Иллюстрация 1. Разбиение диска двухсистемного компьютера
В лекции Этапы загрузки системы говорилось о том, что аппаратный профиль компьютера определяется ядром на ранних этапах загрузки системы или в процессе подключения модуля. Это не означает, что устройство, не распознанное ядром, задействовать невозможно. Если неизвестным ядру устройством можно управлять по какому-нибудь стандартному протоколу, вполне возможно, что среди пакетов Linux найдётся утилита или служба, способная с этим устройством работать. Например, программа записи на лазерный диск cdrecord знает великое множество разнообразных устройств, отвечающих стандарту SCSI, в то время как ядро, как правило, только позволяет работать с таким устройством как с обычным лазерным приводом (на чтение), и передавать ему различные SCSI-команды.
К сожалению, иногда и обратное неверно: если производитель создаёт новое устройство, управлять которым нужно по-новому, а распознаётся оно как одно из старых, ошибки неизбежны. Многие стандарты внешних устройств предусматривают строгую идентификацию модели, однако хорошего мало и тут: незначительно изменив схемотехнику, производитель меняет и идентификатор, и устройство перестаёт распознаваться до тех пор, пока автор соответствующего модуля Linux не заметит это и не добавит новый идентификатор в список поддерживаемых.
Большинству распознанных устройств, если они должны поддерживать операции чтения/записи или хотя бы управления (ioctl(), описанный ниже), соответствует файл-дырка в каталоге /dev или одном из его подкаталогов. В зависимости от того, выбрана ли в системе статическая или динамическая схема именования устройств, файлов-дырок в /dev может быть и очень много, и относительно мало. При статической схеме именования то, что ядро распознало внешнее устройство, никак не соотносится с тем, что в /dev имеется для этого устройства файл-дырка:
[root@localhost root]# cat /dev/sdg14
cat: /dev/sdg14: No such device or address
Пример 1. Обращение к несуществующему устройству
Здесь Мефодий попытался прочитать что-либо из устройства /dev/sdg14, что соответствует четырнадцатому разделу SCSI-диска под номером семь. Такого диска в этой машине, конечно, нет, а файл-дырка для него заведён на всякий случай: вдруг появится? Поскольку появиться может любое из поддерживаемых Linux устройств, таких файлов «на всякий случай» в системе бывает и десять тысяч, и двадцать. Файл-дырка не занимает места на диске, однако использует индексный дескриптор, поэтому в корневой файловой системе, независимо от её объёма, индексных дескрипторов должен быть изрядный запас.
При динамической схеме именования применяется специальная виртуальная файловая система, которая либо полностью подменяет каталог /dev, либо располагается в другом каталоге (например, /sys), имеющем непохожую на /dev иерархизированную структуру; в этом случае файлы-дырки в /dev заводит специальная служба. Этот способ гораздо удобнее и для человека, который запустил команду ls /dev, и для компьютера (в случае подключения внешних устройств, например, съёмных жёстких дисков, «на лету»). Однако он требует соблюдать дополнительную логику «привязки» найденного устройства к имени, иногда весьма запутанную из-за той же нечёткой идентификации. Поскольку происходить это должно в самый ответственный момент, при загрузке системы, динамическую схему именования используют с осторожностью.
Кое-какие идеи динамического именования устройств присутствуют и в статической схеме. Так, файлы /dev/mouse или /dev/cdrom, на самом деле — символьные ссылки на соответствующие файлы-дырки. Если тип мыши или лазерного привода изменится, достаточно изменить эти ссылки и перезапустить соответствующие службы.
[root@localhost root]# ls -l /dev/cdrom /dev/mouse
lrwxrwxrwx 1 root root 8 Nov 20 23:23 /dev/cdrom -> /dev/hdc
lrwxrwxrwx 1 root root 5 Nov 9 01:16 /dev/mouse -> psaux
[root@localhost root]# ls -lL /dev/cdrom /dev/mouse /dev/hda1 /dev/ur* /dev/ze*
brw-r----- 1 root cdrom 22, 0 Jul 26 16:59 /dev/cdrom
brw-rw---- 1 root disk 3, 1 Jul 26 16:59 /dev/hda1
crw------- 1 root root 10, 1 Dec 2 11:58 /dev/mouse
crw-r--r-- 1 root root 1, 9 Nov 28 14:10 /dev/urandom
crw-rw-rw- 1 root root 1, 5 Jul 26 16:59 /dev/zero
Пример 2. Идентификация внешних устройства в /dev/
Файл-дырка, как и всякая дырка, не имеет никакого размера: сколько в неё не записывай, в файл на диске ничего не попадёт. Вместо этого ядро передаёт всё записанное драйверу, отвечающему за файл-дырку, а тот по-своему обрабатывает эти данные. Точно так же работает и чтение из файла-дырки: все запрашиваемые данные в неё подсовывает драйвер. Большинство драйверов — дисковые, звуковые последовательных и параллельных портов и т. п. — обращаются за данными к какому-нибудь внешнему устройству или передают их ему. Но есть и такие, кто сам всё выдумывает: это и /dev/null, чёрная дыра, в которую что угодно можно записать, и оно пропадёт безвозвратно, и /dev/zero, из которого можно считать сколько угодно нулей (на запись оно ведёт себя как /dev/null), и /dev/urandom, из которого можно считать сколько угодно относительно случайных байтов.
Изучив выдачу команды ls -lL (ключ “-L” заставляет ls выводить информацию не про символьную ссылку, а про файл, на который она указывает), Мефодий обнаружил, что та вместо размера файла-дырки (который равен нулю) выводит два числа. Первое из этих чисел называется старшим номером устройства (major device number), оно, грубо говоря, соответствует драйверу, отвечающему за устройство. Второе называется младшим номером устройства (minor device number), оно соответствует способу работы с устройством, а для дисковых носителей — разделу. В частности, из примера видно, что устройствами /dev/random и /dev/urandom занимается один и тот же драйвер со старшим номером 1. При этом часть устройств (по преимуществу — дисковые) имеет тип «b», а другая часть — «c» (этот тип имеют, например, терминалы). Тип указан в атрибутах файла первым символом. Это блочные (block) устройства, обмен данными с которыми возможен только порциями (блоками) определённого размера, и символьные (character) устройства, запись и чтение с которых происходит побайтно. Блочные устройства, вдобавок, могут поддерживать команды прямого доступа вида «прочитать блок номер такой-то» или «записать данные на диск, начиная с такого-то блока».
