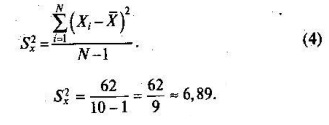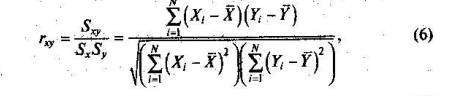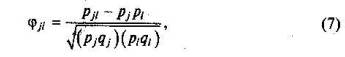|
Лекция 12. Классическая теория и методики конструирования тестов.
1. Основные этапы конструирования теста. 2. Традиционная теория тестов. 3. Математико-статистический анализ тестов и тестовых заданий. 4. Показатели связи между заданиями теста. 5. Оценка характеристик заданий теста.
1. Основные этапы конструирования теста Перечень этапов и их очередность. Процесс создания теста, его научного обоснования, переработки и улучшения можно разбить на ряд этапов, представленных ниже. 1. Определение цели тестирования, выбор вида теста и подхода к его созданию. 2. Концептуальный выбор конструкта (переменной измерения). 3. Анализ содержания учебной дисциплины и планирование содержания теста, априорный выбор длины теста и времени его выполнения, разработка спецификации теста. 4. Определение структуры теста, форм заданий и стратегии их расположения в тесте. 5. Создание предтестовых заданий. 6. Отбор заданий в тест и их ранжирование согласно выбранной стратегии предъявления на основании априорных авторских оценок трудности заданий. 7. Экспертиза формы предтестовых заданий и содержания-теста. 8. Коррекция заданий и теста по результатам экспертизы. 9. Разработка методики апробационного тестирования, инструкций для учеников и преподавателей, проводящих апробацию теста. 10. Формирование репрезентативной выборки апробации. 11. Проведение апробационного тестирования. 12. Проверка результатов выполнения теста (автоматизированная или ручная), подготовка эмпирических данных тестирования к виду, удобному для обработки и проведения анализа. 13. Статистическая обработка результатов выполнения теста (автоматизированная с помощью специального программного обеспечения). 14. Анализ и интерпретация результатов обработки в целях улучшения качества теста. Проверка соответствия характеристик теста научно обоснованным критериям качества. 15. Коррекция содержания и формы заданий на основании данных предыдущего этапа. Чистка теста и добавление новых заданий для оптимизации диапазона значений параметра трудности и улучшения системообразующих свойств заданий теста. Оптимизация длины теста и времени его выполнения на основании статистических оценок характеристик теста Оптимизация порядка расположения заданий в тесте. 16. Повторение этапа апробации для выполнения очередных шагов по повышению качества теста. 17. Интерпретация данных обработки, установление норм теста и создание шкалы для оценки результатов испытуемых. Апробация, анализ и коррекция теста. Апробация теста неоднократно повторяется. Обычно на разработку стандартизованного теста уходит не менее 3—4 лет, поскольку для апробации важно не только сформировать репрезентативную выборку учащихся, но и выбрать подходящее время в учебном процессе. При разработке теста возникает своеобразный цикл, так как после его чистки создателю приходится возвращаться, к этапу апробация и анализа эмпирических данных тестирования, причем, как правило, не один раз, Тщательная коррекция теста необходима особенно в тех случаях, когда тест должен быть стандартизован, а его результаты планируется использовать для принятия административно-управленческих решений в образовании. 2. Классическая (традиционная) теория тестов Основное предположение классической теории тестов. Предположение о существовании истинного балла (true score) является основополагающим в классической теории тестов. Нередко в одномерных измерениях истинный балл называют параметром учащегося, при этом предполагается, что каждому ученику можно поставить в соответствие единственное на момент измерения значение параметра, не зависящее от применяемого теста. В целом истинный балл — это идеализированная константа испытуемого в гипотетической генеральной совокупности заданий бесконечного теста. Постулаты классической теории тестов. Помимо предположения о существовании истинного балла в классической теории тестов выделяют несколько постулатов, позволяющих построить ма-тематико-статистический аппарат для разработки научно обоснованных тестов и оценки качества результатов педагогических измерений [60; 81]. Эти постулаты связаны с предположениями: - о равенстве ковариаций результатов тестирования по параллельным формам; - о приближении средних значений ошибок измерения истинных баллов к нулю при числе тестирований, стремящемся к бесконечности; - о инвариантности истинных баллов относительно различных параллельных форм теста; - о континуальном (непрерывном) распределении истинных баллов в генеральной совокупности учащихся; - о нормальном законе распределения наблюдаемых баллов, истинных баллов и ошибок измерения.
