, что большая часть полезной нагрузки IP-пакетов – это либо TCP, либо UDP. Когда мы будем в главе 6 рассматривать
TCP и
UDP, мы увидим, что оба
формата имеют заголовки, содержащие номера портов источника и приемника. Далее
мы обсудим, что значит порт TCP,
но надо иметь в виду, что с портами UDP связана точно такая же история.
Номера портов представляют собой 16-разрядные целые числа, показывающие, где
начинается и где заканчивается TCP-соединение.
Место хранения номеров портов используется в качестве поля, необходимого для
работы NAT. Когда процесс желает установить TCP-соединение с удаленным
процессом, он связывается со свободным TCP-портом на собственном компьютере. Этот порт становится портом источника, который
сообщает TCP-коду
информацию о том, куда направлять пакеты данного соединения. Процесс также определяет
порт назначения. Посредством
порта назначения сообщается, кому отдать пакет на удаленной стороне. Порты с 0
по 1023 зарезервированы для хорошо известных сервисов. Например, 80-й порт
используется веб-серверами, соответственно, на них могут ориентироваться
удаленные клиенты. Каждое исходящее сообщение TCP содержит информацию о порте источника
и порте назначения. Вместе они служат для идентификации процессов на обоих
концах, использующих соединение. Проведем аналогию, которая несколько прояснит
принцип использования портов. Допустим, у компании есть один общий телефонный
номер. Когда люди набирают его, они слышат голос оператора, который спрашивает,
с кем именно они хотели бы соединиться, и подключают их к соответствующему
добавочному телефонному номеру. Основной телефонный номер является аналогией IP-адреса
компании, а добавочные на обоих концах аналогичны портам. Для адресации портов
используется 16-битное поле, которое идентифицирует процесс, получающий
входящий пакет. С помощью поля Порт источника
мы можем решить проблему отображения адресов. Когда исходящий пакет приходит в NAT-блок, адрес источника
вида 10.c.y.z заменяется настоящим IP-адресом. Кроме того, поле Порт
источника TCP заменяется индексом таблицы перевода NAT-блока, содержащей 65 536 записей. Каждая
запись содержит исходный IP-адрес
и номер исходного порта. Наконец, пересчитываются и вставляются в пакет
контрольные суммы заголовков TCP и IP.
Необходимо заменять поле Порт источника, потому что машины
с местными адресами 10.0.0.1 и 10.0.0.2 могут случайно пожелать воспользоваться
одним и тем же портом (5000-м, например). Так что для однозначной идентификации
процесса отправителя одного поля Порт источника оказывается
недостаточно. Когда пакет прибывает на NAT-блок со стороны провайдера,
извлекается значение поля Порт источника заголовка TCP. Оно используется в
качестве индекса таблицы отображения NAT-блока. По найденной в этой таблице записи определяются
внутренний IP-адрес и
настоящий Порт источника TCP. Эти два значения вставляются в пакет. Затем заново подсчитываются
контрольные суммы TCP и IP.
Пакет передается на главный маршрутизатор компании для нормальной доставки с
адресом вида 10.x.y.z. В случае применения ADSL или
кабельного Интернета трансляция сетевых адресов может применяться для
облегчения борьбы с нехваткой адресов. Присваиваемые пользователям адреса имеют
вид 10.x.y.z. Как только пакет покидает пределы владений провайдера и
уходит в Интернет, он попадает в NAT-блок, который преобразует внутренний адрес в реальный IP-адрес провайдера. На обратном
пути выполняется обратная операция. В этом смысле для всего остального
Интернета провайдер со своими клиентами, использующими ADSL и кабельное
соединение, представляется в виде одной большой компании. Хотя описанная выше схема частично решает
проблему нехватки IP-адресов, многие приверженцы IP рассматривают
NAT как
некую заразу, распространяющуюся по Земле. И их можно понять. Во-первых, сам принцип трансляции сетевых
адресов никак не вписывается в архитектуру
IP, которая подразумевает,
что каждый IP-адрес
уникальным образом идентифицирует только одну машину в мире. Вся программная
структура Интернета построена на использовании этого факта. При трансляции
сетевых адресов получается, что тысячи машин могут (и так происходит в действительности)
иметь адрес 10.0.0.1. Во-вторых, NAT превращает
Интернет из сети без установления соединения в нечто подобное сети,
ориентированной на соединение. Проблема в том, что NAT- блок должен поддерживать таблицу
отображения для всех соединений, проходящих через него. Запоминать состояние
соединения – дело сетей, ориентированных на соединение, но никак не сетей без
установления соединений. Если NAT-
блок ломается и теряются его таблицы отображения, то про все ТСР-соединения,
проходящие через него, можно забыть. При отсутствии трансляции сетевых адресов
выход из строя маршрутизатора не оказывает никакого эффекта на деятельность TCP. Отправляющий процесс
просто выжидает несколько секунд и посылает заново все неподтвержденные пакеты.
При использовании NAT Интернет становится таким же восприимчивым к сбоям, как сеть
с коммутацией каналов. В-третьих, NAT нарушает
одно из фундаментальных правил построения многоуровневых протоколов: уровень k не должен
строить никаких предположений относительно того, что именно уровень k + 1 поместил в
поле полезной нагрузки. Этот принцип определяет независимость уровней друг от
друга. Если когда-нибудь на смену TCP придет ТСР-2, у которого будет другой
формат заголовка (например, 32-битная адресация портов), то трансляция сетевых
адресов потерпит фиаско. Вся идея многоуровневых протоколов состоит в том,
чтобы изменения в одном из уровней никак не могли повлиять на остальные уровни.
NAT разрушает
эту независимость. В-четвертых, процессы в Интернете вовсе
не обязаны использовать только TCP или UDP.
Если пользователь машины А решит придумать новый протокол
транспортного уровня для общения с пользователем машины В (это
может быть сделано, например, для какого-нибудь мультимедийного приложения), то
ему придется как-то бороться с тем, что NAT-блок не сможет корректно обработать поле Порт источника
TCP. В-пятых, некоторые приложения вставляют IP-адреса в текст сообщений.
Получатель извлекает их оттуда и затем обрабатывает. Так как NAT не знает
ничего про такой способ адресации, он не сможет корректно обработать пакеты, и
любые попытки использования этих адресов удаленной стороной приведут к неудаче.
Протокол передачи файлов, FTP (File Transfer Protocol), использует именно
такой метод и может отказаться работать при трансляции сетевых адресов, если
только не будут приняты специальные меры. Эти и другие проблемы, связанные с
трансляцией сетевых адресов, обсуждаются в RFC 2993. Обычно противники использования
NAT говорят,
что решение проблемы нехватки IP-адресов
путем создания временной уродливой заплатки только мешает процессу настоящей
эволюции, заключающемуся в переходе на IPv6. Поэтому NAT – это не
добро, а зло для Интернета. |
||||||||||||