Блочные и символьные устройства — полноправные объекты файловой системы, такие же, как файлы, каталоги и символьные ссылки. Есть ещё два типа специальных файлов — каналы и сокеты. Канал-файл (или fifo) называют ещё именованным каналом (named pipe): это такой же объект системы, как и тот, что используется командной оболочкой для организации конвейера (его называют неименованным каналом), разница между ними в том, что у fifo есть имя, он зарегистрирован в файловой системе. Это — типичный файл-дырка, причём дырка двухсторонняя: любая программа может записать в канал (если позволяют права доступа) и любая программа может оттуда прочитать. Создать именованный канал можно с помощью команды mkfifo:
methody@localhost:~ $ mkfifo hole
methody@localhost:~ $ ( date >> hole & head -1 < hole ) 2> /dev/null
Птн Дек 3 15:11:05 MSK 2004
methody@localhost:~ $ ( cal >> hole & head -1 < hole ) 2> /dev/null
Декабря 2004
methody@localhost:~ $ rm hole
Пример 3. Использование именованного канала
Здесь важно, что утилита head показывает начало не «файла» hole а именно последней записываемой порции данных, как и подобает трубе1.
Что же касается сокетов, то это — более сложные объекты, предназначенные для связи двух процессов и передачи информации в обе стороны. Сокет можно представить в виде двух каналов (один «туда», другой «обратно»), однако стандартные файловые операции открытия/чтения/записи на нём не работают. Процесс, открывший сокет, считается сервером: он постоянно «слушает», нет ли в нём новых данных, а когда те появляются, считывает их, обрабатывает, и, возможно, записывает в сокет ответ. Процесс-клиент может подключиться к сокету, обменяться информацией с процессом-сервером и отключиться. Точно так же можно передавать данные и по сети, в этом случае указывается не путь к сокету на файловой системе (т. н. unix domain socket), а сетевой адрес и порт удалённого компьютера (например internet socket, если подключаться с помощью сети Internet).
Как уже говорилось в лекции Этапы загрузки системы, часть системы, отвечающая за взаимодействие с каким-нибудь внешним устройством и называемая «драйвер», в Linux либо входит в ядро, либо оформляется в виде модуля ядра, и подгружается по необходимости. Следовательно, файл-дырка, обращение к которому приводило к «no such device or address», вполне может и заработать (в этом одна из причин огромного количества устройств в /dev). Гуревич наотрез отказался объяснять Мефодию «как добавить новый драйвер» до тех пор, пока тот не будет лучше разбираться в архитектуре компьютеров вообще и в аппаратной части IBM-совместимых компьютеров в частности. Поэтому всё, что смог понять Мефодий, не имея таких знаний, сводилось к следующему. Во-первых, если существуют различия между тем, как по умолчанию загружает модули система и тем, как на самом деле это необходимо делать, различия должны быть описаны в файле /etc/modules.conf. Во-вторых, после изменения этого файла, добавления нового устройства, обновления самих модулей и т. п. следует запускать утилиту depmod, которая заново выстраивает непротиворечивую последовательность загрузки модулей. В-третьих, интересно (но в отсутствие знаний — малопознавательно) запускать утилиту lspci, которая показывает список устройств (распознаваемых по стандарту PCI), найденных на компьютере.
Все файлы-дырки подчиняются одним и тем же правилам работы с файлами: их можно открывать для записи или чтения, записывать данные или считывать их стандартными средствами, а по окончании работы — закрывать. Открытие и закрытие файла (системные вызовы open() и close()) в командном интерпретаторе не представлено отдельной операцией, оно выполняется автоматически при перенаправлении ввода (открытие на чтение) или вывода (на запись). Это позволяет работать и с устройствами, и с каналами, и с файлами совершенно одинаково, что активно используется в Linux программами-фильтрами. Каждый тип файлов имеет свою специфику, например, при записи на блочное устройство данные накапливаются ядром в специальном буфере размером в один блок, и только после заполнения буфера записываются. Если при закрытии файла буфер неполон, он всё равно передаётся целиком: часть — данные, записанные пользователем, часть — данные, оставшиеся от предыдущей операции записи). Это, конечно, не означает, что из файла, находящегося на блочном устройстве, легко по ошибке прочитать такой «мусор»: длина файла известна, и ядро само следит за тем, чтобы программа не прочла лишнего.
Даже такие (казалось бы) простые устройства, как жёсткие диски, поддерживают гораздо больше различных операций, чем просто чтение или запись. Пользователю, как минимум, может потребоваться узнать размер блока (для разных типов дисков он разный) или объём всего диска в блоках. Для многих устройств собственно передача данных — лишь итог замысловатого общения с управляющей программой или ядром. Скажем, для вывода оцифрованного звука на звуковую карту сначала необходимо настроить параметры звукогенератора: частоту, размер шаблона, количество каналов, формат передаваемых данных и многое другое. Для управления устройствами существует системный вызов ioctl() (iput-output control): устройство надо открыть, как файл, а затем использовать эту функцию. У каждого устройства — свой набор команд управления, поэтому в виде отдельной утилиты ioctl() не встречается, а используется неявно другими утилитами, специализирующимися на определённом типе устройств.
Некоторые устройства просто обязаны быть доступны пользователю на запись и чтение. Например, виртуальная консоль, за которой работает Мефодий, доступна пользователю methody на запись и на чтение, именно поэтому командный интерпретатор Мефодия может посылать туда символы и считывать их оттуда. В то же время, терминал, за которым работает Гуревич, пользователю недоступен, а терминалы, за которыми не работает никто, доступны только суперпользователю:
methody@localhost ~ $ who
methody tty1 Dec 3 16:02 (localhost)
shogun ttyS0 Dec 3 16:03 (localhost)
methody@localhost ~ $ ls -l /dev/tty1 /dev/tty2 /dev/ttyS0
crw--w---- 1 methody tty 4, 1 Дек 3 16:02 /dev/tty1
crw------- 1 root root 4, 2 Дек 3 15:51 /dev/tty2
crw--w---- 1 shogun tty 4, 64 Дек 3 16:03 /dev/ttyS0
methody@localhost:~ $ ls -l /usr/bin/write
-rwx--s--x 1 root tty 8708 Июн 25 14:00 /usr/bin/write
Пример 4. Кому принадлежат терминалы?