3. Математико-статистический анализ качества тестов и тестовых заданий на основе классической теории тестов
Матрица тестовых результатов. Если за каждый правильный ответ на задание испытуемому давать один балл, а за неправильный ответ или пропуск задания — нуль баллов, то профиль ответов учащегося будет иметь вид последовательности из единиц и нулей. Поскольку каждая единица или нуль появляются в результате взаимодействия испытуемого с заданием, то наиболее адекватной формой представления наблюдаемых результатов выполнения теста будет служить матрица, т.е. прямоугольная таблица, сводящая воедино профили ответов учащихся (строки из оценок учащегося по всем заданиям теста) и профили заданий теста (столбцы из оценок всех учащихся по каждому заданию теста). Интегрирование данных тестирования в форме матрицы удобно для обработки и отражает взаимодействие множеств испытуемых и заданий, происходящее при выполнении теста (рис. 21). При геометрической интерпретации этого взаимодействия по горизонтальной оси откладываются оценки параметра трудности заданий теста, по вертикальной — оценки подготовленности тестируемых учащихся. Взаимодействие между i-м испытуемым и j-м заданием порождает наблюдаемый ответ Хij, который при дихотомической оценке принимает одно из двух значений (см. табл. 6). 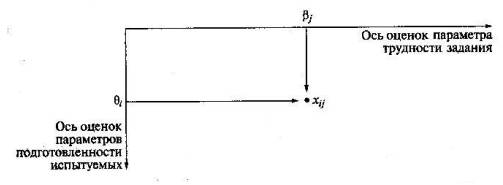 Рис.21 Геометрическая интерпретация взаимодействия множеств испытуемых и заданий теста
Таблица 6
Правило дихотомического оценивания ответа
Таблица 7 Матрица наблюдаемых результатов выполнения теста 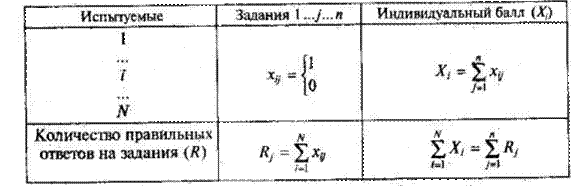 Общий вид матрицы наблюдаемых результатов выполнения N учащимися n заданий теста при дихотомических оценках по заданиям приведен в табл. 7. Справа в матрице, в вертикальном столбце, содержатся индивидуальные баллы учеников Xi (i=1,2,..., N), которые получаются суммированием единиц по горизонтали в каждом профиле ответов, учащегося. Сложение единиц в столбцах по профилям ответов на п заданий теста позволяет получить числа Ri (j=1, 2,..., n), соответствующие количеству правильных ответов на задания теста.
Таблица 8 Матрица результатов тестировании
После занесения результатов выполнения теста в матрицу начинается этап математико-статистической обработки, который включает ряд шагов. Из дидактических соображений для иллюстрации методов обработки выбрана небольшая матрица, когда 10 учеников отвечали всего на 10 заданий теста (табл. 8). Однако все формулы и подсчеты, обсуждаемые в разделе, могут быть распространены на любые выборки испытуемых и применимы к тестам любой длины. Первый шаг математико-статастической обработки эмпирических данных тестирования. На первом шаге обработки данных тестирования подсчитываются индивидуальные баллы и число правильных ответов на каждое задание теста. Для подсчета индивидуального балла суммируются все единицы, полученные учащимся за правильно выполненные задания теста. Например; четвертый испытуемый выполнил правильно 9 заданий, поэтому его индивидуальный балл равен 9. Для удобства полученные индивидуальные баллы Xi{i =1,2, ... ,10) приводятся в последнем столбце матрицы результатов (табл. 9). Число правильных ответов на каждое задание Ri , также получается суммированием единиц, но уже расположенных по столбцам, и размещается в матрице результатов в последней строке под номером соответствующего задания теста.