Права на владение терминалом передаются с помощью chown пользователю программой login после успешной регистрации в системе. Она же выставляет право записи на терминал членам группы tty. «Настоящих» пользователей в этой группе может и не быть, зато есть setGID-программы, например, write, которая умеет выводить сообщения сразу на все активные терминалы.
Множество устройств в системе, используемой как рабочая станция, также отдаются во владение — на этот раз, первому пользователю, зарегистрировавшемуся в системе. Предполагается, что компьютер служит в качестве рабочей станции именно этого пользователя, а все последующие доступа к этим устройствам не получат2. Как правило, так поступают с устройствами, которые могут понадобиться только одному человеку, сидящему за монитором: звуковыми и видеокартами, лазерными приводами, дисководом и т. п.:
shogun@localhost ~ $ ls -l /dev | grep methody | wc
665 6649 41459
shogun@localhost ~ $ ls -lL /dev/{audio,cdrom,fd0,hda,kmem}
crw-rw---- 1 methody audio 14, 4 Июл 26 16:59 /dev/audio
brw-r----- 1 methody cdrom 22, 0 Июл 26 16:59 /dev/cdrom
brw-rw---- 1 methody floppy 2, 0 Июл 26 16:59 /dev/fd0
brw-rw---- 1 root disk 3, 0 Июл 26 16:59 /dev/hda
crw-r----- 1 root kmem 1, 2 Июл 26 16:59 /dev/kmem
Пример 5. Кому принадлежат устройства?
При этом для того, чтобы обеспечить и другим — псевдо- или настоящим — пользователям, такие устройства также принадлежат определённым группам с соответствующими правами. Практика «раздачи» устройств группам вообще очень удобна: даже если доступ к устройству имеет только суперпользователь, существует возможность написать setGID-программу, которая, не получая суперпользовательских прав, сможет до этого устройства добраться (а можно и просто включить опытного пользователя в такую группу).
В начале лекции говорилось о том, что младший номер устройства, соответствующего жёсткому диску, обычно указывает на определённый раздел этого диска. Поначалу Мефодию казалось, что смысла «пилить» диск на несколько разделов нет никакого: известно, что один большой раздел файловой системы Linux3 вмещает чуть больше данных, чем несколько маленьких того же объёма. Кроме того, разбивая диск на разделы, можно не предугадать подходящие размеры этих разделов, и тогда размещение на них файловой системы Linux окажется делом нелёгким, если вообще возможным, так как структура дерева каталогов Linux строго определена стандартом FHS (см. лекцию Структура файловой системы).
Впрочем, в том же FHS весьма наглядно обоснована необходимость разнесения всего дерева каталогов по разным разделам, каждый из которых будет иметь собственную файловую систему. Каталоги сильно различаются по тому, как часто приходится в них записывать, насколько надёжность хранения данных в них важнее быстродействия и насколько ситуация переполнения файловой системы опасна и может помешать работе. Поэтому стоит каталог /tmp, требующий очень частой записи, но не требующий надёжного хранения данных после перезагрузки, держать не на том же разделе, что и корневую файловую систему, запись в которую происходит редко (в каталог /etc), но требует повышенной надёжности. В отдельный раздел можно поместить весь каталог /usr, так как он вообще не требует операций записи. Наконец, такие каталоги, как /var или /home, суммарный объём файлов в которых с трудом поддаётся контролю со стороны системы, тоже не следует размещать на том же разделе, что и корневую файловую систему, переполнение которой может быть болезненно воспринято Linux.
К тому же на компьютере может быть установлено несколько операционных систем, и каждой из них понадобится для корневой файловой системы отдельный раздел. В этой и предыдущей лекции Мефодий работает именно за такой машиной: помимо Linux, на ней установлен FreeDOS для запуска одной-единственной программы.
Разбиение диска на разделы — дело (теоретически) несложное: какая-то часть диска должна быть отведена под таблицу разделов, в которой и будет написано, как разбит диск. Стандартная таблица разделов для диска IBM-совместимого компьютера — HDPT (hard disk partition table) — располагается в конце самого первого сектора диска, после предзагрузчика (master boot record, MBR) и состоит из четырёх записей вида «тип начало конец», описывающих очередной раздел диска (если раздела нет, поле тип устанавливается в 0). Разделы, упомянутые в HDPT диска, принято называть основными (primary partition). Устройство Linux, соответствующее первому диску компьютера, обычно называется /dev/hda (hard disk «a»). Второй диск получает имя hdb, третий — hdc и так далее. На типичном IBM-совместимом компьютере такое же имя получит и лазерный накопитель. Часто бывает, что жёсткий диск — первый в системе (hda), а лазерный накопитель — третий (hdc), второго же вовсе нет. Устройства, соответствующие основным разделам диска, называются /dev/hdбукваномер, для первого диска — от hda1 до hda4. Просмотреть список разделов можно с помощью команды fdisk -l.
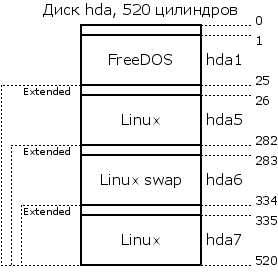
На той самой — двухсистемной — машине fdisk обнаружила пятый, шестой и седьмой разделы, однако не показала ни третий, ни четвёртый:
[root@localhost root]# fdisk -l
Disk /dev/hda: 2147 MB, 2147483648 bytes
128 heads, 63 sectors/track, 520 cylinders
Units = cylinders of 8064 * 512 = 4128768 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 25 100768+ 6 FAT16
/dev/hda2 26 520 1995840 5 Extended
/dev/hda5 26 282 1036192+ 83 Linux
/dev/hda6 283 334 209632+ 82 Linux swap
/dev/hda7 335 520 749920+ 83 Linux
Пример 6. Просмотр таблицы разделов жёсткого диска
Дело в том, что четырёх разделов редко когда бывает достаточно. Куда же помещать дополнительные поля таблицы разбиения? Создатели IBM PC предложили универсальный способ: один из четырёх основных разделов объявляется расширенным (extended partition); он, как правило, занимает всё оставшееся пространство диска. Расширенный раздел разбивается на подразделы по тем же правилам, что и весь диск: в самом его начале заводится HDPT с четырьмя записями (соответствующие им разделы называются дополнительными, secondary partition), которые снова можно использовать, причём один из подразделов может быть, опять-таки, расширенным, со своими подразделами и т. д.
fdisk! Она предназначена для создания, изменения и удаления разделов диска.Чтобы не усложнять эту схему, при разметке диска соблюдают два правила: во-первых, расширенных разделов в таблице разбиения диска может быть не более одного, а во-вторых, таблица разбиения расширенного раздела может содержать либо одну запись — описание дополнительного раздела, либо две — описание дополнительного раздела и описание вложенного расширенного раздела. Соблюдение этого правила позволяет в Linux нумеровать разделы линейно: после четырёх основных, номер 5 получает дополнительный раздел в первом расширенном, 6 — раздел во втором расширенном, вложенным в первый, и т. п. Сами вложенные расширенные разделы при этом не нумеруются и никакому устройству в /dev/ не соответствуют. В действительности разбиение диска двухсистемной машины Мефодия выглядит так:
Иллюстрация 1. Разбиение диска двухсистемного компьютера
И разделы, и таблицы разбиения принято размещать с начала цилиндра (термин, имеющий отношение к внутреннему устройству жёсткого диска), так что при заведении каждого расширенного раздела на этом компьютере тратилось впустую по четыре мегабайта (таков, по словам fdisk, размер цилиндра).
Той же тактикой — разбиением не диска, а раздела — пользуются, когда таблица разбиения нестандартна для IBM PC. Например, UNIX-подобные системы семейства BSD используют собственный универсальный формат разбиения (он старше, чем сама идея об IBM PC!), для чего подобной системе выделяется один раздел, и она творит с ним всё, что заблагорассудится.
Итак, Linux на компьютере из примера использует три раздела: hda5, hda6 и hda7. Тип раздела hda6, «Linux sawp», отличается от двух других, по словам Гуревича, «это вообще не файловая система». Это — т. н. область подкачки (swap space), пространство на диске, используемое системой для организации виртуальной памяти. Оказывается, областям оперативной памяти, которые процессы запрашивают у ядра, не всегда соответствуют части физической оперативной памяти. Если процесс долгое время не использует заказанную оперативную память, её содержимое записывается на диск, в область подкачки — тем самым освобождается место в физической памяти для других процессов. Когда же он «вспомнит» об этой области памяти, ядро подкачает её с диска, разместит в оперативной памяти (возможно, откачав другие области), и только тогда позволит процессу продолжить работу.
Вполне может сложиться ситуация, когда несколько процессов заказали оперативной памяти больше, чем её есть в действительности, и преспокойно работают, потому что не используют всё заказанное пространство сразу, позволяя системе откачивать неиспользуемые области. К тому же многие процессы (особенно демоны) не работают постоянно, а ждут наступления определённого события, и чем дольше они ждут, тем дольше не используют оперативную память, и тем выше вероятность, что ядро откачает её.
Стоит отдавать себе отчёт, что если эти самые процессы вдруг захотят работать одновременно и со всеми областями памяти, ядру придётся туго. Большую часть времени система будет проводить откачивая и подкачивая, потому что дисковые операции чтения и записи работают в тысячи раз медленнее, чем запись и чтение из оперативной памяти4. Чтобы хоть как-то облегчить ему жизнь, область подкачки размещают на отдельном разделе, обмен данными с которым работает быстрее, чем чтение и запись в файл, обслуживаемые файловой системой.
Из лекции Структура файловой системы Мефодий узнал, как пользоваться файловой системой и какую структуру она имеет с точки зрения программы, работающей с файлами в ней. Про то, как организована файловая система изнутри, что именно находится от начала устройства hda5 до его конца, существует немало больших статей, защищено немало кандидатских (и более одной докторской) диссертаций. Разработка файловой системы — сложный и интересный процесс, требующий одновременно владения высшей математикой, статистикой, умения безошибочно программировать и полного знания того, как работает то или иное дисковое устройство. Поэтому файловых систем не так много, и каждая из них устроена по-особому, в соответствии с тем, как решал тот или иной творческий коллектив задачу быстрого и надёжного доступа к файлам.
Во всех файловых системах есть и немало общего. Например, в каждой из них решается вопрос метаданных, то есть информации, не имеющей прямого отношения к содержимому, допустим, файла, но описывающей, как до этого содержимого добраться. В файловой системе обычно различается системная область, в которой записываются метаданные, и область данных, в где хранятся собственно файлы. Системная область может составлять заметную долю общего дискового пространства, и вот почему.
Различают устройство последовательного доступа (например, накопители на магнитных лентах) и устройства прямого доступа (например, жёсткие диски). Чтение (и запись) данных на устройствах последовательного доступа идёт последовательно: если сейчас записан первый блок носителя, то следующим будет доступен второй, за ним — третий и т. д. Если доступен пятый блок, а нужен первый или тысячный, выполняется длительная операция позиционирования, причём она тем длиннее, чем дальше отстоит нужный блок от текущего: лента перематывается. Работа с устройствами прямого доступа легче: каков бы ни был текущий прочитанный блок, время, за которое будет прочитан любой другой примерно одинаково.
Файлы на магнитной ленте удобнее хранить целиком, каждый файл — одним длинным куском. У такого способа есть один существенный недостаток: если на ленту объёмом в гигабайт записать 1024 мегабайтных файла, а потом удалить каждый второй, то образуется полгигабайта свободного места, но кусочками по мегабайту каждый. Тогда запись, скажем, двухмегабайтного файла потребует трёх операций: сначала надо переписать какой-нибудь мегабайтный файл на свободное место, затем удалить старую его копию, и только затем записать на образовавшееся место большой файл.