Таблица 9 Матрица результатов с индивидуальными баллами испытуемых и количеством правильных ответов на задания теста
Второй шаг математико-статистической обработки эмпирических данных тестирования. На втором шаге обработки данных осуществляется упорядочение матрицы результатов тестирования. Для этого производится перестановка столбцов, числа Ri, располагаются в порядке убывания. Затем меняются местами строки матрицы так, чтобы верхняя строка соответствовала обучаемому с минимальным индивидуальным баллом. Значения X, располагаются сверху вниз в порядке возрастания. Упорядоченная матрица данных тестирования приведена в табл. 10. Третий шаг математико-статистической обработки эмпирических данных тестирования. На данном этапе производится графическая интерпретация распределений эмпирических данных, которые можно представить в виде полигона, гистограммы или сглаженной кривой (процентилей, огивы). Для графической интерпретации результатов учащихся необходимо их предварительное упорядочение в виде несгруппированного ряда произвольной формы (табл. 11), ранжированного ряда (табл. 12), частотного распределения или распределения сгруппированных частот [1; 18; 59]. В табл. 11 содержатся индивидуальные баллы испытуемых, взятые из последнего столбца матрицы эмпирических результатов выполнения теста (см. табл. 9). В табл. 12 эти баллы располагаются в порядке возрастания слева — направо, а также приводятся места (ранги) испытуемых, соответствующие их индивидуальным баллам.
Таблица 10 Упорядоченная матрица данных тестирования
Таблица 11 Несгруппированный ряд
Таблица 12 Ранжированный ряд
Данные таблицы удобны для подведения итогов тестирования в работе педагога, поскольку в классе распределения сырых баллов вполне достаточно для сообщения тестовых результатов ученикам. Например, балл 6 обеспечивает первому испытуемому ранг 5 в группе из 10 учеников. Аналогичным образом можно интерпретировать любую оценку ученика в терминах рангов. Очевидно, что равным баллам приписываются равные ранги. Если группа учащихся велика, то для определения рангов используют классификацию оценок по распределению частот или строят сгруппированное частотное распределение. По ряду частотного распределения можно получить графическое представление результатов тестирования в виде полигона частот и гистограммы — последовательности столбцов, каждый из которых опирается на единичный (разрядный) интервал и высота которых пропорциональна частоте наблюдаемых баллов [18; 59].
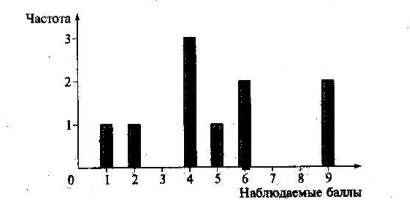
Рис. 22. Столбиковая гистограмма для распределения баллов в матрице, представленной в табл. 9
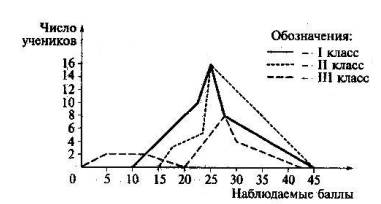
Рис. 23. Сравнение результатов тестирования
Например, матрице, представленной в табл. 10, соответствует гистограмма, приведенная на рис. 22. Середина столбца совмещается с серединой интервала разряда, длина которого равна одному баллу. Для сравнения двух или более распределений обычно используют полигоны частот, так как при наложении гистограмм получается довольно запутанная картина. Например, с помощью полигонов можно сравнить результаты выполнения теста учащимися различных классов, имеющих одинаковое количество учеников (рис. 23). На рисунке отчетливо видно значительное сходство в результатах тестирования у первых двух классов, имеющих довольно похожие полигоны распределения оценок. Четвертый шаг математико-статистической обработки эмпирических данных тестирования. На данном этапе обработки данных оцениваются меры центральной тенденции в распределении результатов тестирования, предназначенные для выявления той точки, вокруг которой в основном группируются все результаты выполнения теста [1; 18; 59]. При анализе результатов тестирования можно использовать разные способы определения такой центральной точки. Наиболее простой из них основан на выявлении моды распределения. Мода — это такое значение, которое встречается наиболее часто среди результатов выполнения теста. Например, для данных матрицы, представленной в табл. 10, модой является балл «4», потому что он встречается чаще (три раза) любого другого значения балла. Распределение может иметь одну или несколько мод. В случае существования двух мод распределение называется бимодальным. Если все значения баллов учеников встречаются одинаково часто, принято считать, что моды у распределения нет.