На устройстве прямого доступа можно избежать этой неприятной ситуации, если постановить, что файл может размещаться на нём в области данных по частям, а карта размещения этих частей будет записана в системную область. Если, не мудрствуя особо, предположить, что в системную область записываются номера полукилобайтных секторов, в которых лежит файл (по 32 бита каждый номер), то выходит, что размер системной области, который может потребоваться, всего в 16 раз меньше файловой. Но в Linux в системную область записываются индексные дескрипторы, размер которых существенно больше. Количество индексных дескрипторов может быть намного меньше количества блоков, но всё же системная область занимает примерно такую же (от пяти до десяти процентов) долю общего дискового пространства.
На самом деле, даже на жёстком диске блоки, расположенные подряд, считываются (и записываются) быстрее, чем блоки, расположенные как попало. Эффект связан с механическим устройством жёстких дисков, пояснять которое Мефодию Гуревич не стал, ссылаясь на общеизвестность. Суть его в том, что задержки при чтении данных, находящихся на разных цилиндрах диска, растут линейно, как для ленты (чем дальше, тем дольше). Один из остроумных способов оптимизировать работу с диском состоит в том, чтобы разбить все цилиндры на группы, а внутри каждой группы выделить свою системную область и область данных. Тогда сами файлы и их индексные дескрипторы будут лежать, если это возможно, на соседних цилиндрах, и доступ ускорится.
Другое, более общее решение — использование кеширования, при котором данные с диска частично дублируются в памяти. Если какой-то процесс прочитал данные из файла, эти данные некоторое время находятся в памяти, на случай, если они ему (или кому-нибудь другому) опять понадобятся. Повторное обращение уже не дойдёт до диска, система вернёт процессу данные из кеша, раз уж они ничем не отличаются от тех, что на диске. Если процесс записал данные на диск, содержимое кеша обновляется, оставаясь актуальным.
Ещё эффективней кеш на запись: операции записи накапливаются в памяти, а до диска добираются не сразу, и в том порядке, в каком быстрее пройдёт запись, а не в том, в каком были выполнены. Если запись шла во временный файл, который, в конце концов, удалили, обращений к диску может и вообще не случиться. Однако с кешированием операций записи следует обращаться бережно: а вдруг сбой в электроснабжении произойдёт именно тогда, когда часть данных уже записана, а часть — ещё нет? А если не полностью, кусочками, обновилась системная область, состояние файловой системы после того, как питание опять включат, может оказаться совсем плачевным — настолько, что даже умная утилита восстановления fsck может оказаться бессильной. Поэтому системные области либо вообще не кешируются на запись, либо исключительно с помощью будущих кандидатов и докторов наук, что рассчитывают безопасные алгоритмы обновления файловой системы из кеша на запись...
Итак, Linux свободно работает (и даже предпочитает работать) с несколькими разделами диска, содержащими, возможно, разные типы файловых систем.
Из лекции Структура файловой системы Мефодий знает, что файловые системы на различных разделах «прививаются» в виде ветвей общего дерева каталогов, растущего из “/”. Делается это при помощи команды mount -o настройки_монтирования устройство точка_монтирования, где устройство — это имя блочного файла-дырки, точка_монтирования (mountpoint) — полный путь к каталогу, а настройки_монтирования определяют особые параметры, разные для разных файловых систем. После выполнения этой команды содержимое файловой системы, размещённой на устройстве (как правило, дисковом разделе), становится доступным в виде дерева подкаталогов точки_монтирования. Посмотреть список всех смонтированных файловых систем можно с помощью команды mount без параметров:
[root@localhost root]# mount
/dev/hda5 on / type ext3 (rw)
/dev/hda7 on /home type ext3 (rw)
/dev/fd0 on /mnt/floppy type subfs (rw,nosuid,nodev,sync)
/dev/hdc on /mnt/cdrom type subfs (ro,nosuid,nodev)
proc on /proc type proc (rw,gid=19)
devpts on /dev/pts type devpts (rw,gid=5,mode=0620)
[root@localhost root]# umount /home
[root@localhost root]# ls /home
[root@localhost root]# mount /dev/hda7 /home
[root@localhost root]# ls /home
methody shogun tmpuser
Пример 7. Просмотр списка смонтированных файловых систем
Оба Linux-раздела смонтированы при старте системы: /dev/hda5 образует корневую файловую систему, а /dev/hda7 используется для хранения пользовательских домашних каталогов5. Суперпользователь может размонтировать файловую систему вручную с помощью команды umount точка_монтирования, если на ней не открыто никаких файлов и никто не использует какой-либо её каталог в качестве текущего.
Для того, чтобы файловые системы монтировались при загрузке системы, их описывают в файле /etc/fstab:
/dev/hda5 / ext3 defaults 1 1
devpts /dev/pts devpts gid=5,mode=0620 0 0
/dev/hda7 /home ext3 defaults 1 2
proc /proc proc gid=19 0 0
/dev/hda6 swap swap defaults 0 0
/dev/fd0 /mnt/floppy subfs fs=floppyfss,sync,nodev,nosuid
/dev/cdrom /mnt/cdrom subfs fs=cdfss,nodev,nosuid
Пример 8. Содержимое /etc/fstab
Первое поле каждой строки этого файла — устройство или название виртуальной файловой системы, второе — точка монтирования, третье — тип файловой системы, четвёртое — настройки монтирования, а пятое и шестое относятся к организации резервного копирования и процедуре проверки цельности. Содержимое fstab практически повторяет выдачу mount (dev/cdrom на этой машине — ссылка на /dev/hdc). Здесь указывается и область подкачки, которую ядро не монтирует, а использует напрямую. Утилита mount поддерживает усечённый вариант командной строки mount точка_монтирования, при котором она самостоятельно ищет в /etc/fstab, каким способом должна быть смонтирована точка_монтирования. Для того, чтобы при загрузке системы какое-либо устройство не монтировалось, а усечённым mount его можно было смонтировать вручную, в поле «настройки монтирования» добавляется ключевое слово noauto.
Две последних строки относятся к монтированию съёмных (removable) носителей: лазерного и гибкого дисков. Съёмные носители приходится монтировать гораздо чаще несъёмных, не во время загрузки системы, а всякий раз, когда носитель сменился, и содержимое нового необходимо пользователю. Мало того, надо разрешить выполнять операцию mount пользователю, который принёс дискету и желает поработать с ней. С другой стороны, нельзя всем и каждому давать право запускать mount и особенно umount с любыми параметрами! Есть четыре способа разрешить возникающее противоречие:
mount (запись с настройкой noauto в fstab) и утилитой sudo, при помощи которой позволить пользователю выполнять, скажем, только команды mount /cdrom и umount /cdrom.mount и настройкой owner в fstab, которая позволяет выполнять операцию монтирования хозяину устройства; при этом /dev/hdc отдаётся во владение первому зарегистрированному пользователю так же, как /dev/audio и прочие устройства персонального использования. Этот способ лучше предыдущего тем, что исключает ситуацию, когда один пользователь монтирует диск, а другой немедленно его размонтирует.autofs, который отслеживает обращения пользователей к некоторому каталогу (например, /mnt/cdrom/auto), и самостоятельно выполняет операцию mount, а если к содержимому носителя долгое время никто не обращался — umount. Этот способ лучше предыдущего тем, что пользователю вообще никаких дополнительных команд подавать не приходится.subfs), который всегда сообщает программе пользователя, что устройство смонтировано и готово к работе, а с тем, поменялся ли носитель, разбирается самостоятельно. Этот способ лучше предыдущего тем, что пользователю не приходится ждать «долгое время», пока система не соизволит размонтировать и «отдать» лазерный диск. Кроме того, subfs может снабжать пользователя данными из кеша, даже если диск давно уже вынут (речь идёт, разумеется, об операциях чтения).Во всех случаях, когда диск монтирует не системный администратор, стоит предпринять некоторые дополнительные действия. Например, диск должен монтироваться так, чтобы с него не работал запуск с подменой идентификатора (setUID), и чтобы на нём нельзя было создавать файлы-дырки (чтобы не потворствовать хулиганству, вроде запуска setUID-оболочки или записи прямо в устройство, соответствующее hda). За это отвечают настройки nosuid и nodev, упомянутые в /etc/fstab.
Кроме того, лазерные приводы имеют «защёлку», не позволяющую извлечь диск, пока он используется, а дисководы или устройства USB Flash — нет (хотя, казалось бы, она нужнее там, где происходит запись). Единственная надежда — на то, что пользователь не будет выдёргивать дискету из дисковода, пока он занимается записью, и на нём горит зелёная лампочка. Чтобы каждая операция записи немедленно приводила к передаче данных, необходимо полностью отключить кеш записи, то есть использовать синхронный режим работы файловой системы. Это делается при помощи настройки sync.
Если бы на компьютере из примера использовался способ монтирования лазерного диска 1 или 2, то в поле «тип» fstab было бы написано iso9660. Так называется тип файловой системы, обычно используемой на лазерных дисках. Что же касается жёстких дисков, то на них может использоваться несколько типов файловых систем, даже на одном Linux-компьютере.
Основная файловая система в Linux называется «Ext2». Имя происходит от слова «extended» (расширенная) и появилось после того, как самая первая версия файловой системы ранних Linux, повторяющая возможности одного из вариантов файловой системы UNIX, окончательно устарела. Пришлось переписать соответствующую часть ядра, расширив уже имеющиеся возможности. Так появилась «ExtFS». Когда и она устарела, возможности снова расширили, и к названию добавилось число «2». Повсеместно используемая в дистрибутивах Linux файловая система «Ext3» — «трижды расширенная»! — отличается от Ext2 поддержкой журнализации.
Журналируемая файловая система ведёт постоянный учёт всех операций записи на диск. Получающийся журнал обращений сам, в свою очередь, записывается на диск. Разница между записью журнала и записью самих данных в том, что данные следует записывать в строго определённое место, а журнал устроен так, чтобы записываться как можно быстрее. Выгода от такой двухступенчатой процедуры особенно остро ощущается после сбоя электропитания: все операции, записи, которые ещё не успели завершиться, записаны в журнале, так что стоит после включения компьютера «проиграть» их ещё раз, и файловая система войдёт в норму! Если часть данных уже была записана на диск, повторная (по требованию журнала) запись тех же самых данных на то же самое место ничем повредить не может. Наконец, если операция записи не попала даже в журнал (что бывает редко), то файловая система всё равно останется в рабочем состоянии, каким оно было до начала этой операции.
Журналирование поддерживается и другими файловыми системами, используемыми в Linux — XFS и ReiserFS. ReiserFS вообще похожа скорее на базу данных: внутри неё используется своя собственная система индексации и быстрого поиска данных, а индексные дескрипторы и каталоги в стиле Linux выполнены в виде одной из возможных надстроек над этой системой. Традиционно считается, что ReiserFS отлично подходит для хранения огромного числа маленьких файлов (что было одной из целей проекта), а XFS — для хранения очень больших файлов, в которых постоянно что-нибудь дописывается или изменяется.
В Linux поддерживается, кроме собственных, немало форматов файловых систем, используемых другими ОС. Если способ записи на эти файловые системы известен и не слишком замысловат, то работает и запись, и чтение, в противном случае — только чтение (чего нередко бывает достаточно). Полностью поддерживаются файловые системы FAT12/FAT16/FAT32 (тип vfat), используемые в MS-DOS и Windows, ранние версии UFS, используемые в системах семейства BSD. Новые версии UFS (например, UFS2 из FreeBSD5, обладающая свойствами, которые не входят в стандарт Linux) поддерживаются только на чтение, как и созданная на основе DEC VMS, но впоследствии многократно переработанная файловая система NTFS из Windows.
Для того, чтобы смонтировать файловую систему, имеющую заданный тип, команде mount необходимо указать его с помощью ключа “-t”:
[root@localhost root]# fdisk -l
. . .