Среднее выборочное (среднее
арифметическое)
определяется суммированием всех значений совокупности баллов и
последующим делением на их число. Для индивидуальных баллов Х1,
Х2.....XN
группы N
испытуемых среднее значение
X
будет
или
Среднее арифметическое индивидуальных баллов испытуемых для рассмотренного выше примера матрицы (см. табл. 10) равно
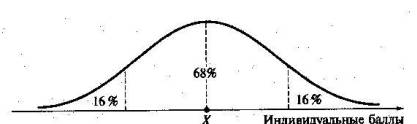
В отличие от моды, фиксирующей одно или несколько значений, на величину среднего влияют значения всех результатов распределения. Таким образом, среднее арифметическое характеризует все распределение в целом. Оно обобщает индивидуальные особенности составляющих распределения на основе уравнивания отдельных значений рассматриваемой величины. С другими свойствами среднего выборочного можно познакомиться в учебнике по статистике. Меры центральной тенденции полезны при оценке качества теста в том случае, когда есть результаты апробации теста на репрезентативной выборке учеников. Обычно считают, что хороший нормативно-ориентированный тест обеспечивает нормальное распределение индивидуальных баллов репрезентативной выборки учеников, когда среднее значение баллов находится в центре распределения, а остальные значения концентрируются вокруг среднего по нормальному закону, т.е. примерно 70 % значений в центре, а остальные сходят на нет к краям распределения, как показано на рис. 24.
Рис. 24. Нормальная кривая распределения индивидуальных баллов
Нормальная кривая — изобретение математиков - в сглаженном идеальном виде описывает реальный полигон частот. На практике никогда не была и не будет получена совокупность данных, распределенных точно по нормальному закону, просто иногда полезно, допуская определенную ошибку, утверждать, что распределение эмпирических данных близко к нормальной кривой. Нормальное распределение унимодально и симметрично, т.е. половина результатов, расположенная ниже моды, в точности совпадает с другой половиной, расположенной выше, а мода и среднее значение равны. Если тест обеспечивает распределение баллов, близкое к нормальному, то это означает, что с его помощью можно определить устойчивое среднее, которое принимается в качестве одной из репрезентативных норм выполнения теста. Обратный вывод неверен: устойчивость тестовых норм вовсе не предполагает обязательного нормального распределения эмпирических результатов выполнения теста. Таким образом, правильно сконструированный нормативно-ориентированный тест на репрезентативной выборке учеников должен обеспечивать близкое к симметричному распределение индивидуальных баллов, когда мода и среднее значение примерно равны, а остальные результаты расположены вокруг среднего по нормальному закону. Пятый шаг математико-статистической обработки эмпирических данных тестирования. На данном этапе определяются описательные характеристики, служащие мерами изменчивости в распределении данных по гесту [1; 18; 59]. Введение мер изменчивости связано с необходимостью выявления дополнительных оснований для сравнения различных распределений по тестам. Если распределения имеют одинаковые средние, то, оценивая и анализируя, меры изменчивости, можно выявить существенные отличия в качестве тестов. Характеристика изменчивости указывает на особенности разброса эмпирических данных вокруг среднего значения: баллов. Отдельные значения индивидуальных баллов могут быть тесно сгруппированы вокруг своего среднего балла или, наоборот, сильно удалены от него. Для отражения характера рассеяния отдельных значений вокруг среднего используются различные меры: размах, дисперсия и стандартное отклонение. Размах измеряет на шкале расстояние, в пределах которого изменяются все значения показателя в распределении. Например, для распределения индивидуальных баллов, представленных в, табл. 10, размах равен 9-1 = 8. Вариационный размах легко вычисляется, но при характеристике распределения баллов по тесту используется крайне редко. Во-первых, размах является весьма приближенным показателем, так как не зависит от степени изменчивости промежуточных значений, расположенных между крайними значениями в распределении баллов по тесту, Во-вторых, крайние значения индивидуальных