Device Boot Start End Blocks Id System
/dev/hda1 * 1 25 100768+ 6 FAT16
/dev/hda2 26 520 1995840 5 Extended
/dev/hda5 26 282 1036192+ 83 Linux
/dev/hda6 283 334 209632+ 82 Linux swap
/dev/hda7 335 520 749920+ 83 Linux
[root@localhost root]# mount -t vfat /dev/hda1 /mnt/disk
[root@localhost root]# ls /mnt/disk
autoexec.bat config.sys fdconfig.sys freedos.bss
command.com fdconfig.old fdos kernel.sys
Пример 9. Монтирование файловой системы FAT16
В /etc/fstab Мефодий сразу заметил две строки, начинающиеся не с имени устройства, а с названия виртуальной файловой системы, содержимое которой доступно в соответствующей точке монтирования. Виртуальная файловая система обычно не обращается ни к какому внешнему устройству, а «придумывает» всё дерево каталогов и находящиеся в них файлы сама. Такова, например, файловая система в памяти (ROMFS, или аналогичная ей TMPFS, поддерживающая операции записи), используемая в стартовом виртуальном диске. Как правило, виртуальные файловые системы используются для того, чтобы предоставить доступ по чтению/записи к некоторой иерархической структуре данных.
Во многих версиях UNIX программа ps работает непосредственно с устройством /dev/kmem (памятью ядра), чтобы добыть оттуда информацию о таблицах процессов; это — сложная и даже опасная программа, имеющая доступ к святая святых системы. В Linux ps может быть переписана чуть ли что не на shell, потому что таблица процессов и масса другой информации о системе доступны в виде дерева подкаталогов /proc:
[root@localhost root]# ls -F /proc
1/ 585/ 793/ 882/ es1371 irq/ modules stat
1041/ 598/ 794/ acpi/ execdomains kcore mounts@ swaps
16/ 6/ 795/ bus/ fb kmsg mtrr sys/
2/ 681/ 796/ cmdline filesystems ksyms net/ sysrq-trigger
3/ 697/ 797/ cpufreq fs/ loadavg partitions sysvipc/
4/ 7/ 798/ cpuinfo ide/ locks pci tty/
492/ 725/ 8/ devices interrupts mdstat scsi/ uptime
5/ 751/ 840/ dma iomem meminfo self@ version
572/ 784/ 844/ driver/ ioports misc slabinfo
[root@localhost root]# ls -l /proc/1
total 0
-r--r--r-- 1 root proc 0 Dec 4 16:15 cmdline
lrwxrwxrwx 1 root proc 0 Dec 4 16:15 cwd -> /
-r-------- 1 root proc 0 Dec 4 16:15 environ
lrwxrwxrwx 1 root proc 0 Dec 4 16:15 exe -> /sbin/init
dr-x------ 2 root proc 0 Dec 4 16:15 fd
-r--r--r-- 1 root proc 0 Dec 4 16:15 maps
-rw------- 1 root proc 0 Dec 4 16:15 mem
-r--r--r-- 1 root proc 0 Dec 4 16:15 mounts
lrwxrwxrwx 1 root proc 0 Dec 4 16:15 root -> /
-r--r--r-- 1 root proc 0 Dec 4 16:15 stat
-r--r--r-- 1 root proc 0 Dec 4 16:15 statm
-r--r--r-- 1 root proc 0 Dec 4 16:15 status
[root@localhost root]# cat /proc/1/environ ; echo
OME=/TERM=linux
Пример 10. Виртуальная файловая система PROCFS
В частности, подкаталоги /proc с числовыми именами содержат информацию о процессах с соответствующими PID. Файл exe такого подкаталога — символьная ссылка на запущенную программу, файл cmdline содержит командную строку, а environ — окружение процесса. Мефодий углубился в чтение man proc, руководства по PROCFS, и, как всегда, убедился, что для полного понимания всего, что есть в /proc, ему пока не хватает знаний.
Файловая система devpts — шаг навстречу динамическому именованию устройств. Она предназначена для эмуляторов терминала, таких как sshd, xterm или screen. Задача эмулятора терминала — предоставить пользователю полноценный интерфейс командной строки (с запуском командного интерпретатора, с распознаванием и передачей сигналов и т. п.) в отсутствие терминального оборудования — по сети или из графической подсистемы, или при необходимости сымитировать несколько терминалов. Раньше для этого использовались пары устройств /dev/pty## — /dev/tty##, где ## — двухсимвольный идентификатор. Программа-эмулятор начинала обмениваться данными (от пользователя или из сети) с первым свободным устройством (скажем, ptya2, которое, в свою очередь, было привязано к соответствующему терминальному устройству (ttya2). Именно с этим устройством и взаимодействовал командный интерпретатор и прочие процессы Linux, находясь в полной уверенности, что это — полноценный терминал.
Выходило, что пар tty##-pty## при статическом именовании устройств могло не хватить, даже если создать их очень много (достаточно запустить ещё больше эмуляторов терминала). Поэтому придумали завести одно устройство типа pty — /dev/ptmx и виртуальную файловую систему /dev/pts для терминальных файл-дырок. Каждая программа, открывающая ptmx, получает свой дескриптор), а в pts/ заводится очередное терминальное устройство, имя которого совпадает с порядковым номером. Когда дескриптор закрывается, терминальное устройство исчезает.
Среди файловых систем есть и такие, что не выдумывают содержимое сами, а обращаются за ним ещё куда-нибудь, например, в сеть. Так работают удалённые файловые системы, например, NFS (network file system), стандартная для всех UNIX-подобных ОС. Вместо поля «устройство» обычно указывается сетевой адрес компьютера-сервера и имя ресурса (название каталога), который необходимо смонтировать по сети. Поддерживается и работа с удалёнными файловыми системами Windows, причём как на уровне модулей ядра, с помощью mount -t smbfs), так и без монтирования, с помощью утилиты smbclient. Linux и сам может служить сервером, предоставляющим удалённый доступ к файлам, причём служба samba, занимающаяся файловыми системами для Windows под управлением Linux, работает зачастую быстрее, чем Windows, запущенный на том же компьютере для тех же целей.