баллов, как правило, ненадежны, поскольку содержат в себе значительную ошибку измерения. В этой связи более удачной мерой изменчивости считается дисперсия. Подсчет дисперсии основан на вычислении отклонений Х1 - Х (i =1, 2, …, N) каждого значения показателя от среднего арифметического в распределении. Для ученика с индивидуальным баллом выше среднего значение разности Х1-X будет положительно, а для тех, у кого, результат ниже X, отклонение Х1 - X будет меньше нуля. Если просуммировать все отклонения, взятые со своим знаком, то для симметричных распределений сумма будет равна нулю. Чтобы отрицательные и положительные слагаемые не уничтожали друг друга, каждое отклонение возводят в квадрат, а затем находят сумму квадратов отклонений. Эта сумма будет большой, если результаты тестирования отличаются существенной неоднородностью, и малой — в случае близких результатов испытуемых по тесту. Для матрицы, представленной в табл. 9, сумма квадратов отклонений будет равна
Величина суммы зависит от размера выборки учеников, выполнявших тест, поэтому для сопоставимости мер изменчивости распределений, отличающихся по объему, каждую сумму делят на N - 1, где N - число учеников, выполнявших тест. Определяемая таким образом мера изменчивости называется исправленной дисперсией. Она обычно обозначается символом S2x и вычисляется по формуле
Для рассматриваемого примера
Кроме дисперсии для характеристики меры изменчивости распределения удобно использовать еще один показатель вариации, который называется стандартным отклонением и вычисляется путем извлечения квадратного корня из дисперсии:
Для рассматриваемого примера данных
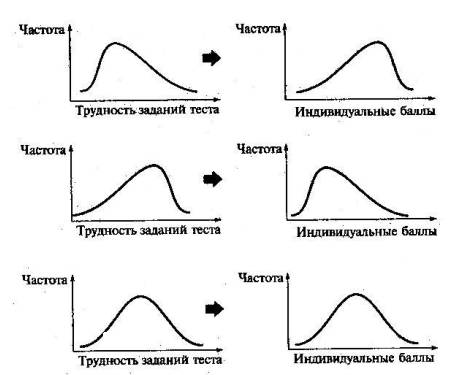
тестирования Дисперсия играет важную роль в оценке качества тестов. Низкая дисперсия указывает на плохое качество нормативно-ориентированного теста, поскольку не обеспечивается высокий дифференцирующий эффект. Излишне высокая дисперсия, характерная для случая, когда все учащиеся различаются по числу выполненных заданий, также требует переработки теста из-за существенного отличия вида распределения баллов от плакируемой нормальной кривой. Использование стандартного отклонения как меры вариации особенно эффективно для нормального распределения баллов испытуемых, поскольку в этом случае можно прогнозировать процент данных, лежащих внутри одного, двух и трех стандартных отклонений, откладываемых от центра распределения. В любом нормальном распределении приблизительно 68% площади под кривой лежит в пределах одного стандартного отклонения, откладываемого влево и вправо от среднего (т.е. X ± 1Sx); 95% площади под кривой расположено в пределах двух. Sx, (X±2SX); 99,7% площади под кривой — в пределах трех Sx,. (X ± 3Sх). Из всех нормальных кривых наиболее удобна единичная, площадь под которой равна 1. Для нее среднее значение равно нулю (z=0), а стандартное отклонение единице (аг = 1). При использовании теста необходимо помнить о том, что получаемое распределение индивидуальных баллов учащихся является следствием подбора трудности заданий теста, как показано на рис. 25. .Для верхнего распределения слева характерно смещение в сторону легких заданий, поэтому большая часть учащихся выполнит почти все задания теста и получит высокие индивидуальные баллы, показанные на правом верхнем рисунке. Средние графики отражают тенденцию к приоритетному подбору самых трудных заданий при разработке теста и вытекающий отсюда всплеск у начала горизонтальной оси там, где располагаются низкие индивидуальные баллы. Тест, представленный на нижнем графике слева, обладает сбалансированной трудностью, что автоматически приводит к нормальности распределения индивидуальных баллов репрезентативной выборки учеников. Это позволяет считать полученное распределение устойчивым по отношению к генеральной совокупности, а также помогает определить репрезентативные нормы выполнения теста. Последующие шаги обработки данных предназначаются для оценивания мер симметрии и островершинности кривых распределений [1; 18; 60; 63] и выполняются обычно при разработке тестов административно-управленческого предназначения не «руками», а с помощью специальных статистических пакетов для ПК.