Возможности файловых систем этим не исчерпываются! Например, можно смонтировать образ устройства из файла, если вызвать команду mount с ключом -o loop. Образ устройства — это файл, содержимое которого в точности повторяет содержимое устройства; его можно, например, получить с помощью команды cat устройство образ. Именно образами устройств манипулируют программы записи на лазерные носители. Смонтировать образ бывает нужно для проверки или изменения содержимого перед записью, или для хранения содержимого нескольких дисков в исходном виде:
[root@localhost root]# ls -l floppy.flp
-rw-r--r-- 1 root root 1474560 Dec 4 16:53 floppy.flp
[root@localhost root]# mount -t vfat -o loop floppy.flp /mnt/disk/
[root@localhost root]# ls /mnt/disk/
command.com kernel.sys
[root@localhost root]# mount | grep disk
/root/floppy.flp on /mnt/disk type vfat (rw,loop=/dev/loop0)
Пример 11. Монтирование содержимого файла при помощи mount -o loop
Как заметил Мефодий, mount создаёт для такого способа монтирования специальное устройство — /dev/loop0, и уже с его помощью работает с файлом.
Обширное поле для экспериментов — т. н. пользовательская файловая система (linux userland file system, LUFS). Это — модуль ядра и набор библиотек, позволяющий организовать файловую систему, обращающуюся за информацией к обычному процессу Linux. Так организованы разнообразные сетевые «эмуляторы» файловых систем с использованием протокола FTP или Secure Shell. Так работает и доступ на запись к файловой системе NTFS: некоторая программа обращается к устройству, содержащему файловую систему, задействует драйвер NTFS, взятый из лицензионной копии самой Windows (это можно сделать с помощью библиотек wine, подсистемы, распознающей исполняемые форматы Windows), и обменивается данными с модулем LUFS, который и предоставляет обычный файловый доступ процессам.
Если доступная на запись файловая система не была размонтирована перед выключением компьютера, после включения она окажется в нештатном состоянии, независимо от того, испортилось на ней что-либо или нет. Проверкой цельности файловой системы занимается утилита fsck (file system check). На самом деле таких утилит несколько — по одной для каждого из основных типов файловых систем (есть fsck даже для VFAT). Как уже говорилось в лекции Этапы загрузки системы, fsck запускается при старте Linux, если файловая система находится в нештатном состоянии, или для профилактики, если файловую систему просто давно не проверяли.
В самом лучшем случае fsck не находит ничего подозрительного, и система продолжает загрузку. Чаще всего, даже если в файловой системе не всё в порядке, её журнал не испорчен, и fsck «проигрывает» его, после чего всё опять приходит в норму. Запустить fsck можно и вручную, в виде fsck устройство или fsck точка_монтирования, однако прежде следует размонтировать файловую систему:
[root@localhost root]# fsck -fy /home
fsck 1.35 (28-Feb-2004)
/dev/hda7 is mounted.
WARNING!!! Running e2fsck on a mounted filesystem may cause
SEVERE filesystem damage.
Do you really want to continue (y/n)? no
check aborted.
[root@localhost root]# umount /home
[root@localhost root]# fsck /home
fsck 1.35 (28-Feb-2004)
e2fsck 1.35 (28-Feb-2004)
/dev/hda7: clean, 168/93888 files, 7269/187480 blocks
[root@localhost root]# fsck -f /home
fsck 1.35 (28-Feb-2004)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/hda7: 168/93888 files (0.6% non-contiguous), 7269/187480 blocks
Пример 12. Использование fsck
Со второго раза fsck6 работать тоже не захотела, ссылаясь на то, что файловая система и так находится в штатном состоянии (её аккуратно размонтировали). Пришлось применить ключ “-f” (force), который заставляет fsck работать — конечно же, никаких ошибок найдено не было. Сама процедура проверки довольно сложна, она состоит из пяти этапов, каждый из которых отнюдь не тривиален, и в этой лекции не описывается. Кстати сказать, для того, чтобы проверить корневую файловую систему, её приходится сначала монтировать только на чтение, находить там /sbin/fsck, проверять, и только после этого монтировать на чтение-запись. Если корневая файловая система испорчена настолько, что /sbin/fsck в ней найти невозможно, остаётся пробовать загрузку с других носителей (например, с установочного CD), и разбираться.
Если какая-то порча файловой системы всё-таки обнаружилась, fsck может поступить двояко. Во-первых, все ошибки, которые не приводят к изменению данных на диске, можно попробовать исправить автоматически. Например, индексные дескрипторы, на которые не ссылается ни одно имя (т. н. потерянные файлы, unref files), помещаются в специальный каталог /lost+found под именами, соответствующими номерам этих индексных дескрипторов. Впоследствии администратор может посмотреть в эти файлы и решить, нужны они или нет. Во-вторых, когда fsck встречается с ошибкой, исправление которой приведёт к изменению данных на диске, загрузка Linux останавливается, и система переходит в однопользовательский режим. Предполагается, что администратор сам запустит fsck: либо интерактивно, тогда каждому изменению в файловой системе будет требоваться подтверждение с клавиатуры, либо пакетно, с ключом “-y”, тогда считается, что на все такие запросы администратор заранее ответил «yes».
Когда-то такие вот запуски fsck -y производили катастрофические разрушения по вине неумелых администраторов, а нынче Мефодий, как ни нажимал «Reset» на многострадальной двухсистемной машине, не смог добиться ничего, кроме двух-трёх мгновенных воспроизведений журнала и жестокого нагоняя от Гуревича.
1Если стандартный вывод ошибок всего конвейера перенаправлен в /dev/null, то командный интерпретатор не выводит сообщений о запуске и остановке фонового процесса.
2Что называется, «кто первым встал — того и тапки».
3Для некоторых других файловых систем, например, для vfat, это неверно.
4Такая ситуация называется «дребезг» (trashing) и свидетельствует о том, что для текущих задач компьютеру требуется больше физической памяти.
5Мефодий заметил, что /tmp и /var не смонтированы никуда, и, следовательно, корневая файловая система, вопреки рекомендациям FHS, слишком часто используется на запись.
6Мефодий заметил, что для файловой системы Ext3 запустилась специализированная версия e2fsck, подходящая также и для Ext2.