Рис. 25. Связь распределения индивидуальных баллов и трудности заданий теста
4. Показатели связи между заданиями теста
Корреляция результатов учащихся по заданиям. Для итогового контроля полезно вычислять показатели связи между результатами учеников по отдельным заданиям теста. При этом важно понять, существует ли тенденция, когда одни и те же ученики добиваются успеха в какой-либо паре заданий теста, или состав учеников, добивающихся успеха, полностью меняется при переходе одного задания теста к другому. Ответ на вопрос о существовании связи между двумя наборами данных получают с помощью корреляции [18; 60; 63]. Для ее оценивания в общем случае применяют коэффициент корреляции Пирсона г,у, значения которого меняются в интервале от -1 до +1.
где Xl, ..., XN — первый набор данных со средним значением X, а Y1,,.,., YN — второй набор данных со средним значением Y. При исследовании связи между наборами данных необходимо правильно выбрать вид и форму показателя, зависящие от шкал, в которых представлены данные [18]. В частности, для оценки связи между результатами выполнения учащимися двух заданий теста коэффициент корреляции Пирсона rху необходимо преобразовать, поскольку результаты выполнения заданий представляются в дихотомической шкале (столбцы из нулей и единиц в матрице данных по тесту). Преобразованный коэффициент Пирсона для дихотомических данных называется коэффициентом «фи» и вычисляется по формуле
где Pji — доля испытуемых, выполнивших правильно оба задания с номерами j и l, т.е. доля тех, кто получил «1» по обоим заданиям; pj — доля испытуемых, правильно выполнивших одно j-е задание, qj =1 – рj, Pl — доля испытуемых, правильно выполнивших l-е задание теста, qt = 1 -р,. Анализ значений коэффициента корреляции р позволяет выявить неудачные задания теста, которые отрицательно коррелируют с большинством остальных заданий и, следовательно, измеряют нечто иное, чем та переменная, для которой предназначался тест. Отрицательные значения коэффициента корреляции указывают на определенный просчет разработчиков в содержании заданий, которые рекомендуется удалить из теста. Наиболее распространенная причина появления отрицательной корреляции — отсутствие предметной чистоты содержания — встречается при разработке самых разных тестов довольно часто. Предметная чистота — скорее идеализируемое, чем реальное, требование к содержанию любого теста. Так, в любом тесте по физике встречаются задания с большим количеством математических преобразований, в тесте по биологии — задания, требующие, серьезных знаний по химии, в тесте по истории — задания, рассчитанные на выявление культурологических знаний, и т.п. Поэтому можно лишь стремиться к тому, чтобы при выполнении каждого задания доминировали знания по проверяемому предмету. Для тематических тестов характерна высокая корреляция между заданиями, так как они в большинстве случаев имеют слабо варьирующее исходное содержание, что вполне объясняется назначением теста. Однако в итоговых тестах по возможности стараются избегать высокой корреляции между заданиями, поскольку вряд ли имеет смысл включать в итоговый тест несколько заданий, оценивающих одинаковые содержательные элементы. В итоговых тестах обычно стремятся к невысокой положительной корреляции, когда значения коэффициента варьируют в интервале (0; 0,3) и каждое задание вносит свой вклад в общее содержание теста. Бисериальный коэффициент корреляции. Бисериальный коэффициент корреляции используется в том случае, когда один набор значений распределения задается в дихотомической шкале, а другой — в интервальной. Под эту ситуацию подпадает подсчет корреляции между результатами выполнения каждого задания (дихотомическая шкала) и суммой баллов испытуемых по заданиям теста (интервальная или квазиинтервальная шкала). С помощью подсчета значений бисериального коэффициента корреляции оценивается валидность, иногда называемая показателем дифференцирующей способности (дискриминативности) заданий теста. Объяснение, на котором основан вывод формулы для подсчета бисериального коэффициента корреляции, приводится в ряде исследований [18; 60; 73]. Его вычисление требует использования специальных таблиц для нахождения ординат стандартной нормальной кривой и определенной математической подготовки. Поэтому нередко используют другой коэффициент корреляции, называемый точечным бисериальным коэффициентом — rpbis. Основанием для подобной замены служит близость значений этих коэффициентов: первый незначительно превышает второй, если они подсчитаны для одних и тех же наборов данных из распределений. Однако формула для rpbis намного проще, поэтому именно ему часто отдают предпочтение в практической работе. Анализ значений коэффициента бисериальной корреляции, подсчитанного для оценки связи результатов по каждому заданию с суммой баллов по тесту, позволяет выявить задания с низкой валидностью, с помощью которых трудно отделить хорошо подготовленных учащихся от слабо подготовленных учащихся тестируемой группы. Значения, близкие к нулю, указывают на низкую дифференцирующую способность заданий теста. Если коэффициент бисериальной корреляции принимает отрицательные значения, задание следует удалить из теста, так как при выполнении такого теста слабые ученики выполняют его верно, а сильные выбирают неверный ответ либо пропускают задание. 5. Оценка характеристик заданий теста
Оценка трудности заданий по классической теории тестов. Оценка трудности тестовых заданий в классической теорий тестов осуществляется по формуле
где pj — доля правильных ответов на j-е задание; Rj - количество учеников, выполнивших j-е задание верно; N- число учеников в тестируемой группе; j — номер задания теста (j= 1, 2 , …, n). Трудность задания нередко выражают в процентах. Для этого оценку, полученную по формуле (8), умножают на 100%. Долю правильных ответов на задание p j правильнее было бы назвать легкостью задания, в то время как трудность ассоциируется с долей неправильных ответов qj, которая находится путем вычитания pj из единицы: qj = 1 - pj. Однако по сложившейся традиции в классической теории тестов за трудность задания принимается именно доля pj. Подбор заданий по трудности в нормативно-ориентированных тестах. В хорошо сбалансированном по трудности тесте всегда есть несколько самых легких заданий со значениями р -> 0 и несколько самых трудных со значением р -> 1. Остальные задания по значениям р занимают промежуточное положение между этими крайними ситуациями и имеют в основном трудность 60—70 %. Дополнительный аргумент в пользу преимущественного включения заданий средней трудности с р = 0,5 связан с подсчетом дисперсии по каждому заданию теста, которая для дихотомического набора данных будет равна оj, = pjqj (j =1,2, ..., п). Так как произведение pjqj; достигает максимального значения (0,5 • 0,5 = 0,25) при pj= 0,5 - qj, в рамках нормативно-ориентированного подхода наиболее удачными считаются задания средней трудности р = q = 0,5, обеспечивающие максимальный вклад в общую дисперсию теста. В пользу преимущественного выбора заданий средней трудности также говорит подсчет ошибки измерения, которая уменьшается по мере продвижения к центру, где расположены задания средней трудности, и увеличивается на концах распределения Связь оценок трудности и валидностн заданий. Интересна взаимосвязь показателей трудности и валидности (дискриминативности) заданий теста. Задания с высокой дискриминативностъю обычно имеют среднюю трудность, поскольку именно для них характерен в первую очередь высокий дифференцирующий эффект. Однако обратное заключение неверно. Задания с р = 0,5 могут иметь как высокий, так и низкий дифференцирующий эффект. При подсчете статистик по тесту всегда проводится проверка значимости полученных оценок дисперсии, асимметрии и т д. Для этого к данным, собранным по тесту, необходимо добавить информацию о принимаемом уровне риска допущения ошибки в статистическом выводе. Наиболее приемлемым для педагогических измерений является уровень в 5 %, который допускает ошибку в 5 случаях из 100. После выбора степени риска проверка значимости проводится одним из описанных в литературе методов [18; 74]. Гомогенность (содержательная однородность) задания. При конструировании теста необходимо иметь четкое представление о содержании заданий, которые предполагается включить в окончательную версию теста. При одномерных измерениях содержание заданий должно отвечать свойству гомогенности, указывающему на степень его однородности с точки зрения оцениваемого параметра подготовленности ученика. Таким образом, гомогенность (однородность) — это характеристика задания, отражающая степень соответствия его содержания измеряемому свойству ученика. Степень гомогенности содержания обычно оценивают с помощью факторного и корреляционного анализа.
Дайте интерпретацию полученных результатов. Наблюдается ли инвариантность вычисленных характеристик задания относительно уровня подготовленности выборки? Как можно объяснить наличие (отсутствие) инвариантности?
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||